 应用深度学习分析提高基因组分析的准确性
应用深度学习分析提高基因组分析的准确性
发布人:Google Health Genomics 产品负责人 Andrew Carroll 和 Genomics 项目经理 Howard Yang
Google Health 的 Genomics 团队很高兴分享我们对 DeepVariant 的最新扩展 - DeepTrio。
DeepVariant 于 2017 年首次发布,是一种开源工具,支持研究人员和临床医生分析个人的基因组测序数据并识别基因变异,如可导致疾病的变异片段。我们在 DeepVariant 方面的持续研究因其一流的准确性而获得肯定。借助 DeepTrio,我们扩展了 DeepVariant,从而能够在分析母亲-父亲-子女三人的基因序列数据时考量基因变异。
人类是二倍体生物,携带人类基因组的两个副本。每个个体都分别继承了来自母亲和父亲的一个基因组副本。父母遗传信息有助于分析符合孟德尔遗传规律的特征和疾病。DeepTrio 学习直接在测序数据中使用孟德尔遗传的特性,以便在可以共同分析父母和子女样本的情况下更准确地识别基因变异。
修改 DeepVariant 以分析三人样本
DeepVariant 学习到如何将基因组中的位置分类为参考或者“基因组浏览器”(相关专家用于分析的工具)中数据表示的变种。“《使用 DeepVariant1.0 提高基因组分析的准确性》(Improving the Accuracy of Genomic Analysis with DeepVariant 1.0)”一文很好地概述了有关内容。
使用 DeepVariant1.0 提高基因组分析的准确性
https://ai.googleblog.com/2020/09/improving-accuracy-of-genomic-analysis.html
DeepVariant 接收数据作为以候选变异为中心的基因组窗口,并且按照要求将数据分类为参考(无变异)、杂合子(变异的一个副本)或纯合子(两个副本均为变异)。DeepVariant 将序列证据视为代表数据特征的通道(请参阅“《透过 DeepVariant 深入观察》(Looking through DeepVariant’s eyes)”获取更深入解释)。
透过 DeepVariant 深入观察
我们修改了 DeepTrio,以在单个图像中表示来自三人的序列数据,其中每个样本的高度固定,子女的数据置于中间。我们使用来自美国国家标准与威廉希尔官方网站 研究院 (NIST) 瓶中基因组联盟 (GIAB) 的黄金标准样本作为真实标签,训练一个模型调用子女样本中的变异,并训练另一个模型调用顶部父母样本中的变异。为调用父母双方的样本,我们翻转父母样本的位置。
衡量 DeepTrio 提高的准确性
我们研究发现,对于父母和子女变异检测,DeepTrio 比 DeepVariant 更准确,在覆盖率较低的情况下具有特别明显的优势。这使研究人员能够以更高的准确性分析样本,或者在显著降低费用的同时保持相当的准确性。
为评估 DeepTrio 的准确性,我们借助 NIST 瓶中基因组联盟提供的涵盖广泛特征的黄金标准,将其与 DeepVariant 的准确性进行比较。为获得在训练中从未见过的评估数据集,我们在训练中排除了 20 号染色体,并对 20 号染色体进行了评估。
我们训练 DeepVariant 和 DeepTrio,以对来自两种不同仪器 Illumina 和 Pacific Biosciences (PacBio) 的数据进行测序。如要详细了解这些威廉希尔官方网站 之间的差异,请参见我们之前的博客。这些测序仪均以容易错误的方式随机采样基因组。为准确分析基因组,我们需要重复采样相同区域。在某个位置的采样深度称为覆盖范围。以近似线性的方式测序来覆盖更大的范围将导致成本更高。因此我们经常需要在成本、准确性和测序样本之间进行权衡。而权衡的结果是,在三人样本中,父母样本通常以较低的深度进行测序。
在下方图表中,我们绘制了一系列不同覆盖范围中 DeepTrio 和 DeepVariant 的准确性。
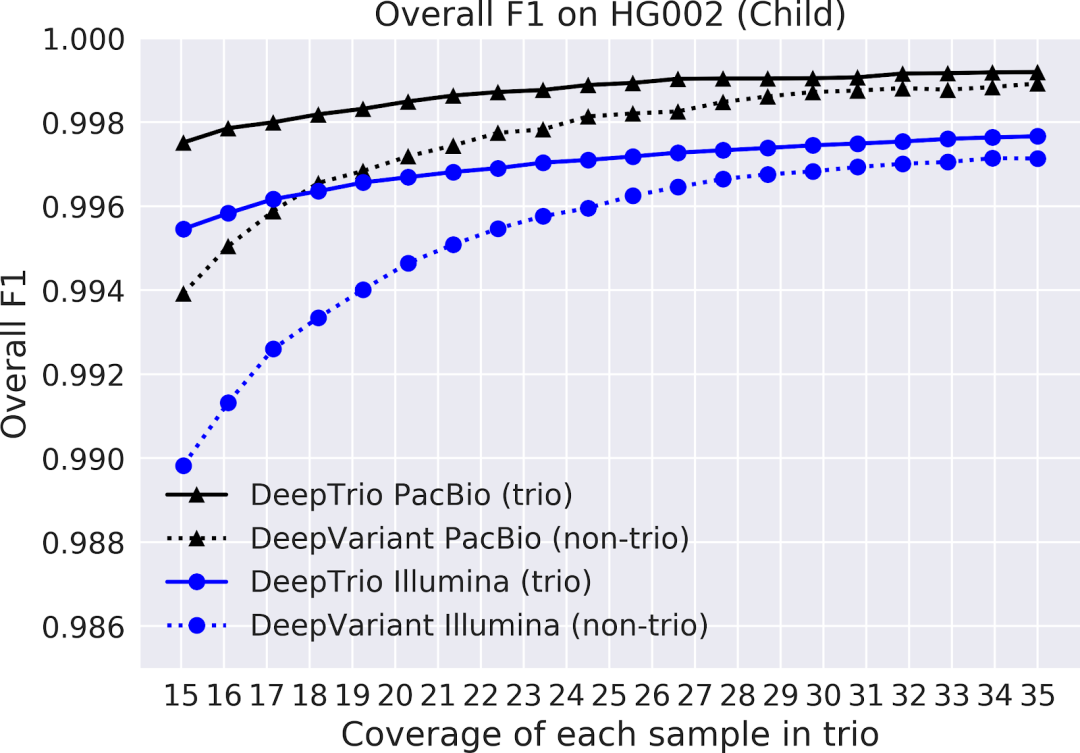
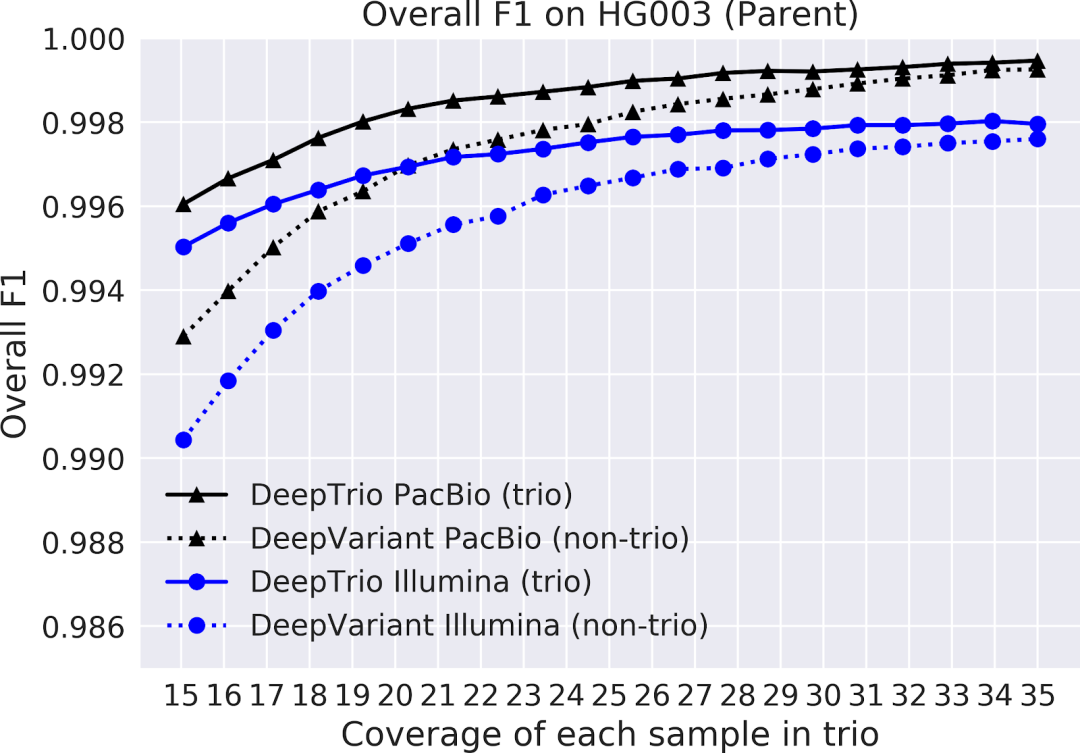
图 2.子女样本(顶部)和父母样本(底部)上 DeepTrio(实线)和 DeepVariant(虚线)的 F1 得分,使用 Illumina(蓝色)和 PacBio(黑色)仪器进行测序。在具有一系列测序覆盖范围(x 轴)的样本中,对 20 号染色体上所有类型的小变异进行 F1 测量
DeepTrio 在 de novo 变异上的表现
相对于人类参考基因组,每个人大约有 500 万处变异,其中绝大多数从父母处继承而来。一小部分(大约 100 处)是新变异(称为 de novo),由 DNA 复制过程中的复制错误导致。我们的研究证明,DeepTrio 大大减少了 de novo 变异检测的假阳性情况。对于 Illumina 数据,其真阳性回收率的下降幅度较小,而对于 PacBio 数据,这种权衡不会发生。
为评估准确性,我们分析了父母两人都被称为非变异但子女被称为杂合变异的位点。我们观察到 DeepTrio 更不愿意将变异命名为 de novo,这类似于人类对于违反孟德尔遗传规律的位点,需要获得更高水平的证据。因此,此类 de novo 变异的假阳性率低得多,但 DeepTrio Illumina 的召回率则略低。通常,在发生这种情况时,子女的样本仍将称作变异,但父母样本则给予“不调用”的判断(分类器没有足够的信心进行调用)。
促进罕见病研究
通过将 DeepTrio 作为开源软件发布,我们希望这一软件能够支持科学家更准确地分析样本,进而提升对基因组数据的分析能力。我们希望这能促进研究和临床开发,进而更好地解析罕见病病例,并改进治疗方法的开发。
除了将 DeepTrio 的代码作为开放源代码发布之外,我们还发布了为训练这些模型而生成的测序数据。这些数据会在预印本“《用于基准测试和开发的黄金标准样本的广泛序列数据集》(An Extensive Sequence Dataset of Gold-Standard Samples for Benchmarking and Development)”中加以说明。通过发布该生产模型和训练相似复杂度模型所需的数据,我们希望能为基因组学界的方法开发做出贡献。
原文标题:应用深度学习分析家庭基因组数据
文章出处:【微信公众号:TensorFlow】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
开源
+关注
关注
3文章
3333浏览量
42481 -
深度学习
+关注
关注
73文章
5503浏览量
121131
原文标题:应用深度学习分析家庭基因组数据
文章出处:【微信号:tensorflowers,微信公众号:Tensorflowers】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
如何提升ASR模型的准确性
GPU深度学习应用案例
如何评估 ChatGPT 输出内容的准确性
如何保证测长机测量的准确性?

AI大模型与深度学习的关系
【飞凌嵌入式OK3576-C开发板体验】RKNPU图像识别测试
HPLC数据怎么分析处理
影响电源纹波测试准确性的因素

深度学习模型训练过程详解
12芯M16插头数据传输准确性怎样

8芯M16插头数据传输的准确性

测量时钟信号的探头要求:确保准确性与稳定性
电流探头测试小技巧:提高准确性和安全性

FLOEFD T3STER自动校准模块—提高电子产品散热设计的准确性






 工商网监
工商网监
评论