 关于文本匹配的破城长矛
关于文本匹配的破城长矛
搜索也好,检索式对话也好,文本是一个很难绕开的话题,虽然语义是一个重要因素,用语义相似度直接梭,但是用户的感知可不是如此,很多用户的感知更多是文本层面的相似要高于语义相似,或者说,遇到语义相似和文本相似的时候会更优先接受文本相似,毕竟文本使用户能直接看到的,当然语义相似度虽好,但是对于没有什么标注数据的情况,也是束手无策吧。
所以,即使语义相似度如火如荼地发展着,文本层面的匹配依旧是项目实践中不可避免的关注点。
cqr&ctr概念
cqr和ctr的概念还是比较清晰明确的。
给定query和title,现在计算cqr和ctr。
讲完了,就是这么简单,其实就是看两者交集占query的占比和占title的占比,就是对应的cqr和ctr。
当然,由于这种计算会把所有词的重要性考虑进去,例如“怎么做作业”分别和“怎样做作业”、“怎么做手机”,两个的相似度就一样了,此时就要考虑到给每个词加点权重,这样能更好地描述,这就是一个优化的实用版本,加权
给定query,有对应的权重和title,以及对应权重,现在计算cqr和ctr:
想到可能会有人问到权重怎么来,这里我就要把我的历史文章放出来了,之前是专门讲过词权重的问题的:NLP.TM[20] | 词权重问题
这个应该就是我自己平时用的版本了,而且屡试不爽。
而如果是要分析两个句子综合、无偏的相似度,只要相乘就好了:
细品
可以看到,这个东西很简单,就是一个基于统计计算的工具,但是我依然想仔细讨论一下这个东西。
首先,有关相似度,其实我们很容易想到这个计算方法:
就是比较著名的jaccard相似度,当然还有一个更加出名的方法,那就是BM25(更为常见,此处就不赘述了)。但是我并没有选择,为什么呢,其实核心就是1个点:
query和title的长度信息。
jaccard距离虽然能比较综合、无偏向性地计算两者的相似度,但问题是,当query和title长度计算差距很大的时候,计算准确性就会受到影响,而分成两个指标,则能够充分表现两者的相似性,当然具体用哪种其实还是要看具体场景的,有的时候这种无偏向性对效果优化还是有用的,但是有的时候其实会影响最终效果。
来看个例子,query是“我昨天新买的手机,今天怎么就不能开机了”,title是“手机不能开机”,这里可以,ctr无疑就是1,当然cqr就比较低了,但是我们可以用ctr作为后续的排序特征或者过滤条件。
优缺点
感觉有些东西想说但是没说出来,直接总结一下这个方案的优缺点吧,以便大家进行方案选择吧,这个优点,是相对于常见的语义相似度模型而言的。
首先说优点:
能够体现文本层面的相似度,在一些领域下体验比较好。
性能比语义相似度模型好很,所以是一个简单轻快的模型。
无监督,词权重的话用语料就可以训练了。
效果稳定可追踪。
当然,还是有缺点的。
文本层面的匹配无法体现语义,同义词、说法之类的无法体现。
对切词敏感,类似“充不进去电”和“充电”就完全匹配不上。
应用
有这些有缺点,其实我们就可以考虑这个相似度该怎么用了:
用于过滤一些肯定不对的答案。
无标注数据下,这个指标可以作为排序的指标,对启动项目挺重要的。
作为排序特征,保证结果在文本层面还是比较接近的。
当然,在一个比较完整的搜索或者是检索式对话的系统里,其实这种文本相似度类的特征还是非常有收益的,结合语义相似度还是会有一些比较稳定的收益。
小结
东西其实不难,却是非常实用的技能,但是在应用的过程中能够想到的人其实很少,但有用的东西我们学起来也挺好。
原文标题:【文本匹配】cqr&ctr:文本匹配的破城长矛
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
自然语言处理
+关注
关注
1文章
618浏览量
13554 -
nlp
+关注
关注
1文章
488浏览量
22034
原文标题:【文本匹配】cqr&ctr:文本匹配的破城长矛
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
如何使用自然语言处理分析文本数据
图纸模板中的文本变量
如何在文本字段中使用上标、下标及变量

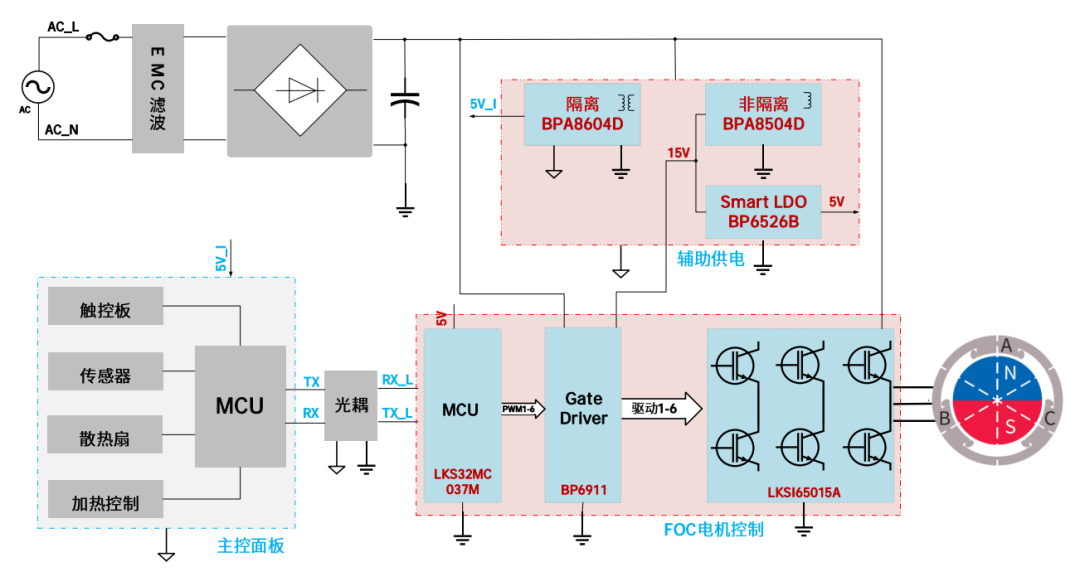
直流无刷破壁机解决方案
tas5548输入全音量的i2s数据会破音,为什么?
正常音量信号输入tas5548后破音的原因?怎么解决?
玩具反斗城使用OpenAI的Sora文本转视频工具制作"品牌电影"
卷积神经网络在文本分类领域的应用

华为射频天线口匹配设计及调试指导

输电线路防外破措施:毫米波雷达防外破在线监测装置|精准测距
快速全面了解大模型长文本能力





 工商网监
工商网监
评论