 实时SLAM的未来以及深度学习与SLAM的比较
实时SLAM的未来以及深度学习与SLAM的比较
SLAM (simultaneous localization and mapping),也称为CML (Concurrent Mapping and Localization), 即时定位与地图构建,或并发建图与定位。问题可以描述为:将一个机器人放入未知环境中的未知位置,是否有办法让机器人一边逐步描绘出此环境完全的地图,所谓完全的地图(a consistent map)是指不受障碍行进到房间可进入的每个角落。SLAM最早由Smith、Self和Cheeseman于1988年提出。由于其重要的理论与应用价值,被很多学者认为是实现真正全自主移动机器人的关键。
词语解释
Simultaneous Localization and Mapping
Simultaneous Localization and Mapping, 同步定位与建图。
SLAM问题可以描述为: 机器人在未知环境中从一个未知位置开始移动,在移动过程中根据位置估计和地图进行自身定位,同时在自身定位的基础上建造增量式地图,实现机器人的自主定位和导航。
Scanning Laser Acoustic Microscope
Scanning Laser Acoustic Microscope, 激光扫描声学显微镜。
激光扫描声学显微镜是一种强有力的广泛应用于诸如工业用材料和生物医学领域的无损检测工具,其使用的频率范围为10MHz ~ 500MHz。
Lymphocyte Activation Molecule
Lymphocyte Activation Molecule, 医学用语。
Supersonic Low Altitude Missile
SLAM — Supersonic Low Altitude Missile(超音速低空导弹)的缩写,是美国的一项导弹研制计划。
Symmetrically Loaded Acoustic Module
SLAM是Symmetrically Loaded Acoustic Module的英文缩写 [1] ,中文意思是平衡装载声学模块。
Satellite Link Attenuation Model
SLM是Satellite Link Attenuation Model的英文缩写 [2] ,中文意思是卫星链路衰减模型。
实时SLAM的未来以及深度学习与SLAM的比较
第一部分:为什么 SLAM 很重要?
视觉 SLAM 算法可以实时构建世界的 3D 地图,并同时追踪摄像头(手持式或增强现实设备上的头戴式或安装在机器人上)的位置和方向。SLAM 是卷积神经网络和深度学习的补充:SLAM 关注于几何问题而深度学习是感知、识别问题的大师。如果你想要一个能走到你的冰箱面前而不撞到墙壁的机器人,那就使用 SLAM。如果你想要一个能识别冰箱中的物品的机器人,那就使用卷积神经网络。
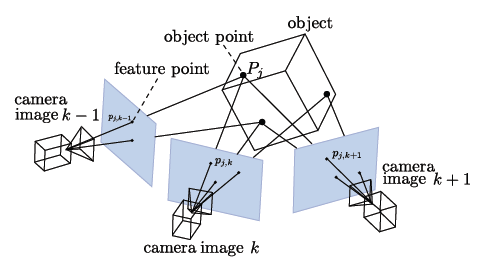
SfM/SLAM 基本原理:一个场景的 3D 结构是根据点观察和固有的摄像头参数,从摄像头的估计的运动中计算出来的.
SLAM 是 SfM(运动恢复结构:Structure from Motion)的一种实时版本。视觉 SLAM 或基于视觉的 SLAM 是 SLAM 的一种仅使用摄像头的变体,放弃了昂贵的激光传感器和惯性测量单元。单眼 SLAM仅使用单个摄像头,而非单眼 SLAM通常使用一个预校准的固定基线的立体相机套件。SLAM 是计算机视觉领域所谓的几何方法中最好案例。事实上,卡内基梅隆大学的机器人研究所将研究生水平的计算机视觉课程分成了一个基于学习的视觉方法和一个单独的基于几何的视觉方法的课程。
1.运动恢复结构 vs 视觉 SLAM
运动恢复结构(SfM)和 SLAM 所解决的问题非常相似,但 SfM 传统上是以离线形式进行的,而 SLAM 则已经慢慢走向了低功耗/实时/单 RGB 相机的运行模式。今天许多运动恢复结构方面的专家都在为世界上一些最大的科技公司,帮助打造更好的地图。如果没有关于多视图几何、SfM 和 SLAM 的丰富知识,像谷歌地图这种成功的地图产品根本就不可能出现。典型的 SfM 问题遵循:给定一个单个室外结构(如大剧场/大体育馆)的大型照片集合,构建该结构的 3D 模型并确定每个相机的姿势。这个照片集合以离线形式处理,而且大型结构重建所需时间从几小时到几天不等。

SfM 软件:Bundler 是最成功的 SfM 开源库之一
这里给出一些流行的 SfM 相关的软件库:
Bundler:一个开源的运动恢复结构工具包
Libceres:一个非线性最小二乘极小化工具(对束调整(bundle adjustment)问题很有用)
Andrew Zisserman 的多视图几何 MATLAB 函数
2.视觉 SLAM vs 自动驾驶
研讨会的组织者之一 Andrew Davison 表示,尽管自动驾驶汽车是 SLAM 最重要的应用之一,但用于自动化载具的 SLAM 应该有其自己的研究轨道。(而且正如我们所见,研讨会的展示者中没有一个谈到了自动驾驶汽车。)在接下来的许多年里,独立于任何一个圣杯级的应用而继续在研究的角度上研究 SLAM 是有意义的。尽管在自动化载具方面存在着太多的系统级细节和技巧,但研究级的 SLAM 系统所需的不过是一个网络摄像头、算法知识和一点辛劳而已。视觉 SLAM 作为一个研究课题对数以千计的博士生的早期阶段要友好得多,他们将首先需要好几年的使用 SLAM 的实验室经验,然后才能开始考虑无人驾驶汽车等昂贵的机器人平台。

谷歌无人驾驶汽车的感知系统
第二部分:实时 SLAM 的未来
现在是时候正式总结和评论实时 SLAM 的未来研讨会上的演讲了。Andrew Davison 以一个名叫基于视觉的 SALM 的十五年的精彩历史概述开篇,他的幻灯片中还有一个介绍机器人学课程的好内容。
你也许不知道 Andrew 是谁,他是伦敦帝国学院独一无二的 Andrew Davison 教授。他最知名的成就是其 2003 年的 MonoSLAM 系统,他是第一个展示如何在单个摄像头上构建 SLAM 系统的人,而那时候其他所有人都还认为打造 SLAM 系统需要一个立体的双目摄像头套件。最近,他的研究成果已经对戴森(Dyson)等公司的发展轨迹和他们的机器人系统的能力产生了影响(如全新的 Dyson360)。
我还记得 Davidson 教授曾在 2007 年的 BMVC(英国机器视觉大会)上给出了一个视觉 SLAM 教程。让人惊讶的是,和主要的视觉大会上其它机器学习威廉希尔官方网站 的纷繁成果相比,SLAM 的变化真是非常之少。过去八年里,对象识别已经经历了两三次小型变革,而今天的 SLAM 系统和其八年前的样子看起来并没有多大不同。了解 SLAM 的进展的最好方法是看最成功和最让人难忘的系统。在 Davidson 的研讨会介绍演讲中,他讨论了一些过去 10-15 年里科研界所打造的典范系统:
MonoSLAM
PTAM
FAB-MAP
DTAM
KinectFusion
1.Davison vs Horn:机器人视觉的下一篇章
Davison 还提到他正在写一本关于机器人视觉的新书,这对计算机视觉、机器人和人工智能领域的研究者来说应该是一个激动人心的好消息。上一本机器人视觉的书是由 B.K. Horn 写的(出版于 1986 年),现在也到该更新的时候了。
机器人视觉的一本新书?
尽管我很乐意阅读一本重在机器人视觉原理的巨著,但我个人希望该书关注的是机器人视觉的实用算法,就像 Hartley 和 Zissermann 的杰作《多视图几何》或 Thrun、Burgard 和 Fox 所著的《概率机器人学》那样。这本关于视觉 SLAM 问题的书籍将会受到所有专注视觉研究者欢迎。
演讲一:Christian Kerl 谈 SLAM 中的连续轨迹
第一个演讲来自 Christian Kerl,他提出了一种用于估计连续时间轨迹的密集跟踪方法。其关键观察结果发现:大部分 SLAM 系统都在离散数目的时间步骤上估计摄像头的位置(要么是相隔几秒的关键帧,要么是相隔大约 1/25 秒的各个帧。
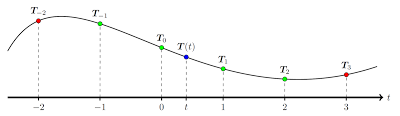
连续轨迹 vs 离散时间点 SLAM/SfM 通常使用离散时间点,但为什么不使用连续的呢?
Kerl 的大部分演讲都集中于解决卷帘式快门相机的危害,而 Kerl 演示的系统还对建模给予谨慎的关注并消除了这些卷帘式快门的不利影响。
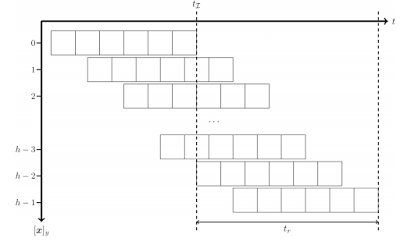
解决视觉 SLAM 中卷帘式快门相机的危害
演讲二:Jakob Engel 谈半密集直接 SLAM(Semi-Dense Direct SLAM)
LSD-SLAM(大规模直接单眼 SLAM)在2014 ECCV 上公开,也是我现在最喜欢的 SLAM 系统之一!Jakob Engel 在那里展示了他的系统并向观众展示了当时最炫酷的一些 SLAM 可视化。对 SLAM 研究者来说,LSD-SLAM 是一个非常重要的系统,因为它不使用边角或其它任何本地特性。通过使用一种带有稳健的 Huber 损失的由粗到细的算法,直接跟踪可由图像到图像对准完成。这和那些基于特征的系统非常不同。深度估计使用了逆深度参数化(和许多其它系统一样)并使用了大量或相对小的基准图像对。该算法并不依赖于图像特征,而是靠有效地执行纹理跟踪。全局映射是通过创建和解决姿态图形的束调整优化问题而执行的,而且这所有都是实时工作的。这个方法是半密集的,因为它仅估计靠近图像边界的像素深度。LSD-SLAM 输出比传统的特征更密集,但并不如 Kinect 类型的 RGBD SLAM 那样完全密集。

工作中的 LSD-SLAM:LSD-SLAM 同时生成一个摄像头轨迹和一个半密集的 3D 场景重建。这种方法实时工作,不使用特征点作为图元,并执行直接的图像到图像对准。
Engel 概述了原来的 LSD-SLAM 系统以及一些新成果,将它们最初的系统扩展成更有创造性的应用并实现了更有趣的部署。
全方位 LSD-SLAM是 LSD-SLAM 的一种延伸,因观察到针孔模型不能用于大视场的观测而被创造出来。这项成果提出于 IROS 2015(2015 年智能机器人和系统国际大会)(Caruso 是第一作者),能用于大视场(理想情况下可超过 180 度)。Engel 的演讲很清楚地表示,你可以拿着相机以芭蕾舞般的动作极限旋转在你的办公室内走来走去。这是窄视场 SLAM 最糟糕的应用场景之一,但却在 Omni LSD-SLAM 中效果良好。
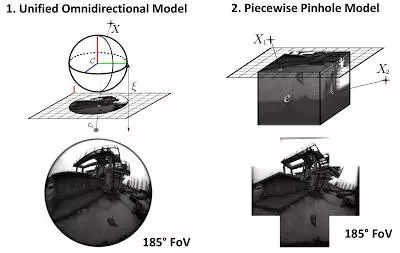
全方位的 LSD-SLAM 模型
立体 LSD-SLAM是 LSD-SLAM 的一种用于双眼摄像头套件的延伸。这有助于获得没有限制的规模,而且其初始化是瞬时的,强烈旋转也不存在问题。尽管从学术的角度看,单眼 SLAM 是很激动人心,但如果你的机器人是一辆 30,000 美元的车或 10,000 美元的无人机原型,你应该有足够的理由使用一套带有两个乃至更多摄像头的套件。Stereo LSD-SLAM 在 SLAM 基准上表现出了相当强的竞争力。

Stereo LSD-SLAM 在 KITTI vehicle-SLAM 数据集上得到了优异结果
Stereo LSD-SLAM 相当实用,能优化 SE(3) 中的姿态图形,并包含了对自动曝光的校正。自动曝光校正的目标是让误差函数相对于仿射光照变化而不变。颜色空间仿射转换的基本参数是在匹配过程中估算出来的,但也被扔掉以估计图像到图像变换中的错误。Engel 在演讲中称,离群值(outliers)(通常是由过度曝光的图像像素造成的)往往会带来问题,需要很仔细才能处理它们的影响。
在他后面的演示中,Engel 让我们一窥了关于立体和惯性传感器的整合新研究。为了了解详情,你只能跟踪 arXiv 上的更新或向 Usenko/Engel 本人了解。在应用方面,Engel 的演示中包含了由 LSD-SLAM 驱动的自动化四轴无人机的更新视频。其飞行一开始是上下运动的,以获得对尺寸的估计,然后又使用了自由空间的三维测绘(octomap)以估计自由空间,从而让该四轴无人机可以在空间中为自己导航。

运行 Stereo LSD-SLAM 的四轴无人机
LSD-SLAM 的故事也是基于特征 vs 直接方法的故事,Engel 给了辩论双方公正的待遇。基于特征的方法被设计用在 Harris 那样的边角之上,而直接方法则是用整个图像进行对准。基于特征的方法更快(截至 2015 年),但直接方法在并行处理上效果很好。离群值可以通过追溯的方法从基于特征的系统中移除,而直接方法在离群值处理上没那么灵活。卷帘式快门是直接方法的一个更大的问题,而且使用全局快门或卷帘式快门模型是有意义的。基于特征的方法需要使用不完整的信息进行决策,而直接方法可以使用更多信息。基于特征的方法不需要很好的初始化,而直接方法在初始化上需要更巧妙的技巧。对直接方法的研究只有 4 年,稀疏方法则有 20 多年的历史了。Engel 乐观地认为直接方法未来将上升成为顶级方法,我也这么想。
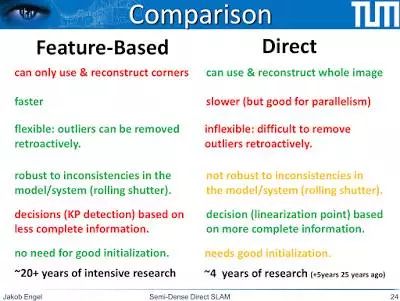
SLAM 系统构建上,基于特征的方法 vs 直接方法
在 Engel 演讲最后,Davison 问到了语义分割方面的问题,而 Engel 不知道语义分割是否可以在半密集的接近图像边界的数据上直接执行。但是,我个人的看法是,有更好的方法可将语义分割应用到 LSD 类型的 SLAM 系统上。半密集 SLAM 可以专注于靠近边界的几何信息,而对象识别可以专注于远离这同一边界的可靠语义,从而有可能创造出一个混合了几何和语义的图像解读。
演讲三:Torsten Sattler 谈大规模定位与地图构建面临的挑战
Torsten Sattler 的演讲谈论了大规模定位与地图构建。这项工作的目的是在已有的地图内执行六个自由度的定位,尤其是移动定位。演讲中的一个关键点是:当你使用传统的基于特征的方法时,存储你的描述很快就将变得非常昂贵。视觉词汇表(记得产品量化吗?)等威廉希尔官方网站 可以显著减少存储开销,再加上某种程度的巧妙优化,描述的存储将不再成为存储瓶颈。
Sattler 的演讲给出的另一个重要的关键信息是正确数据的数量实际上并不是相机姿态估计的很好的置信度测量。当特征点全都集中于图像的单一一个部分时,相机定位可能会在千里之外!一个更好的置信度测量是有效正确数据计数,其可以将正确数据所在的区域作为整体图像区域的一个部分来进行审查。你真正希望得到的是整体图像上的特征匹配——如果信息散布在整个图像上,你能得到更好的姿态估计。
Sattler 对未来实时 SLAM 的演讲是这样的:我们应该关注紧凑型的地图表征,我们应该对相机姿态估计置信度有更好的理解(如树上权重下降的特征),我们应该在更有挑战性的场景中研发(如带有平面结构的世界和在白天的地图上的夜间定位)。
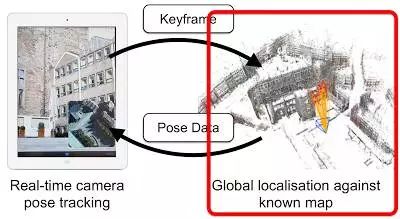
移动定位:Sattler 的关键问题是使用单张智能手机图片在大城市里定位你自己
演讲四:Mur-Artal 谈基于特征的方法 vs 直接方法
ORB-SLAM 的创造者 Mur-Artal 的演讲内容全部围绕着 SLAM 领域内基于特征的方法 vs 直接方法的争论,而他显然站在基于特征的方法一边。ORB-SLAM 可通过一个开源的 SLAM 软件包获取,而且它很难被击败。在他对 ORB-SLAM vs PTAM 的评价中,似乎 PTAM 实际上常常失败(至少在 TUM RGB-D 基准上)。LSD-SLAM 在 TUM RGB-D 基准上的错误通常远高于预期。

基于特征的方法 vs 直接方法
演讲五:Tango 项目和用于图像到图像限制的视觉环路闭合
简单来说,谷歌的 Tango 项目是世界上第一个商业化 SLAM 的尝试。来自 Google Zurich 的 Simon Lynen(之前属于 ETH Zurich)带着一个 Tango 现场演示(在一台平板电脑上)来到了研讨会,并展示了 Tango 世界的新内容。你可能不知道,谷歌希望将 SLAM 能力集成到下一代安卓设备中。

谷歌的Tango项目
Tango 项目展示讨论了一种通过在图像到图像匹配矩阵中寻找特定的模式以进行环路闭合的新方法。这 个方法是来自没有固定位置的位置识别成果。他们也做带有基于视觉的环路闭合的在线束调整。

Tango 项目里的循环闭合
这种图像到图像矩阵揭示一种寻找环路闭合的新方法。可在该 YouTube 视频中查看工作中的算法。
Tango 项目的人也在研究将谷歌多个众包地图结合起来,其目标是将由不同的人使用配置有 Tango 的设备创造的多个迷你地图结合起来。
Simon 展示了一个山地自行车轨迹跟踪的视频,这在实践中实际上是相当困难的。其中的想法是使用一个 Tango 设备跟踪一辆山地自行车,并创建一份地图,然后后续的目标是让另外一个人沿着这条轨迹走。这个目前只是半有效状态——当在地图构建和跟踪步骤之前有几个小时时间时有效,但过了几周、几个月就没效果了。
在 Tango 相关的讨论中,Richard Newcombe 指出 Tango 项目所使用的 “特征” 在更深度地理解环境上还是相当落后的,而且看起来类似 Tango 项目的方法无法在室外场景中起作用——室外场景有非刚性大量光照变化等。所以我们有望见到为室外环境设计的不同系统吗?Tango 项目将成为一个室内地图构建设备吗?
演讲六:ElasticFusion 是没有姿态图形的密集型 SLAM
ElasticFusion 是一种需要 Kinect 这样的 RGBD 传感器的密集型 SLAM 威廉希尔官方网站 。2-3 分钟就能获得单个房间的高质量 3D 扫描,这真是相当酷。许多 SLAM 系统的场景背后都使用了姿态图形,这种威廉希尔官方网站 有一种不同的(以地图为中心)方法。该方法专注于构建地图,但其诀窍是其构建的地图可以变形,也因此得名 ElasticFusion(弹性融合)。其中算法融合的部分是向 KinectFusion 致敬——KinectFusion 是第一个高质量的基于 Kinect 的重建方式。Surfels 也被用作底层的基元。
图片来自 Kintinuous,Whelan 的 Elastic Fusion 的早期版本
恢复光源:我们一窥了来自伦敦帝国学院/戴森机器人实验室的尚未发表的新研究成果。其中的想法是通过探测光源方向和探测镜面反射,你可以提升 3D 重建的结果。关于恢复光源位置的炫酷视频显示其最多能处理 4 个独立光源。
演讲七:Richard Newcombe 的 DynamicFusion
Richard Newcombe(他最近成立的公司被 Oculus 收购)是最后一位展示者。Richard Newcombe 是 DTAM、KinectFusion 和 DynamicFusion 背后的人,见到他真是非常酷;他目前从事虚拟现实领域的研发。
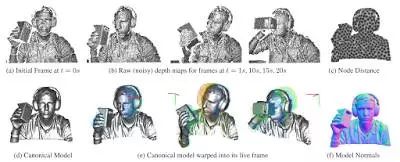
Newcombe 的 DynamicFusion 算法。该威廉希尔官方网站 在声望很高的 CVPR 2015中获得最佳论文奖。
2.研讨会演示
在演示会议期间(在研讨会中间举行),许多展示者展示了他们的 SLAM 系统工作中的样子。这些系统中许多都是以开源软件包的形式提供的,所以如果你对实时 SLAM 感兴趣,可以尝试下载这些代码。但是,最亮眼的演示是 Andrew Davison 展柜上他的来自 2004 年的 MonoSLAM 演示。Andrew 不得不恢复了已有 15 年岁月的计算机(运行的是 Redhat Linux)来展示他原来的系统,运行在原来的硬件上。如果计算机视觉社区将决定举办一场复古视觉的演示会议,那我马上就将会提名 Andrew 应得最佳论文奖。
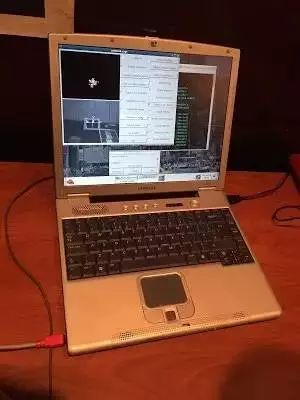
Andrew 复古的视觉 SLAM 配置
看着 SLAM 系统专家挥动自己的 USB 摄像头真是一件有趣的事——他们在展示他们的系统围绕他们的笔记本电脑构建周围桌子大小区域的 3D 地图。如果你仔细看了这些专家移动摄像头的方式(即平稳的圆圈运动),你几乎就能看出一个人在 SLAM 领域工作了多长时间。当一位非专家级的人拿着摄像头时,跟踪失败的概率明显更高。
我有幸在演示会议期间和 Andrew 进行了交谈,我很好奇这一系列的成果(过去 15 年中)中哪一个最让他感到惊讶。他的回答是 PTAM 最让他吃惊,因为其表明了实时束调整执行的方式。PTAM 系统本质上是 MonoSLAM++ 系统,但因为采用了一种重量级算法(束调整)而显著提高了跟踪效果并做到了实时——在 2000 年早期 Andrew 还认为“实时”是不可能办到的。
第三部分:深度学习 vs SLAM
SLAM 小组讨论真是乐趣无穷。在我们进入重要的深度学习 vs SLAM讨论之前,我应该说明每一位研讨会展示者都同意:语义对构建更大更好的 SLAM 系统是必需的。关于未来的方向,这里有很多有趣的小对话。在争论中,Marc Pollefeys(一位知名的 SfM 和多视角几何研究者)提醒所有人,机器人是 SLAM 的一个杀手级应用,并建议我们保持对大奖的关注。这令人非常惊讶,因为 SLAM 传统上是适用于机器人问题的,但过去几十年机器人并没有什么成功(谷歌机器人?),导致 SLAM 的关注重点从机器人转移到了大规模地图构建(包括谷歌地图)和增强现实上。研讨会上没人谈论过机器人。
1.将语义信息集成到 SLAM 中
人们对将语义整合到今天最出色的 SLAM 系统中有很大兴趣。当涉及语义时, SLAM 社区不幸地卡在了视觉词袋(bags-of-visual-words)的世界里,而在如何将语义信息整合进他们的系统上没有什么新想法。在语义一端,我们现在已经看到 CVPR/ICCV/ECCV 上冒出了很多实时语义分割演示(基于卷积神经网络);在我看来,SLAM 需要深度学习,而深度学习也一样需要 SLAM。
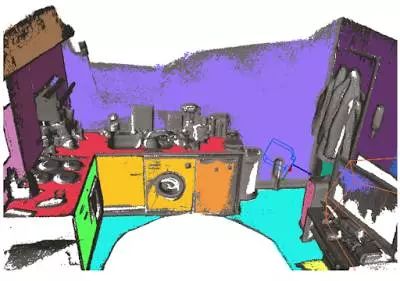
人们经常谈到将语义整合进 SLAM,但说起来容易做起来难。图片来自 Moreno 的博士论文(142 页):密集型语义 SLAM
2.端到端学习会主宰 SLAM 吗?
在 SLAM 研讨会小组讨论结束时,Zeeshan Zia 博士提出了一个震惊所有人的问题,并引发了一场充满能量的讨论,令人难忘。你应该看看小组成员们脸上的表情。那就像是将一个深度学习的火球投向一群几何学家。他们的面部表情表达出了他们的困惑、愤怒和厌恶。他们想:你怎么敢质疑我们?正是在这些稍纵即逝的时刻,我们才能真正体会到大会的体验。Zia 的问题基本上是:在构建今天的 SLAM 系统时,端到端学习很快就将取代大部分人工劳动吗?
Zia 的问题非常重要,因为端到端的可训练系统已经慢慢进入到了很多高级的计算机问题中,相信 SLAM 会是一个例外是没有道理的。有好几位展示者都指出当前的 SLAM 系统过于依赖几何,以至于让完全基于深度学习的 SLAM 系统看起来不合理了——我们应该使用学习威廉希尔官方网站 得到更好的点描述,而不要管几何。你可以使用深度学习做一个计算器,并不意味你应该这么做。

通过卷积神经网络学习立体相似度函数,来自 Yan LeCun 及其合作者
尽管许多小组讨论发言人都使用了有些肯定不行回应,但让人惊讶的是,却是 Newcombe 声援了深度学习和 SLAM 联姻的可能。
3.Newcombe 的提议:使用 SLAM 助力深度学习
尽管 Newcombe 在深度学习可能如何帮助 SLAM 上没有提供很多证据或想法,但他却为 SLAM 如何可能为深度学习提供帮助给出了一条清晰的路径。想想看我们使用大规模 SLAM 已经构建出的地图以及这些系统所提供的对应——这难道不是一个构建能帮助深度学习的万亿级图像到图像相关数据集的清晰路径吗?其基本思路是:今天的 SLAM 系统是大规模的对应引擎,可以用来生成大规模数据集,而这正是深度卷积神经网络所需要的。
第四部分:结语
这次 ICCV 大会上主流的工作(重在机器学习)和本次实时 SLAM 研讨会所呈现出现的工作(重在束调整等几何方法)之间存在相当大的脱节。主流的计算机视觉社区在过去十年内已经见证了多次小型变革(如:Dalal-Triggs、DPM、ImageNet、ConvNets、R-CNN),而今天的 SLAM 系统和它们八年前的样子并没有很大的不同。Kinect 传感器可能是 SLAM 领域唯一的最大的彻底变革的威廉希尔官方网站 ,但基础算法仍旧保持着原样。
集成语义信息:视觉 SLAM 的下一个前沿. 来自 Arwen Wallington 博客的脑图
今天的 SLAM 系统能帮助机器在几何上理解眼前的世界(即在本地坐标系中构建关联),而今天的深度学习系统能帮助机器进行分类推理(即在不同的对象实例之上构建关联)。总的来说,在视觉 SLAM 上,我与 Newcombe 和 Davison 一样兴奋,因为基于视觉的算法将会将增强现实和虚拟现实转变成一个价值数十亿美元的产业。但是,我们不应忘记保持对那个万亿美元市场的关注,那个将重新定义 “工作” 的市场——机器人。机器人 SLAM 的时代很快就要到来了。
SLAM的前世今生
SLAM的前世
我之前从本科到研究生,一直在导航与定位领域学习,一开始偏重于高精度的惯性导航、卫星导航、星光制导及其组合导航。出于对实现无源导航的执念,我慢慢开始研究视觉导航中的SLAM方向,并与传统的惯性器件做组合,实现独立设备的自主导航定位。
定位、定向、测速、授时是人们惆怅千年都未能完全解决的问题,最早的时候,古人只能靠夜观天象和司南来做简单的定向。直至元代,出于对定位的需求,才华横溢的中国人发明了令人叹为观止的牵星术,用牵星板测量星星实现纬度估计。
1964年美国投入使用GPS,突然就打破了大家的游戏规则。军用的P码可以达到1-2米级精度,开放给大众使用的CA码也能够实现5-10米级的精度。
后来大家一方面为了突破P码封锁,另一方面为了追求更高的定位定姿精度,想出了很多十分具有创意的想法来挺升GPS的精度。利用RTK的实时相位差分威廉希尔官方网站 ,甚至能实现厘米的定位精度,基本上解决了室外的定位和定姿问题。
但是室内这个问题就难办多了,为了实现室内的定位定姿,一大批威廉希尔官方网站 不断涌现,其中,SLAM威廉希尔官方网站 逐渐脱颖而出。SLAM是一个十分交叉学科的领域,我先从它的传感器讲起。
▌离不开这两类传感器
目前用在SLAM上的Sensor主要分两大类,激光雷达和摄像头。

这里面列举了一些常见的雷达和各种深度摄像头。激光雷达有单线多线之分,角分辨率及精度也各有千秋。SICK、velodyne、Hokuyo以及国内的北醒光学、Slamtech是比较有名的激光雷达厂商。他们可以作为SLAM的一种输入形式。
这个小视频里展示的就是一种简单的2D SLAM。

这个小视频是宾大的教授kumar做的特别有名的一个demo,是在无人机上利用二维激光雷达做的SLAM。

而VSLAM则主要用摄像头来实现,摄像头品种繁多,主要分为单目、双目、单目结构光、双目结构光、ToF几大类。他们的核心都是获取RGB和depth map(深度信息)。简单的单目和双目(Zed、leapmotion)我这里不多做解释,我主要解释一下结构光和ToF。
▌最近流行的结构光和TOF
结构光原理的深度摄像机通常具有激光投射器、光学衍射元件(DOE)、红外摄像头三大核心器件。
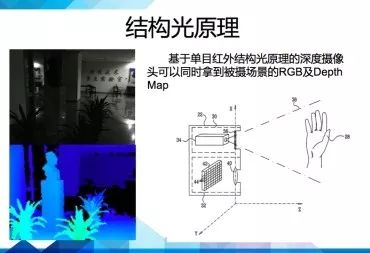
这个图(下图)摘自primesense的专利。
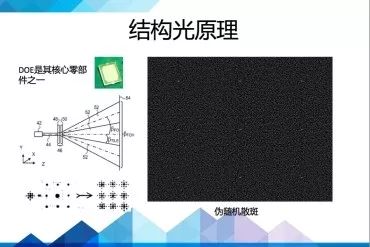
可以看到primesense的doe是由两部分组成的,一个是扩散片,一个是衍射片。先通过扩散成一个区域的随机散斑,然后复制成九份,投射到了被摄物体上。根据红外摄像头捕捉到的红外散斑,PS1080这个芯片就可以快速解算出各个点的深度信息。
这儿还有两款结构光原理的摄像头。


第一页它是由两幅十分规律的散斑组成,最后同时被红外相机获得,精度相对较高。但据说DOE成本也比较高。
还有一种比较独特的方案(最后一幅图),它采用mems微镜的方式,类似DLP投影仪,将激光器进行调频,通过微镜反射出去,并快速改变微镜姿态,进行行列扫描,实现结构光的投射。(产自ST,ST经常做出一些比较炫的黑科技)。
ToF(time of flight)也是一种很有前景的深度获取方法。
传感器发出经调制的近红外光,遇物体后反射,传感器通过计算光线发射和反射时间差或相位差,来换算被拍摄景物的距离,以产生深度信息。类似于雷达,或者想象一下蝙蝠,softkinetic的DS325采用的就是ToF方案(TI设计的),但是它的接收器微观结构比较特殊,有2个或者更多快门,测ps级别的时间差,但它的单位像素尺寸通常在100um的尺寸,所以目前分辨率不高。以后也会有不错的前景,但我觉得并不是颠覆性的。
好,那在有了深度图之后呢,SLAM算法就开始工作了,由于Sensor和需求的不同,SLAM的呈现形式略有差异。大致可以分为激光SLAM(也分2D和3D)和视觉SLAM(也分Sparse、semiDense、Dense)两类,但其主要思路大同小异。
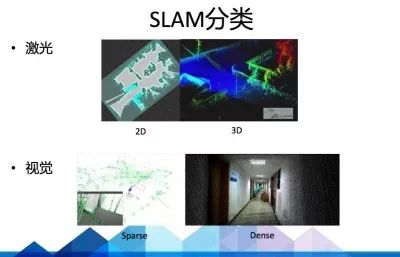
这个是Sparse(稀疏)的

这个偏Dense(密集)的

▌SLAM算法实现的4要素
SLAM算法在实现的时候主要要考虑以下4个方面吧:
1. 地图表示问题,比如dense和sparse都是它的不同表达方式,这个需要根据实际场景需求去抉择
2. 信息感知问题,需要考虑如何全面的感知这个环境,RGBD摄像头FOV通常比较小,但激光雷达比较大
3. 数据关联问题,不同的sensor的数据类型、时间戳、坐标系表达方式各有不同,需要统一处理
4. 定位与构图问题,就是指怎么实现位姿估计和建模,这里面涉及到很多数学问题,物理模型建立,状态估计和优化
其他的还有回环检测问题,探索问题(exploration),以及绑架问题(kidnapping)。

这个是一个比较有名的SLAM算法,这个回环检测就很漂亮。但这个调用了cuda,gpu对运算能力要求挺高,效果看起来比较炫。
▌以VSLAM举个栗子
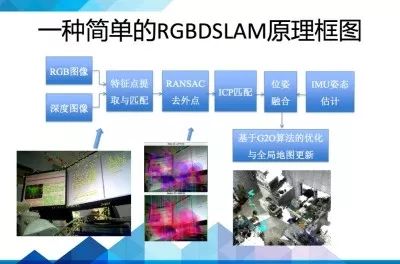
我大概讲一种比较流行的VSLAM方法框架。
整个SLAM大概可以分为前端和后端,前端相当于VO(视觉里程计),研究帧与帧之间变换关系。首先提取每帧图像特征点,利用相邻帧图像,进行特征点匹配,然后利用RANSAC去除大噪声,然后进行匹配,得到一个pose信息(位置和姿态),同时可以利用IMU(Inertial measurement unit惯性测量单元)提供的姿态信息进行滤波融合
后端则主要是对前端出结果进行优化,利用滤波理论(EKF、UKF、PF)、或者优化理论TORO、G2O进行树或者图的优化。最终得到最优的位姿估计。
后端这边难点比较多,涉及到的数学知识也比较多,总的来说大家已经慢慢抛弃传统的滤波理论走向图优化去了。
因为基于滤波的理论,滤波器稳度增长太快,这对于需要频繁求逆的EKF(扩展卡尔曼滤波器),PF压力很大。而基于图的SLAM,通常以keyframe(关键帧)为基础,建立多个节点和节点之间的相对变换关系,比如仿射变换矩阵,并不断地进行关键节点的维护,保证图的容量,在保证精度的同时,降低了计算量。
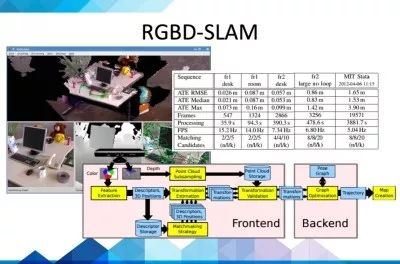
列举几个目前比较有名的SLAM算法:PTAM,MonoSLAM, ORB-SLAM,RGBD-SLAM,RTAB-SLAM,LSD-SLAM。
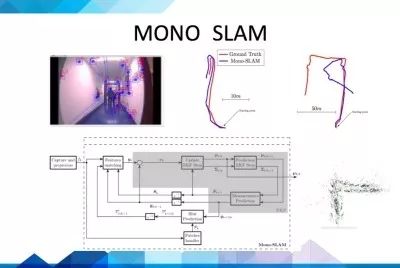


所以大家如果想学习SLAM的话,各个高校提高的素材是很多的,比如宾大、MIT、ETH、香港科技大学、帝国理工等等都有比较好的代表作品,还有一个比较有前景的就是三维的机器视觉,普林斯顿大学的肖剑雄教授结合SLAM和Deep Learning做一些三维物体的分类和识别, 实现一个对场景深度理解的机器人感知引擎。

http://robots.princeton.edu/talks/2016_MIT/RobotPerception.pdf这是他们的展示。
总的来说,SLAM威廉希尔官方网站 从最早的军事用途(核潜艇海底定位就有了SLAM的雏形)到今天,已经逐步走入人们的视野,扫地机器人的盛行更是让它名声大噪。同时基于三维视觉的VSLAM越来越显主流。在地面/空中机器人、VR/AR/MR、汽车/AGV自动驾驶等领域,都会得到深入的发展,同时也会出现越来越多的细分市场等待挖掘。

这个是occipital团队出的一个产品,是个很有意思的应用,国内卖4000+,大概一个月1000出货量吧(虽然不是很多,但是效果不错,pad可玩)虚拟家居、无人飞行/驾驶、虚拟试衣、3D打印、刑侦现场记录、沉浸式游戏、增强现实、商场推送、设计辅助、地震救援、工业流水线、GIS采集等等,都等待着VSLAM威廉希尔官方网站 一展宏图
▌SLAM的今生——还存在着问题
多传感器融合、优化数据关联与回环检测、与前端异构处理器集成、提升鲁棒性和重定位精度都是SLAM威廉希尔官方网站 接下来的发展方向,但这些都会随着消费刺激和产业链的发展逐步解决。就像手机中的陀螺仪一样,在不久的将来,也会飞入寻常百姓家,改变人类的生活。
不过说实话,SLAM在全面进入消费级市场的过程中,也面对着一些阻力和难题。比如Sensor精度不高、计算量大、Sensor应用场景不具有普适性等等问题。
多传感器融合、优化数据关联与回环检测、与前端异构处理器集成、提升鲁棒性和重定位精度都是SLAM威廉希尔官方网站 接下来的发展方向,但这些都会随着消费刺激和产业链的发展逐步解决。就像手机中的陀螺仪一样,在不久的将来,也会飞入寻常百姓家,改变人类的生活。
(激光雷达和摄像头两种 SLAM 方式各有什么优缺点呢,有没有一种综合的方式互补各自的缺点的呢?)
激光雷达优点是可视范围广,但是缺点性价比低,低成本的雷达角分辨率不够高,影响到建模精度。vSLAM的话缺点就是FOV通常不大,50-60degree,这样高速旋转时就容易丢,解决方案有的,我们公司就在做vSLAM跟雷达还有IMU的组合。
(请问目前基于视觉的SLAM的计算量有多大?嵌入式系统上如果要做到实时30fps,是不是只有Nvidia的芯片(支持cuda)才可以?)
第一个问题,虽然基于视觉的SLAM计算量相对较大,但在嵌入式系统上是可以跑起来的,Sparse的SLAM可以达到30-50hz(也不需要GPU和Cuda),如果dense的话就比较消耗资源,根据点云还有三角化密度可调,10-20hz也是没有问题。
并不一定要用cuda,一些用到cuda和GPU的算法主要是用来加速SIFT、ICP,以及后期三角化和mesh的过程,即使不用cuda可以采用其他的特征点提取和匹配策略也是可以的。
▌最后一个问题
想了解下,您对机器人的未来趋势怎么看?
这个问题就比较大了。
机器人产业是个很大的Ecosystem,短时间来讲,可能产业链不够完整,消费级市场缺乏爆点爆款。虽然大家都在谈论做机器人,但是好多公司并没有解决用户痛点,也没有为机器人产业链创造什么价值。
但是大家可以看到, 大批缺乏特色和积淀的机器人公司正在被淘汰,行业格局越来越清晰,分工逐渐完善,一大批细分市场成长起来。
从机器人的感知部分来说,传感器性能提升、前端处理(目前的sensor前端处理做的太少,给主CPU造成了很大的负担)、多传感器融合是一个很大的增长点。
现在人工智能也开始扬头,深度学习、神经网络专用的分布式异构处理器及其协处理器成为紧急需求,我个人很希望国内有公司能把这块做好。
也有好多创业公司做底层工艺比如高推重比电机、高能量密度电池、复合材料,他们和机器人产业的对接,也会加速机器人行业的发展。整个机器人生态架构会越来越清晰,从硬件层到算法层到功能层到SDK 再到应用层,每一个细分领域都有公司切入,随着这些产业节点的完善,能看到机器人行业的前景还是很棒的,相信不久之后就会迎来堪比互联网的指数式增长!
责任编辑:lq
-
移动机器人
+关注
关注
2文章
762浏览量
33572 -
SLAM
+关注
关注
23文章
424浏览量
31831 -
深度学习
+关注
关注
73文章
5503浏览量
121159
原文标题:深度好文 | 超全SLAM威廉希尔官方网站 及应用介绍
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
一种基于MASt3R的实时稠密SLAM系统
利用VLM和MLLMs实现SLAM语义增强


最新图优化框架,全面提升SLAM定位精度

激光雷达在SLAM算法中的应用综述
MG-SLAM:融合结构化线特征优化高斯SLAM算法


深度解析深度学习下的语义SLAM

工程实践中VINS与ORB-SLAM的优劣分析

什么是SLAM?SLAM算法涉及的4要素
什么是SLAM?基于3D高斯辐射场的SLAM优势分析
从基本原理到应用的SLAM威廉希尔官方网站 深度解析
基于NeRF/Gaussian的全新SLAM算法

基于深度学习的LiDAR SLAM框架(DeepPointMap)






 工商网监
工商网监
评论