 语义分割在三元组关系抽取中的作用是什么?
语义分割在三元组关系抽取中的作用是什么?
1. 总述
关系抽取(Relation Extraction, RE)是从纯文本中提取未知关系事实,是自然语言处理领域非常重要的一项任务。过去的关系抽取方法主要将注意力集中于抽取单个实体对在某个句子内反映的关系,然而单句关系抽取在实践中受到不可避免的限制:在真实场景如医疗、金融文档中,有许多关系事实是蕴含在文档中不同句子的实体对中的,且文档中的多个实体之间,往往存在复杂的相互关系。如下图所示:
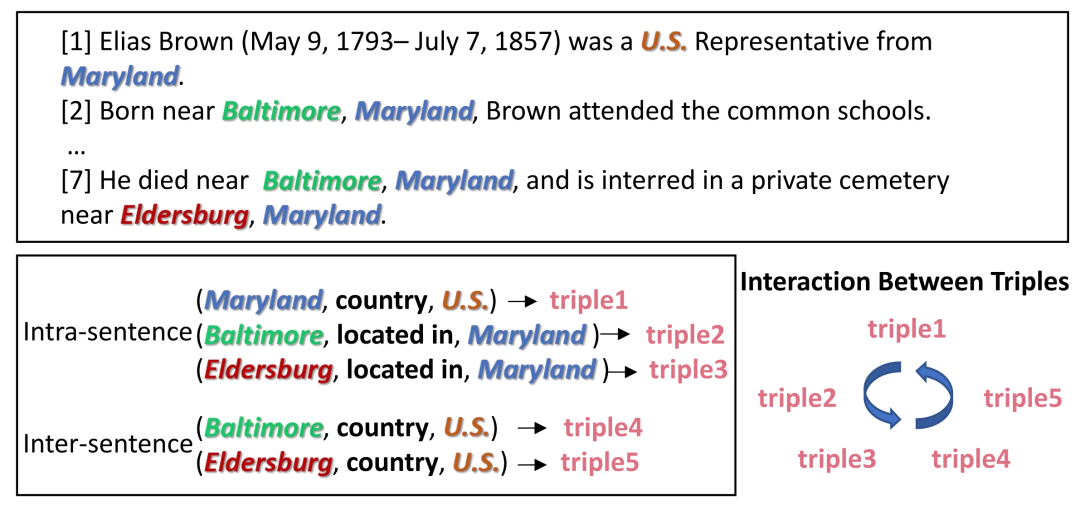
图中包括了文章中的三个关系事实(从文档标注的诸多关系事实中采样得到),其中涉及这些关系事实的命名实体用彩色着色,其它命名实体用下划线标出。与句子级相比,文档级关系抽取中的文本要长得多,并且包含更多的实体, 这使得文档级关系抽取更加困难。其中(Maryland, country, US)、(Baltimore, located_in, Maryland) 和 (Eldersburg, located_in, Maryland)三组triples中的实体在同一个句子中的出现,这种句内关系相对容易识别。然而,跨句实体之间的关系识别更具挑战性, 例如,关系事实(Baltimore,country,U.S.)和(Eldersburg,country,U.S.)中的相关实体并没有出现在同一个句子中并且需要长距离依赖, 具体来说,多个三元组之间的相互依赖是有利的,可以为实体多的情况下的关系分类提供指导。例如,如果句内关系 (Maryland, country, US) 已被识别,则{US} 不可能处于任何 person-social 关系中,例如"is the father of." 此外,根据{Eldersburg} 位于{Maryland} 和{Maryland} 属于{US} 的三元组,我们可以推断{Eldersburg} 属于{US} . 如上所述,每个关系三元组可以向同一文本中的其他关系三元组提供信息。
文档级关系抽取主要面临以下三个挑战:
1.相同关系会出现在多个句子。在文档级关系抽取中,单一关系可能出现在多个输入的句子中,因此模型需要依赖多个句子进行关系推断。
2.相同实体会具有多个指称。在复杂的文档中,同一个实体具有各种各样的指称,因此模型需要聚合不同的指称学习实体表示。
3.不同三元组之间需要信息交互。文档包含多个实体关系三元组,不同的实体关系三元组之间存在逻辑关联,因此模型需要捕捉同一篇文档中三元组之间的信息交互。
然而先前的基于graph或基于transformer的模型仅单独地使用实体对,而未考虑关系三元组之间的全局信息。本文创新性地提出DocuNet模型,首次将文档级关系抽取任务类比于计算机视觉中的语义分割任务。DocuNet模型利用编码器模块捕获实体的上下文信息,并采用U-shaped分割模块在image-style特征图上捕获三元组之间的全局相互依赖性,通过预测实体级关系矩阵来捕获local和global信息以增强文档级关系抽取。实验结果表明,我们的方法可以在三个基准数据集DocRED,CDR和GDA上获得SOTA性能。
2.方法
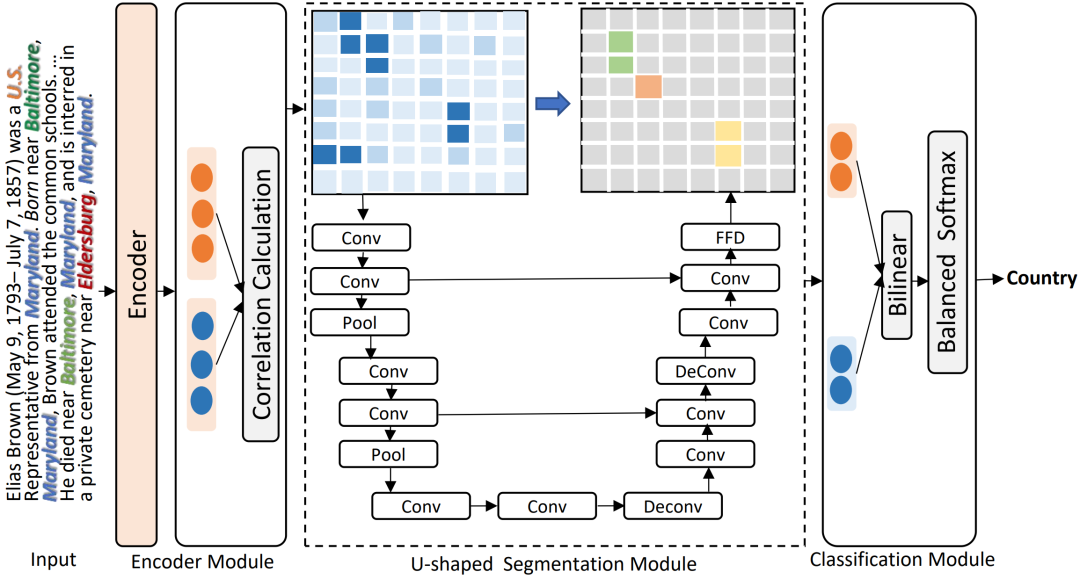
具体来说,DocuNet模型分为三个模块:
(1)Encoder Module
我们将triple抽取视为sequence-to-sequence的任务,以更好地对实体和关系之间的交叉依赖进行建模。我们将输入文本和输出三元组定义为源和目标序列。源序列仅由输入句子的标记组成,例如“[CLS] The United States President Trump was raised in the borough of Queens ...[SEP]”。我们连接由特殊标记 ”< e >” 和 ”< /e >”分隔的每个实体/关系的三元组作为目标序列。
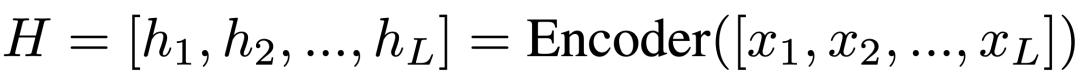
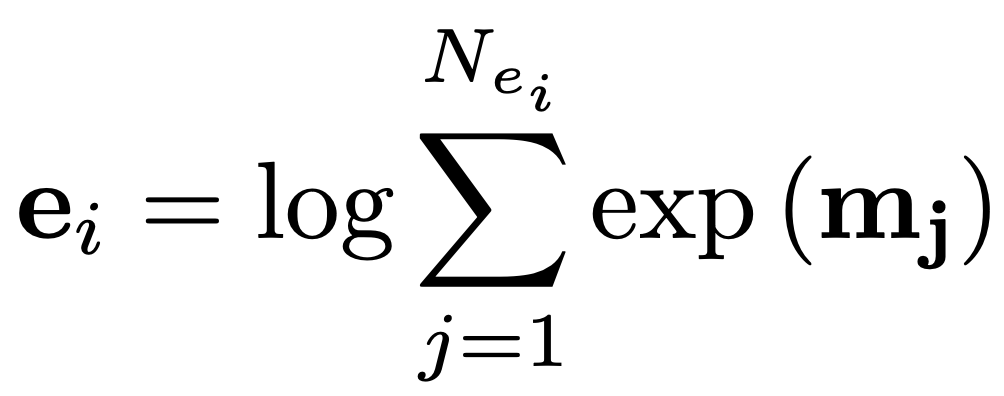
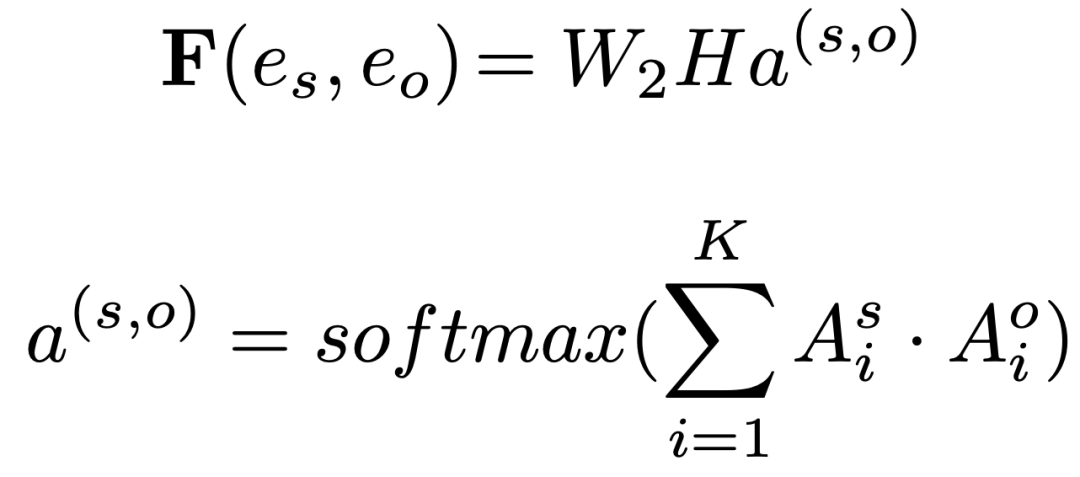
其中是实体感知注意力的注意力权重,对于矩阵中的每个实体,它们的相关性由一维特征向量捕获。
(2)U-shaped Segmentation Module
三元组之间存在局部语义依赖,语义分割中的CNN可以促进感受野中实体对之间的局部信息交换。文档级RE还需要全局信息来推断三元组之间的关系,语义分割模块中的下采样和上采样可以扩大当前实体pair对嵌入的感受野,能够增强全局隐式推理:
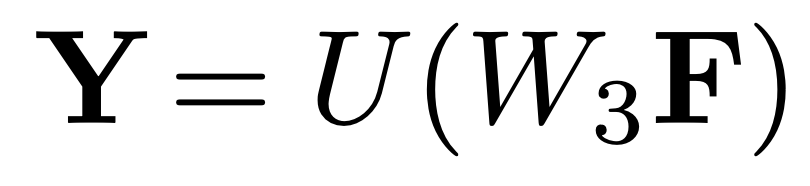
我们把实体级关系矩阵作为D-channel图像,我们将文档级关系预测公式化为像素级掩码, 其中N是从所有数据集样本中统计出的最大实体数。
(3)Classification Module
给定实体pair的特征表示和实体级关系矩阵Y,我们使用前馈神经网络将它们映射到隐藏表示z。然后,我们通过双线性函数获得实体pair之间关系预测的概率表示如下:
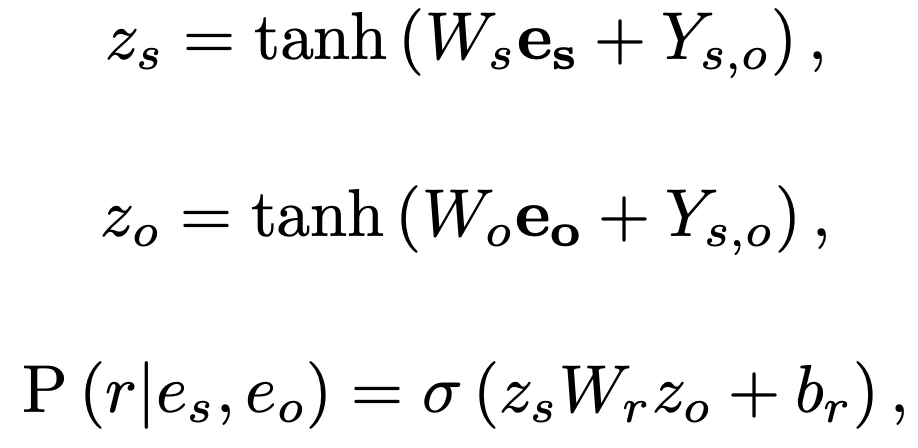
由于观察到 RE 存在不平衡关系分布(许多实体对具有 NA 的关系),我们引入了一种平衡的 softmax 方法进行训练:
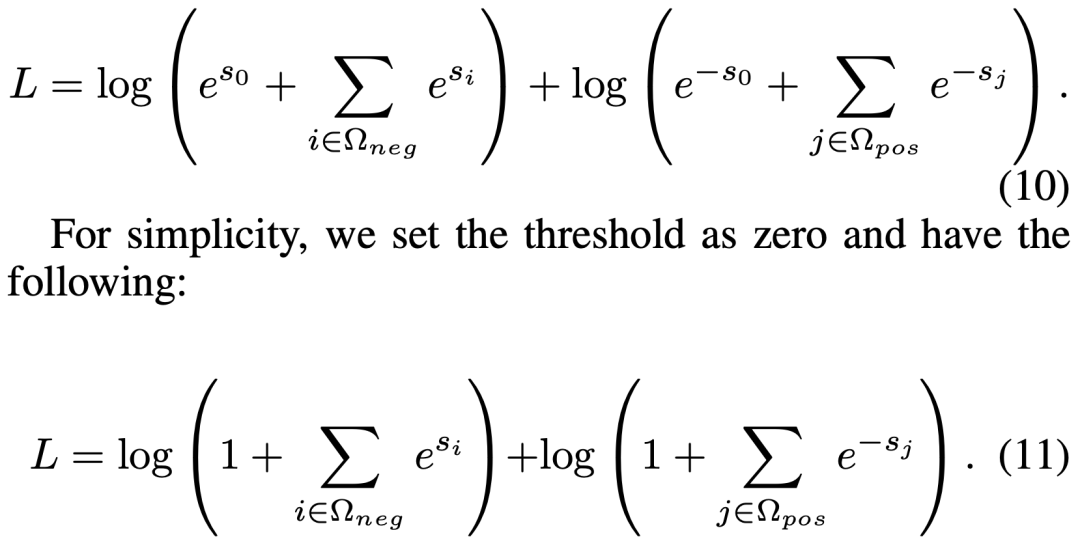
3. 实验
(1)数据集
为了验证DocuNet的效果,我们在三个文档级关系抽取数据集上评测,数据集具体分析如下所示:
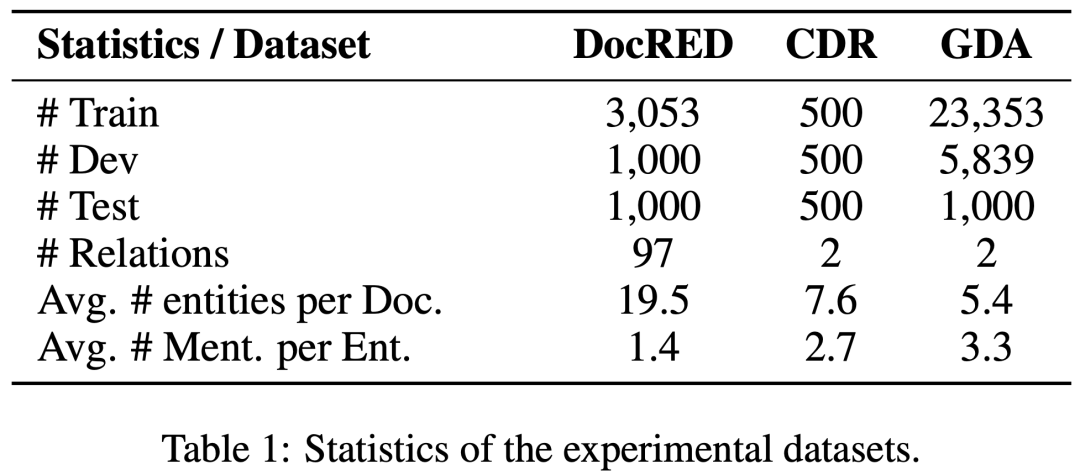
(2)实验结果
由下面实验结果表明,DocuNet比以往的文档级关系抽取方法效果更佳。
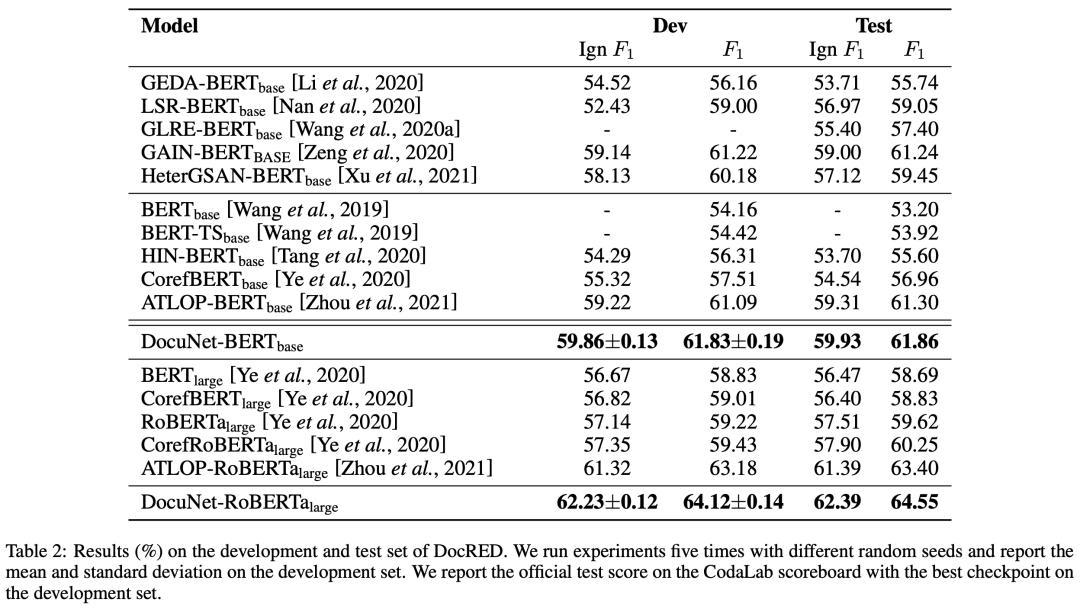
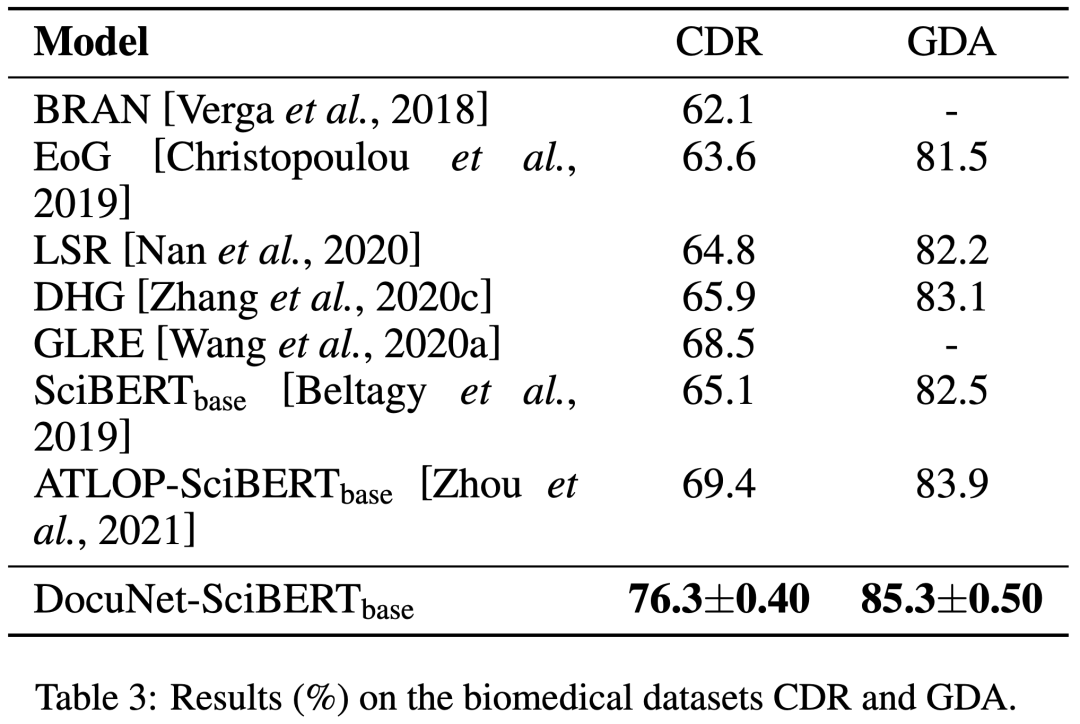
4. 总结与展望
在本文中,我们把文档级关系抽取任务看作语义分割来求解,直接给出了如何将 UNet 应用于文档级 RE 的解决方案,实验结果表明U-shaped模块能有效得理解局部上下文和全局相互依赖性。目前结果表明U-shaped模块中的卷积学习了 RE 三元组之间的相互作用,但仍U-shaped模块的推理作用尚是隐式的,未来对U-shaped模块进一步的可视化分析有助于我们加强理解其是如何做三元组之间推理的。我们的方法证实了语义分割模块在处理RE中有效性,仍需要更多的工作去探索U-shaped模块在如aspect-based sentiment analysis等其他nlp任务上的应用。
-
语义
+关注
关注
0文章
21浏览量
8659 -
文本
+关注
关注
0文章
118浏览量
17085
原文标题:【IJCAI2021】长文本知识抽取:基于语义分割的文档级三元组关系抽取
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
三元锂电生命循环究竟是多长?朗凯威锂电电池定制 三元锂电池组DIY
朗凯威三元锂电池组 6020:高性能能源解决方案

三元锂电池行业发展趋势
三元锂电池放电特性及应用
三元锂电池实际应用中的缺点
三元锂电池的组成与功能
鸿蒙原生应用元服务开发-仓颉基础数据类型元组类型

图像语义分割的实用性是什么
图像分割与语义分割中的CNN模型综述
软包三元锂电池能和硬包三元锂电池能混合用吗
三元锂离子电池优缺点分析






 工商网监
工商网监
评论