 基于YUV颜色空间的阴影去除算法在行人检测与跟踪中的应用
基于YUV颜色空间的阴影去除算法在行人检测与跟踪中的应用
行人是城市交通系统的主要参与者,保障行人安全和减少其对机动车的干扰是城市交通系统建设的重要目标,因此对行人交通的研究也越来越受到重视。行人交通研究的主要问题包括行人检测、目标跟踪和行为分析。基于视频的行人检测与传统的红外检测、GPS检测、激光检测等方法相比,具有不破坏路面、维护方便、实时性好、可检测的参数多等优点,成为实时交通信息采集和处理威廉希尔官方网站 的发展方向。
视频图像中的阴影会影响行人的检测与跟踪,因为阴影的存在会造成检测目标的变形、合并、甚至丢失,使得目标定位及计数不准确。近年来,科研工作者对图像中的阴影去除问题进行了大量研究,在这些研究方法中,考察的图像特征主要有三种:光谱特征、空间特征和时间特征。光谱特征针对像素点,如灰度值、颜色信息等,根据当前图与背景图的色差、亮度差值等判断像素点是否为阴影,或者对图像进行变换得到光照无关图进而去除阴影;空间特征是针对某一区域或某一帧图像,根据检测到的图像的轮廓、纹理、边缘等信息判断是否为阴影,如利用图像的轮廓特征,找到目标与阴影的边界线,对本体和阴影粗分,再建立阴影像素的高斯模板进行细分,既减少了计算量又能达到较好效果;时间特征一般都是与前两种特征结合使用,可以用于对阴影方向或运动速度的估算等,以进一步提高阴影去除效果。
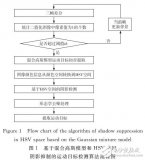
本文提出一种新的基于YUV颜色空间的阴影去除算法,因为很多摄像头的输出信号采用YUV颜色空间,与基于RGB颜色空间的处理方法相比,省去了图像颜色空间转换的步骤,能提高处理速度。在图像特征上,本文结合像素点的光谱特征与图像整体的空间特征,首先通过亮度差和色差对像素点进行判断,再利用目标本体与阴影只相接不相交的空间特征,对去除结果进行修正,使其阴影去除效果更好。同时,为了使算法适应光照、场景等的变化,采用模糊神经网络进行目标本体与阴影的分类,用遗传算法对网络参数和权值进行自适应调整,以提高算法的鲁棒性。
1 YUV颜色空间
在色彩学上,为了可以准确定量地描述颜色,将色彩定义为三大属性:“Y”表示明亮度,即灰度值;“U”和“V”表示色度,作用是描述图像色彩及饱和度,用于指定像素的颜色。根据美国国家电视制式委员会NTSC制式的标准,白光的亮度用Y来表示,色差U、V由B-Y、R-Y按不同比例压缩而成,与红、绿、蓝三色光的关系可用式(1)描述,这也是常用的转换公式。YUV到RGB的转换公式则如式(2)所示。

式中,R、G、B的取值范围均为0“255。通常摄像机的数据以RGB、YUV或YCrCb的格式输出。采用YUV颜色空间的重要性是它的亮度信号Y和色度信号U、V是分离的。目前有很多种颜色空间可以将图像的色度分量和亮度分量区分开来,如HSV颜色空间,但是这种转换较为复杂,对于大型图像非常耗时,并且在亮度值和饱和度较低的情况下,采用HSV颜色空间计算出来的H分量是不可靠的。
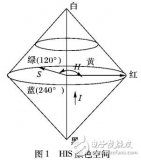
在YUV颜色空间中,如果只有Y信号分量而没有U、V信号分量,则这样表示的图像就是黑白灰度图像。除去亮度信号后,由U和V单纯表现出色度。因此,如果要将U与V色差信号用色相及饱和度来表示,必须从含有三维空间的色点P投影到U-V平面的P′点,如图1(a)所示。U-V平面投影法在受到不稳定光源亮度的扰动时,对于目标色度有较大的精确性且不易辨识错误,但是当光源色温变化过大时,其饱和度和色相的增减变化不易掌握。因此,如果需要判定两个任意色点是否为同一色度时,必须确定其色相与饱和度都是相等的。如图1(b)所示,对两个色点P1与P2,当其与U轴的夹角α1=α2时,表示色相相等;当其与原点的距离L1=L2时,表示饱和度相等。当两者都相等时,表示色度完全相同。
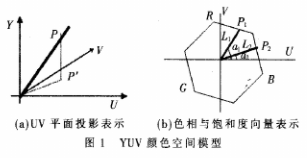
对于光源亮度的不稳定因素,只要光源亮度不是极值(极亮或极暗),对于相似颜色,如深蓝色和蓝色,就有相近的色度关系。对运动目标本体和阴影,也有相近的色度,但亮度值差别较大,可通过计算当前图与背景图之间的亮度差值和色差来进行阴影去除。

上述准则在应用中,要注意Ymin、ε和Δα等阈值的选取,因为这对判断结果的影响较大。要找到合适的阈值[9],需要对视频资料进行大量的仿真实验,这需要花费很长时间,而且根据现有资料得到的阈值不能根据场景、光照等的变化自适应进行调整,实用价值不大。
针对上述问题,将模糊神经网络融入到目标本体与阴影的分类中是很好的解决方法。它利用神经网络的自学习能力和自适应能力来调整模糊规则和隶属度函数,通常对神经网络的训练采用BP算法,但是BP算法具有收敛性依赖初始条件,容易陷入局部极小值等问题。因此,本文采用遗传算法优化模糊神经网络的结构和参数,并自动获得最优的模糊规则,使网络能自动适应场景与光照的变化。
2.3 模糊神经网络
模糊神经网络的结构如图2所示。
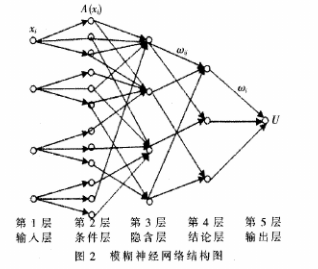


式中,ui表示对第i个模糊子集的隶属度,zi表示输出结论的支集值。最后,对输出结果进行二值化表示,1表示目标本体,0表示阴影。当结果小于0.05时,认定为阴影;结果大于0.95时,认定为目标本体,当结果在0.05”0.95之间时,认为无法判断。
2.4 网络自适应优化
用遗传算法对模糊神经网络的结构和参数进行优化。网络的结构优化指确定第3层节点数、第3层和第2层的连接数、以及第3层和第4层的连接数和连接权值。网络的参数优化包括输入变量的隶属度函数的中心参数和宽度参数、输出变量的隶属函数支集值。
种群的每个个体由网络结构和网络的输入隶属度函数参数和结论参数组成,其长度为结构基因长度+参数基因长度。结构基因中“连接”采用二值的编码,“0”表示没有连接,“1”表示有连接,连接权值ωji用(0“1)之间实数编码。输入的隶属度参数Cji和bj、结论参数zi采用实数编码。一个染色体对应一种模糊神经网络结构及其参数。初始种群中包含着对应于最大节点数及输入变量和输出变量在其变化范围内均匀划分模糊子集的个体,其余个体随机产生。将根据经验得到的规则集及输入输出模糊划分对应的向量选入初始种群。
遗传操作包括复制、交叉、变异。为简化运算实现实时处理,本文仅采用变异操作。二值编码按一定的概率将控制基因串中的位从0变异为1,或者从1变异为0。实数编码按下式突变:

2.5 空间特征
考虑到图像中阴影和目标本体相接但互不相交,对于不能判断的像素及初步识别结果,按下述规则进行判断和修正:(1)如果周围像素点多数为“阴影”,则该点是“阴影”。(2)如果周围像素点多数为“目标”,则该点是“目标”。(3)如果周围像素点多数是目标而被判断为“阴影”,则改判断为“目标”。(4)如果周围像素点多数是阴影而被判断为“目标”,则改判断为“阴影”。这里的多数是指相邻8个像素点中5个以上。
3 实验结果和分析
图3、图4是室外拍摄的视频序列的处理结果,视频序列共2 571帧,单帧图像大小为354×288,图3是第154帧图像,图4是第363帧图像。

童车在图3中作为背景被提取出来,而在图4中成为前景。与图3相比,图4中光照有较大变化,图3(d)、图4(d)、图5(d)表明模糊神经网络分类器能有效地进行阴影去除。由图5(d)可见,通过阴影去除,行人能被分隔开来,这样有利于提高视频检测的准确率。
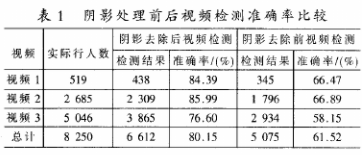
表1是对在不同路口拍摄的行人视频进行行人检测的结果,进行阴影去除后视频检测的平均准确率由61.52%提高到80.15%。
本文给出了一种新的阴影去除算法,该算法以YUV颜色空间为基础,用模糊神经网络分类器识别对像素点提取的光谱特征是否为阴影,网络的结构和参数采用遗传算法进行实时更新,最后结合运动目标与阴影的空间特征对分类结果进行修正。实验表明,该方法能适应光照、场景的变化,通过阴影去除能明显提高行人视频检测的准确率。
本文关于行人视频检测的研究尚处于起步阶段,对视频检测中的遮挡问题、运动描述和行为理解问题还在进一步研究中。
责任编辑:gt
-
神经网络
+关注
关注
42文章
4771浏览量
100723 -
RGB
+关注
关注
4文章
798浏览量
58467
发布评论请先 登录
相关推荐
基于稀疏编码的迁移学习及其在行人检测中的应用
基于FPGA的rgb与yuv颜色空间转换
基于车载视觉的行人检测与跟踪方法
基于ACF算法的行人检测领域的研究

基于颜色和空间融合的显著图算法
基于暗原色先验原理的颜色空间转换算法去除图像浓雾
颜色空间分布的多摄像机行人匹配
基于YUV颜色空间的行人视频检测阴影去除算法的实现


基于颜色感知背景的文档图像阴影去除






 工商网监
工商网监
评论