 如何使用SLX FPGA优化人脸检测数据中心的OpenCL AI内核?
如何使用SLX FPGA优化人脸检测数据中心的OpenCL AI内核?
本案例介绍了如何使用Silexica的SLX FPGA优化人脸检测数据中心的OpenCL AI内核。
引言
FPGA正越来越多地被用作数据中心的协处理器。这一转变背后的驱动力是利用FPGA的并行特性的AI应用。Xilinx Alveo系列加速器卡使用PCI Express接口连接到x86处理器,在这个领域非常流行。对于这些加速器卡的编程,你可以使用自上而下的方法,从顶级的C/C++和OpenCL应用程序开始,然后向低级别的内核工作,或者使用自下而上的方法,将内核块编译成Xilinx对象(.xo),然后可以在以后的阶段连接成二进制。
与自顶向下的流相比,自底向上的流程有几个优点。(1) 它允许将内核的设计、验证和优化与主应用程序分开。(2) 它通过将设计分割成更小的组件,为内核的开发和优化提供更快的迭代周期。(3) 它有利于重复使用;一个(.xo)文件的集合可以像库一样被重复使用。
在本应用案例中,我们使用人脸检测应用作为参考设计,展示设计者在使用Vitis自下而上流程时,如何使用SLX FPGA来优化内核。请注意,同样的方法也适用于从头开始设计内核或从Vitis HLS导入现有内核。
开发流程
创建该应用需要使用Silexica和Xilinx的以下开发工具。
● SLX FPGA版本2020.4-sp1● VitisLibraries 2020.2版● Vitis高级合成2020.2版
● Vitis统一软件平台2020.2版
整个端到端流程如图1所示。该流程从创建一个新的SLX项目开始。但是,如果您有一个现有的Vitis HLS项目,SLX FPGA可以直接导入它。

图1:Vitis自底向上项目的SLX FPGA工作流程
一、创建并配置SLX FPGA项目
 启动SLX FPGA,点击“New SLX project”图标,启动项目创建向导。创建一个新的SLX FPGA项目,如图2所示。下一步是配置这个项目。
启动SLX FPGA,点击“New SLX project”图标,启动项目创建向导。创建一个新的SLX FPGA项目,如图2所示。下一步是配置这个项目。
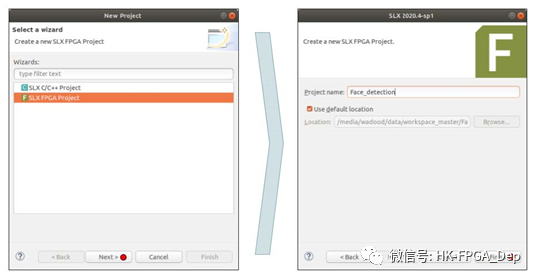
图2:创建一个新的SLX FPGA项目
当你创建一个新的项目时,配置编辑器会自动出现,但你也可以通过点击橙色的齿轮按钮随时调出它。如图3所示,将你的应用程序源文件拖放到项目的spec文件夹中。在本案例中,我们从Rosette基准1中抽取人脸检测应用。接下来,你需要指定FPGA部件号和构建选项。对于这个应用,我们的目标是Alveo U280 FPGA。在FPGA部件栏,选择xcu280-fsvh2892-2L-e。要设置构建选项,输入clean、build和run命令,如图3所示。对于‘make’项目,如图,请确认makefile没有使用硬编码编译器,而是使用(CC)和(CXX)环境变量来分别引用C和C++编译器。SLX将在不同的分析阶段用其专有的编译器覆盖这些变量。Run命令执行testbench(也包括在基准套件中),以确保功能的正确性,也用于分析应用程序的动态行为。
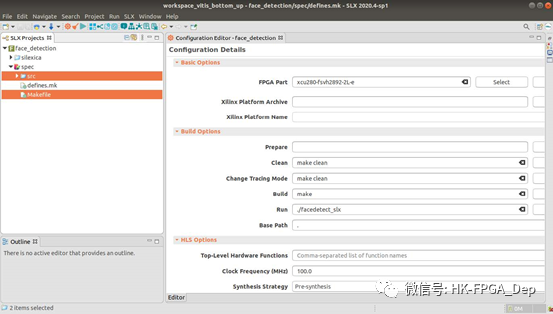
图3:配置一个新的SLX FPGA项目
这些基本配置完成后,我们可以继续为我们的应用程序选择顶级硬件函数,并设置正确的接口。点击“函数映射”按钮,打开功能映射编辑器。如果你确定顶层硬件函数,检查它的可综合性问题,并使用函数映射编辑器中的右键菜单将其映射到FPGA上。或者,运行自动选择FPGA功能,让SLX自动选择顶层的硬件函数。对于这个人脸识别应用,我们选择face_detect_sw作为我们的顶级硬件函数。一旦正确选择了顶层硬件函数,函数映射编辑器将看起来像图4,所有映射到FPGA的函数将有一个红色边框。
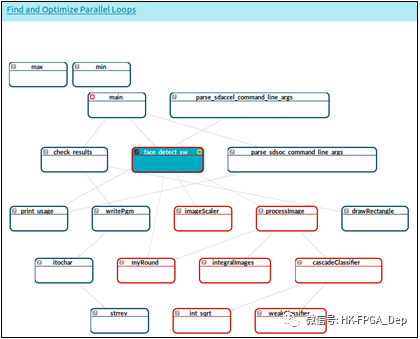
图4:SLX FPGA函数映射编辑器
现在我们准备为这个函数选择接口。在函数映射编辑器中选择顶级硬件函数后,点击properties标签,用左侧的菜单打开接口选择,如图5所示。为所有数组和指针接口选择axi_m接口,为标量选择s_axilite接口。这将生成在Alveo加速器卡上使用Xilinx对象所需的接口pragmas。此外,SLX的优化引擎现在意识到了接口限制,并相应地选择了优化原则。
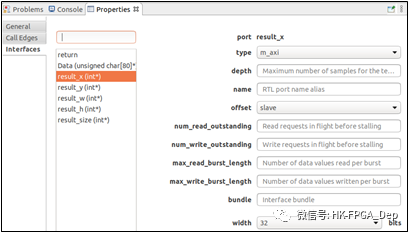
图5:SLX FPGA接口选择
在正确选择了所有接口后,我们现在设置使用SLX FPGA优化和生成pragmas。
二、在SLX FPGA中生成HLS pragmas
生成HLS pragmas有两个步骤:
1. 在FPGA中查找并并行化循环
2. 生成插入HLS注释的代码
在第一步中,SLX的优化引擎搜索可能的解决方案的设计空间,以确定最优的实用程序和参数集。设计空间包括:(1)循环的不同并行化选项,即针对不同展开因子采用流水线或unroll;(2)数组的多维分割和重构选项(完全分割或循环分割);
(3)函数层次结构:内联或阻塞。
对于这个特定的例子,这将导致大约1.32 x e19的设计点,SLX的优化引擎将在70秒内收敛到一个解决方案。
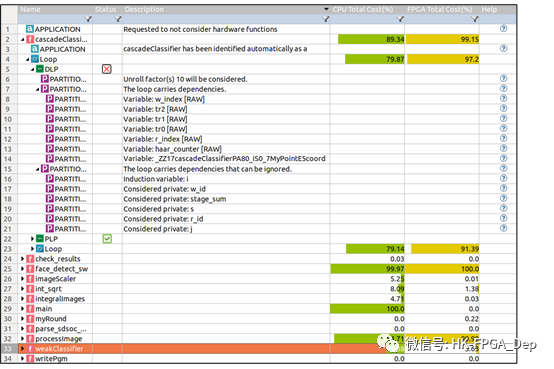
图6:SLX FPGA提示视图
图6显示了SLX FPGA提示视图。提示视图中的第四列和第五列显示了应用程序中不同函数和循环的CPU总成本和FPGA总成本。FPGA总成本是对特定功能或回路的延迟估计。这对于帮助开发人员集中精力进行优化特别有用。例如,第33行(图6)上的weekClassifier函数在纯软件实现中花费24.4%的CPU时间。然而,它对FPGA实现中的关键路径延迟的贡献仅为3.63%。
相比之下,在纯软件实现中,cascadeClassifier函数的第4行上的循环(图6)花费了79.9%的CPU时间,但贡献了97.2%的FPGA关键路径延迟。提示视图还突出显示了携带依赖关系的关键循环。请注意,SLX FPGA不认为所有的lcd都是相等的,并将可以忽略的lcd(例如,归纳和缩减变量)从关键的lcd中分离出来。这些信息可以帮助开发人员节省时间,使他们能够将精力集中在FPGA实现中真正重要的应用程序部分。
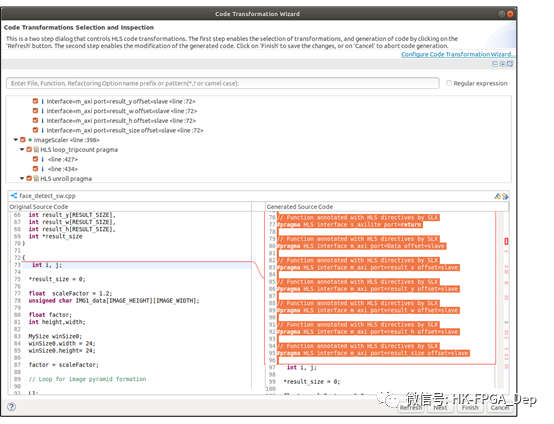
图7:显示自动编译插入的SLX FPGA代码生成向导单击“Generate HLS Code”按钮 将打开代码转换向导,如图7所示。在这里,用户可以检查生成的代码与原始版本的代码并选择/取消代码生成的pragmas,以便对实现进行微调。
三、在Vitis应用项目中导入Xilinx对象
在一个SLX FPGA项目的hls文件夹包含一个Vitis hls项目SLX优化的源代码。我们使用VitisHLS打开这个项目,并将RTL导出为Xilinx对象,如图8所示。在导出到Vitis之前,我们需要添加Extern“C”包装器以确保C链接。
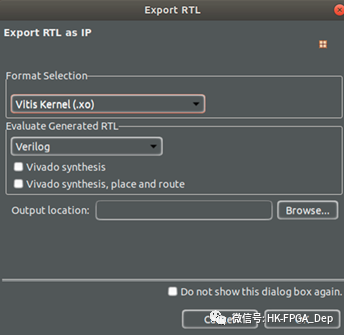
图8:从Vitis HLS导出Xilinx对象
在Vitis工作空间中,创建一个新的应用程序,使用一个alveso U280卡作为目标设备,如图9所示。
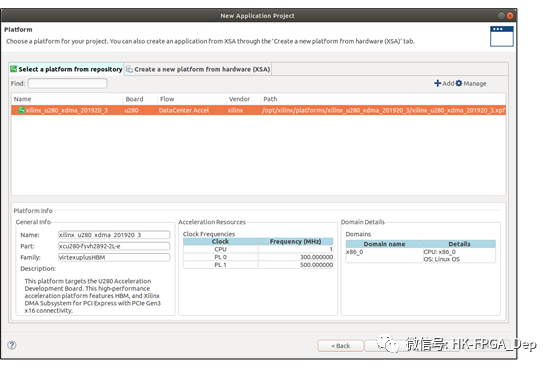
图9:在Vitis统一平台中创建应用程序项目创建项目之后,我们将.xo文件导入内核的src文件夹,如图10所示。导入.xo文件后,单击“添加硬件功能”按钮,并选择列表face_detect_sw。
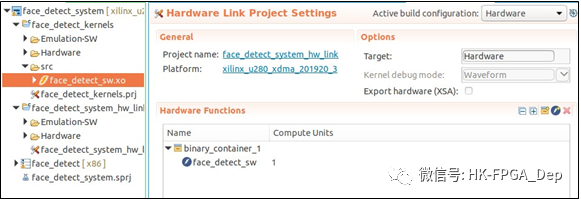
图10:在Vitis应用程序项目中导入内核开发人员现在可以利用加速的face_detect_sw内核创建更广泛的应用程序,该应用程序运行在x86主机上。
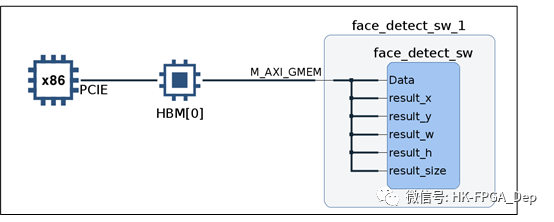
图11:Vitis Analyzer系统图
性能改进
在综合设计的基础上,对SLX优化后的内核与未优化前的内核的性能和资源利用率进行了比较。对于这个特殊的设计,我们允许SLX FPGA使用选定设备上的所有可用资源;但是,如果有必要,还可以添加其他约束。表1显示了结果的摘要。我们发现LUT增加3倍,延迟减少7.8倍,FF增加2.4倍,DSP块增加2.7倍。对于alveso卡来说,这种资源利用率的增加并不是一个大问题,因为所有资源的利用率仍然低于5%。如果需要更高的性能,SLXFPGA中可以提供大量额外的分析功能,以帮助指导设计者更快更有效地重构他们的代码。
结论
本案例展示了如何利用Vitis自下而上的内核流程,将SLX FPGA用于优化针对PCIe连接Alveo卡的内核。在这个例子中,SLX FPGA能够减少一个常用的人工智能内核的延迟,用于人脸检测。该方法可应用于大多数基于赛灵思的数据中心应用,包括亚马逊F1实例。无论是从头开始开发应用,还是重复使用现有的设计并根据需求进行定制,都可以应用这种方法。
原文标题:虹科方案 | 使用HLS优化人脸识OpenCL AI内核
文章出处:【微信公众号:FPGA威廉希尔官方网站 支持】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
FPGA
+关注
关注
1629文章
21729浏览量
603049 -
AI
+关注
关注
87文章
30763浏览量
268912 -
Vitis
+关注
关注
0文章
146浏览量
7422
原文标题:虹科方案 | 使用HLS优化人脸识OpenCL AI内核
文章出处:【微信号:HK-FPGA_Dep,微信公众号:FPGA威廉希尔官方网站 支持】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
AI时代,我们需要怎样的数据中心?AI重新定义数据中心

数据中心液冷需求、威廉希尔官方网站 及实际应用
八大科技巨头携手推进UALink,加速数据中心AI互联
HNS 2024:星河AI数据中心网络,赋AI时代新动能

苹果正在研发全新数据中心AI芯片
数据中心UPS系统运行能耗优化探讨与应用


是德科技推出AI数据中心测试平台


是德科技推出AI数据中心测试平台旨在加速AI/ML网络验证和优化的创新








 工商网监
工商网监
评论