 AI优化的FPGA和GPU的芯片级对比
AI优化的FPGA和GPU的芯片级对比
本部分,我们就跟随作者一起看看Intel Stratix10 NX和Nvidia在这个领域的利器T4以及V100之间的对比,过程分为芯片级对比以及系统级对比。
本部分一起先来看看芯片级对比
首先来看下我们的GPU对手——Nvidia T4和V100分别有320个和640个张量核(专门用于AI工作负载的矩阵乘法引擎)
Nvidia Tesla T4
Nvidia Tesla V100
下面表格总结了与Stratix10 NX和这些同代工艺GPU的关键指标对比。 就die尺寸来说,V100是Nvidia最大的12nm GPU,几乎比T4大50%,而Stratix10 NX比两种GPU都小。
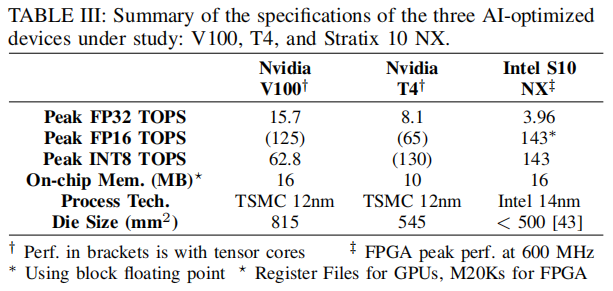
首先,文章使用GPU最擅长处理的工作负载:通用矩阵乘(GEMM)来跑GPU的benchmark(什么是GEMM请移步https://spatial-lang.org/gemm),为了测量最佳的GPU性能,对每个器件使用最新的library,这些库不会出错,并且分别在使用和不使用张量核的情况下测试性能。对于fp32和fp16实验,分别使用CUDA10.0和10.2的CuBLAS库进行V100和T4。对于int8,我们使用CUDA10.2中的cuBLASLt库,这样可以比cuBLAS库获得更高的int8性能。文章使用Nvidia的官方(高度优化)的cuDNN kernel来处理DL工作负载,并且分别对V100和T4使用了从cuDNN7.6.2和7.6.5。 (cuBLAS API,从cuda6.0开始;cuBLASLt API,从cuda10.1开始)
cuDNN库不支持int8计算kernel,但它们支持将所有模型权重保存在片上内存中。对于每个工作负载、问题大小和序列长度,文章在两种GPU上运行了所有可能的配置组合,如精度{fp32、fp16、int8}、计算样式{persistent、non-persistent}、张量核心设置{enable、disable}。然后,选择最佳的性能,来和Stratix10 NX的NPU进行比较。 这里因为是芯片级对比,所以只考虑了芯核的计算效率,不包括任何初始化、芯核启动或主机-GPU数据传输开销。
下图给出了T4和V100 GPU上fp32、fp16和int8精度的GEMM benchmark测试结果。结果表明,相对于张量核禁用情况(蓝线),启用张量核(红线) 可以显著提高GPU在GEMM上的性能。
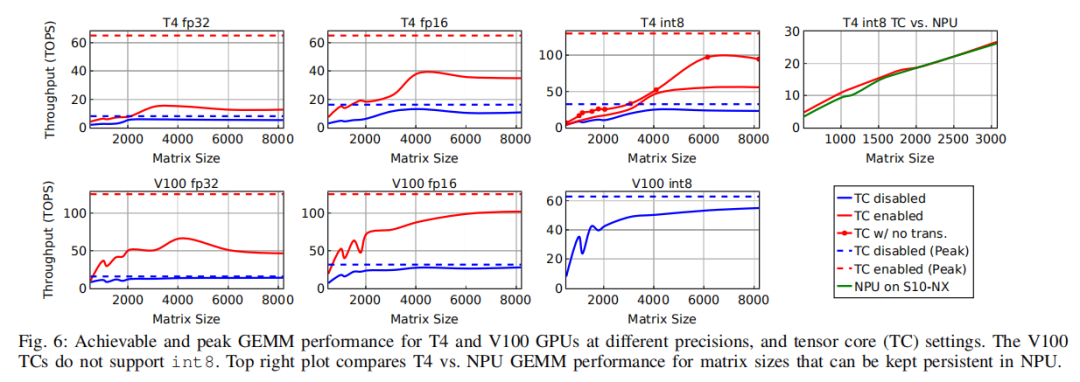
然而,一个普遍的趋势是,张量核虽然是为GEMM设计的,但在矩阵大小为2048或以下情况时的利用效率明显不如峰值情况(红色虚线)。因此要实现高利用率,除非工作负载中的矩阵大小非常大,而这在实际DL工作负载中并不常见。T4和V100上的张量核都不支持fp32的精度,而是在执行乘法运算之前,将fp32数据转换为fp16。相对于纯fp16 GEMM,这种数据转换开销降低了张量核性能。另一个有趣的情况是,当T4张量核在int8模式下工作时,它们需要将输入矩阵从标准的行/列主要格式转换为特定于张量核的布局。因此,即使在处理非常大的8192×8192矩阵时,在张量核(没有标记的红线)上实现的int8性能还不到峰值性能的45%。
为了更好地理解这种数据转换的开销,文章还进行了一个额外的实验,在这个实验中,对张量核进行了特殊布局(带有标记的红线)。即使不算矩阵布局变化的开销,对于4096×4096及以下的矩阵大小,张量核利用率也小于40%,在6144×6144矩阵中利用率达到最高为72%。
下面来看看FPGA上的情况,上图(Fig.6)的右上角那张图比较了Stratix10 NX上的NPU性能与具有int8张量核的T4 GPU的性能。为了公平地比较,文章禁用了NPU两个输入矩阵其中一个的矩阵布局变换,只保留了对另一个输入以及输出矩阵的布局变换(因为NPU以标准格式使用和生成这些矩阵)。
虽然NPU是为矩阵向量运算而设计的,但它在GEMM工作负载上仍然实现了与T4相似的性能,其矩阵大小从512到3072不等(最大的矩阵可以fit进片上BRAM)。
最后,一起看看顶级FPGA和GPU的PK结果。下图(Fig.7)将文章在Stratix10 NX上增强型NPU的性能与T4和V100的最佳性能进行比较。对于比较小的batch-3和batch-6情况,FPGA性能总是显著高于两个GPU。FPGA在batch-6(其设计为:双核batch-3)中表现最好,平均性能分别是T4和V100的24.2x和11.7x。
与batch-6相比,FPGA在batch-3上的性能较低,因为两个核中的一个完全空闲。然而,它仍然比T4和V100分别平均快了22.3x和9.3x。在batch size高于6时,如果batch size不能被6整除,则NPU可能不能被充分利用。例如,在batch size为8、32和256的情况下,NPU最多可以达到其batch-6性能的67%、89%和99%,而batch size为12、36和258(上图中的虚线所示)可以达到100%的效率。在32输入的中等batch size情况下,NX仍然比T4具有更好的性能,并且与V100性能相当。
即使在比较大的batch size情况下,NX的性能也比T4高58%,只比die size更大(大将近一倍)的V100低30%。这些结果表明,人工智能优化的FPGA在低batch实时推理中不仅可以实现比GPU好一个数量级的性能,而且可以在放宽延迟约束下的高batch推理中和GPU匹敌。上图(Fig.7)中的右下角图总结了不同batch size情况下NX相对于CPU的平均加速情况。
上图(Fig.7)中的右上角图显示了与不同batch大小下的两个GPU相比,NX的平均利用率。NX在batch-6中的平均利用率为37.1%,而T4和V100分别仅为1.5%和3%。GPU张量核并非直接互连,它们只能接收来自本地核内寄存器文件的输入。因此,每个GPU张量核都必须发送它的partial result到全局内存中,并与其他张量核同步,以结合这些partial result。然后GPU从全局内存中读取组合好的矢量来执行进一步的操作,如激活函数(activation functions)。
较高的batch size可以摊销这种同步延迟,但即使在batch-256情况下,T4和V100的利用率分别只有13.3%和17.8%。 另一方面,FPGA在架构上也更具优势,其在张量块之间有专用的用来做减法的互连, FPGA的可编程布线资源还允许将MVU tile和矢量单元级引擎级联起来进行直接通信,减少了像GPU中那样必须通过内存通信的情况。
综上可以看到,FPGA依靠架构优势和超高的资源利用率,在AI性能PK上对GPU形成了强劲挑战。下一篇,我们再来一起看看从系统角度,FPGA和GPU的对比情况以及功耗方面的分析。
原文标题:读《超越巅峰性能:AI优化的FPGA和GPU真实性能对比》:芯对芯
文章出处:【微信公众号:FPGA之家】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
FPGA
+关注
关注
1629文章
21735浏览量
603195 -
AI
+关注
关注
87文章
30839浏览量
268997
原文标题:读<超越巅峰性能:AI优化的FPGA和GPU真实性能对比>:芯对芯
文章出处:【微信号:zhuyandz,微信公众号:FPGA之家】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

行业首个芯片级游戏威廉希尔官方网站 ,OPPO「风驰游戏内核」正式亮相一加游戏大会

一加将首发芯片级游戏威廉希尔官方网站 带来极致手游体验
NPU与GPU的性能对比
瑞沃微:一文详解CSP(Chip Scale Package)芯片级封装工艺
概伦电子宣布正式推出芯片级HBM静电防护分析平台ESDi
FPGA芯片你了解多少?
FPGA在深度学习应用中或将取代GPU
在芯片级的薄膜电阻和板级的厚膜电阻都是如何进行修调呢?

Vision Pro芯片级内部拆解分析

FPGA、ASIC、GPU谁是最合适的AI芯片?






 工商网监
工商网监
评论