 关于多任务学习如何提升模型性能与原则
关于多任务学习如何提升模型性能与原则
提升模型性能的方法有很多,除了提出过硬的方法外,通过把神经网络加深加宽(深度学习),增加数据集数目(预训练模型)和增加目标函数(多任务学习)都是能用来提升效果的手段。(别名Joint Learning,Learning to learn,learning with auxiliary task.。..等)
对于人类来说,我们往往学会了一件事,是能够触类旁通,举一反三的。即其他不同任务的经验性,能够带来一些有用的信息,这是多任务学习的出发点。但如果处理多任务还是用single-task learning的话(类似bagging),模型会默认为每个任务是独立的,没有关联性的,所以每个模型的参数都是独立进行的。这样做的缺点在于:
训练数据有限,所以模型并不具有很好的泛化性能
不考虑任务之间的相关性,缺乏对不同模型之间共享信息的挖掘,使得模型训练过程中性能下降
Multi-Task Learning(MTL)多任务学习实质上是一种迁移机制,如何让模型能够同时解决多种问题,从而提高泛化准确率、学习速度和能力,模型的可理解性。特别是如何使用与其他任务的“相关性”与“差异性”,通过多个任务训练并共享不同任务已学到的特征表示,减轻对特定任务的过度拟合,从正则化效果中获益,提升最终的性能,使学习的嵌入在任务之间具有通用性。
多任务学习的构建原则
理解建模任务之间的相关性,以构建合适的多任务方案。
同时对多个任务的模型参数进行联合学习以挖掘不同任务的共享信息。
但需要同时考虑不同任务会存在的差异性,如何提高模型对不同任务的适应能力。
为什么多任务是有效的?
可增加训练样本,且不同任务的噪音不同,同时学习多个任务能得到更通用的表达
可以通过其他任务来判断学习到的特征是否真的有效
对于某个任务难学到的特征,可以通过其他任务来学习
多任务学习倾向于让模型关注其他模型也关注的信息表达
某种程度上可以视为正则化
常用多任务学习的主要方式
基于参数的共享,如神经网络隐层参数共享,然后上层得到多个特征完成多种任务以达到联合训练的目的,即loss里面组合多个。
对于loss的组合的权重设置可以分为手工调整,Gradient normalization(希望不同任务loss的量级接近,纳入梯度计算权重,优点是可以考虑loss的量级,缺点是每一步都要额外算梯度)。Dynamic weight averaging,DWA希望各个任务以相近的速度来进行学习(记录每步的loss,loss缩小快的任务权重会变小,缺点是没有考虑量级)。Dynamic Task Prioritization,DTP希望更难学的任务可以有更高的权重。Uncertainty Weighting,让“简单”的任务权重更高(确定性越强的任务权重会大,而噪声大难学的任务权重会变小)。对于loss的平衡挺讲究的,也算是调参师需要掌握的东西吧,有空再新写文章整理。
基于正则化的共享,如均值约束,联合特征学习等。比如使用低秩参数矩阵分解,即假设不同任务的参数可能会共享某些维度的特征,那么每个任务的参数都接近所有任务平均的参数来建模任务之间的相关性,即在loss中加入这样的正则化来约束参数:
所以多任务的优点在于它具有很好的泛化性能,对于有些任务的数据不足问题,也能借助其他任务得到训练,另外它还能起到正则的作用,即很难使某个任务过拟合以保证整个模型的泛化性能。
而其困难在于如何更好的对每个任务分配权重(已经有人有NAS做了。..)以使其鲁棒性最强,同时如何兼顾特征共享部分和任务的特点表示,避免过拟合或者欠拟合是值得研究的。
除了一般处理多任务都是一个可学习的alpha来控制外,本篇文章将整理几篇多任务学习的论文。
Single-Level MTL Models
单层主要有以下几种方式:
「Hard Parameter Sharing」:不同任务底层共享,然后共不同任务各自输出。当两个任务相关性较高时,用这种结构往往可以取得不错的效果,但任务相关性不高时,会存在负迁移现象,导致效果不理想。
「Asymmetry Sharing(不对称共享)」:不同任务的底层模块有各自对应的输出,但其中部分任务的输出会被其他任务所使用,而部分任务则使用自己独有的输出。哪部分任务使用其他任务的输出,则需要人为指定。
「Customized Sharing(自定义共享)」:不同任务的底层模块不仅有各自独立的输出,还有共享的输出。
「MMoE」:底层包含多个Expert,然后基于门控机制,不同任务会对不同Expert的输出进行过滤。
「CGC」:这是PLE的结构(图自腾讯在RecSys2020最佳长论文,Progressive Layered Extraction (PLE): A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations),他的不同之处在于学习一个个性和共性两方面的信息,然后再用不同的gate来控制。
Multi-Level MTL Models
「Cross-Stitch Network」:用参数来控制不同任务间共享的特征
「ML-MMoE」:MMoE的多级结构
「PLE」:多层萃取(基于CGC)
MMoE(Multi-gate Mixture-of-Experts)论文:Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts
MMoE应该是实际上用的比较多一个架构了,想主要整理一下这个。
这篇文章是对多任务学习的一个扩展,通过门控网络的机制来平衡多任务。所谓“平衡”是因为多任务学习中有个问题就是如果子任务之间的差异性太大了,多任务模型的效果会很差,那么如何平衡不同的任务呢?MMoE主要有两个共享:
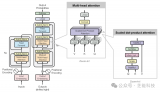
图a,使用shared-bottom网络,多个上层任务共用底层网络。
图b,多个独立模型的集成方法MoE,即每个expert network都可以认为是神经网络,公共一个门控网络(One-gate MoE model),最终的输出是所有experts的加权和。
图c,MMoE,每个任务使用单独的gating networks。即每个任务的gating networks通过最终输出权重不同实现对experts的选择性利用。不同任务的gating networks可以学习到不同的组合experts的模式,因此模型考虑到了捕捉到任务的相关性和区别。
通过这种multi-gate的结构能够缓解任务间差异大的情况。
Multi-task Learning in LM语言模型是天然无监督的多任务学习。而且鉴于目前针对BERT的改进很多(包括BERT-large等版本)都是增加了数据量,计算能力或训练过程。
比如RoBERTa,精细调参,为了优化训练程序,从BERT的预训练程序中删除了结构预测(NSP)任务,引入了动态掩蔽,以便在训练期间使掩蔽的标记发生变化。
比如DistilBERT学习了BERT的蒸馏版本,保留了95%的性能,但只使用了一半的参数。具体来说,它没有标记类型和池化层的嵌入,只保留了谷歌BERT中一半的层(当然ALBERT也是等)。
MT-DNN与ERNIE2.0。这两篇论文的多任务学习很有意思,接下来主要整理这两篇文章。
MT-DNN论文:Multi-Task Deep Neural Networks for Natural Language Understanding
MT-DNN是结合了至少4种任务的模型:单句分类、句子对分类、文本相似度打分和相关度排序等等。
「单句分类」:CoLA是判断英语句子是否语法合适、SST-2是电影评论的情感(正面or负面)。
「文本相似度」:STS-B对两句话进行文本相似度打分
「句子对分类」:RTE和MNLI是文本蕴含任务(推理两个句子之间的关系,是否存在蕴含关系、矛盾的关系或者中立关系),QQP和MRPC是判断两句话是否语义上一致,等价。
「相关性排序」:QNLI斯坦福问答数据集的一个版本,虽然是二分类问题,此时变成一个多排序问题,使更接近的答案排得更加靠前。
在MT-DNN的多任务学习中,也是低层的特征在所有任务之间共享,而顶层面向丰富的下游任务。从模型结构上,从底向上的shared layers是Transformer逐步的过程,用于生成共享的上下文嵌入向量(contextual embedding layers),然后完成四种任务的预测。
ERNIE2.0论文:ERNIE 2.0: A Continual Pre-Training Framework for Language Understanding
ERNIE2.0的贡献主要有1 通过大型语料库+先验知识。2,多任务学习逐步更新 ERNIE 模型。
「序列性多任务学习」。使模型能够学习到词汇,语法,语义信息。不同于持续学习和多任务学习,序列多任务学习在引入新的训练任务时,先利用之前学习到的参数对模型进行初始化,再同时训练新任务和旧任务。
「定制和引入了多种预训练任务」。侧重词汇的任务(mask,大写字词预测,字词-文章关系),侧重结构/语法的任务(词语重排序,语句距离),侧重语义的任务(文章关系任务,信息检索相关性任务)。如下图,首先主要使用的任务有:
「Knowledge Masking Task、Capitalization Prediction Task和Token-Document Relation Prediction Task」。Knowledge Masking Task是预测被masked掉的短语和命名知识实体以学习到局部语境和全局语境的依赖关系信息。Capitalization Prediction Task是首字母大写预测,首字母大写的词往往有特殊的功能。Token-Document Relation Prediction Task预测段中的token是否出现在原始文档的其他段(segment)中,即捕获高频词或线索词。
「Sentence Reordering Task和Sentence Distance Task」。Sentence Reordering Task句子重排任务是为了学习句子之间的关系。Sentence Distance Task通过文档级的信息学习句子之间的距离。
「Discourse Relation Task和IR Relevance Task」。Discourse Relation Task引入2个句子之间语义或修辞关系的预测任务。IR Relevance Task学习短文本在信息检索中的相关性。
这篇文章比较有趣的就是这个多任务连续增量学习,或持续学习(Continual learning)了,它致力于对数个任务按顺序依次训练模型,以确保模型在训练新任务时候,依旧能够记住先前的任务。正如人类能够不断地通过学习或历史经验积累获得信息,从而有效地发展新的技能。
具体关于连续增量学习的对比,第一个是如何以连续的方式训练任务,而不忘记以前所学的知识;第二个是如何更有效地学习这些预训练任务。
「Continual Learning」。在训练的每一个阶段仅通过一项任务来训练模型,如训练任务A,在训练任务B,一直到训练任务Z,但是其缺点是会忘记先前学习的知识,导致最后的结果会更加偏向靠后的任务。。
「Multi-task Learning」。是普通的MTL,即所有任务在一起进行多任务学习,即同时训练A,B..Z期间不做交互最后做集成。缺点是训练完的模型只能处理这些任务,如果出现了比较新的任务,比较大的概率需要重头开始训练。
「Sequential Multi-task Learning」。当有新任务出现时,先使用先前学习的参数来初始化模型,并同时训练新引入的任务和原始任务,如先训练A,再训练A,B,再训练A,B,C,如图中的金字塔形状,当有新任务出现时,它也能够快速反应做调整。
除了这种,其实还可以先(A)(B)(C)训练,再(A,B)(B,C)(A,C),最后再(A,B,C)这种方式。有点像我们做题往往会先做单项训练,再综合训练。
编辑:lyn
-
多任务
+关注
关注
0文章
18浏览量
9077 -
深度学习
+关注
关注
73文章
5507浏览量
121266
原文标题:【多任务】如何利用多任务学习提升模型性能?
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
《具身智能机器人系统》第7-9章阅读心得之具身智能机器人与大模型
NPU威廉希尔官方网站 如何提升AI性能
【《大语言模型应用指南》阅读体验】+ 基础知识学习
【大语言模型:原理与工程实践】大语言模型的应用
智能驾驶大模型:有望显著提升自动驾驶系统的性能和鲁棒性
【大语言模型:原理与工程实践】大语言模型的评测
【大语言模型:原理与工程实践】大语言模型的预训练
【大语言模型:原理与工程实践】大语言模型的基础威廉希尔官方网站
【大语言模型:原理与工程实践】核心威廉希尔官方网站 综述
【大语言模型:原理与工程实践】揭开大语言模型的面纱
昆仑万维天工3.0大模型性能显著提升,天工SkyMusic音乐模型亮相
OpenVINO™协同Semantic Kernel:优化大模型应用性能新路径






 工商网监
工商网监
评论