 一种处理多标签文本分类的新颖推理机制
一种处理多标签文本分类的新颖推理机制
研究动机
多标签文本分类(multi-label text classification, 简称MLTC)的目的是在给定文本后要求模型预测其多个非互斥的相关标签。该任务在许多自然语言处理任务上都有体现。如在表1中,需要给该文档打上标签:basketball、NBA、sport。
表1多标签文本分类的例子
| 文本 | This article is about a game between Houston Rockets and Los Angeles Lakers. |
| 相关标签 | basketball, NBA, sport |
| 不相关标签 | football |
一种处理MLTC的简单方法是将其转换为多个独立的二分类问题。该方法被称为BinaryRelevance (BR),由于其简单性而被大规模使用。但该方法的弊端也十分明显,即该方法完全忽略了标签之间的相关信息。直觉上,知道一些标签——如上例中的basketball及NBA——会使得预测其他标签(如sport)更加简单。研究者指出对于多标签分类任务而言,有效利用标签之间的相关性是有益的、甚至是必要的。为此,涌现出许多利用标签关系的算法,其中最知名的就是算法Classifier Chains(CC)。该算法将多个二分类器串联起来,其中每个分类器使用之前分类器的预测结果作为额外的输入。该方法将潜在的标签依赖纳入考虑,但该问题的最大缺陷在于不同的标签顺序会产生天壤之别的性能。同时,CC算法的链式结构使得算法无法并行,在处理大规模数据集时效率低下。
近年来,也有学者将标签集合视作标签序列,并使用基于神经网络的端到端模型(seq2seq)来处理该任务。相较于CC预测所有标签,这类seq2seq的模型只预测相关标签。因此该类模型的决策链条长度更短,性能更优。但这类模型的性能强烈依赖于标签的顺序。在多标签数据集中,标签本质上是无序的集合,未必可以线性排列。学者们指出不同的标签顺序对于学习和预测有着重大影响。举例来说,对于表1中的例子,如果标签序列以sport开始,则对于预测其他相关标签的帮助不大。
02
—
解决方案
为了处理上述问题,我们提出了Multi-Label Reasoner(ML-Reasoner),一个基于推理机制的算法。ML-Reasoner的框架如图1所示,我们为每一个标签分配一个二分类器,它们同时预测所有标签以满足标签的无序性质。这样的话,ML-Reasoner可以同时计算每一个标签相关的概率。例如在处理上例时,ML-Reasoner可能认为标签NBA相关的概率为0.9,basketball的为0.7,sport为0.55,football为0.3.这样,ML-Reasoner就完全避免依赖标签顺序。同时为了有效利用标签的相关性,我们设置了一种新颖的迭代推理机制,即将上一轮对所有标签相关的预测作为下一次迭代的额外特征输入。这种方法使得ML-Reasoner可以在每一轮的迭代中完善预测结果。举例来说,考虑到标签NBA与basketball相关的概率较高,模型可以在后续迭代中,将标签sport的概率调高。
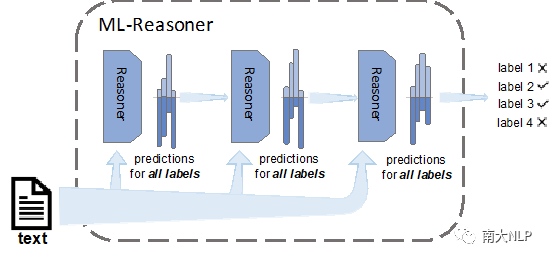
图1 Multi-Label Reasoner整体框架图
具体到Reasoner的实现,我们将其划分为五个组件,其相关交互关系见图2。
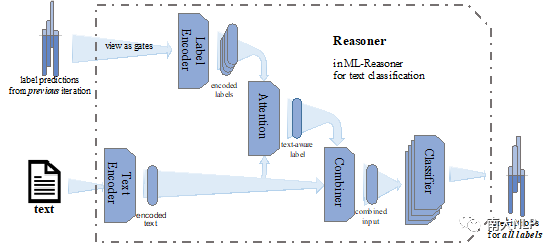
图2多标签文本分类的Reasoner模块
- Text Encoder将词语序列转换为稠密的向量表示,主要负责抽取文本特征;
- Label Encoder将上一轮次所有标签的相关概率转换为相应的标签表示;
- Attention模块负责计算文本与不同标签之间的相关性;
- Combiner则将文本的原始特征与标签特征进行整合;
- 具有相同结构但不同参数的Classifier则预测各个标签的相关性。
至于损失函数,我们选择了Binary Cross Entropy (BCE)。更具体的设置请参见原文。
03
—
实验
我们在两个常用的多标签文本分类数据集Arxiv Acadmeic Paper Dataset(AAPD)及Reuters Corpus Volum I (RCV1-V2)上进行了实验。AAPD数据量更少、标签密度更大,分类难度更大。评价指标则选用了hamming loss,micro-precision,micro-recall及micro-F1;其中hamming loss越低越好,其他则越高越好。至于基准模型,我们选用了经典模型如BR、CC、LP,也有性能优越的seq2seq模型如CNN-RNN、SGM,还有其他一些表现卓越的多标签文本分类模型如LSAN,之外也将seq2set纳入进来作为比较。seq2set使用强化学习算法来缓解seq2seq模型对于标签顺序的依赖程度。同时,为了验证ML-Reasoner在不同文本编码器上能带来的性能提升,我们分别使用了CNN、LSTM及BERT作为ML-Reasoner框架中的Text Encoder模块。实验结果如表2所示。
表2 ML-Reasoner及基准模型在两个数据集上的性能
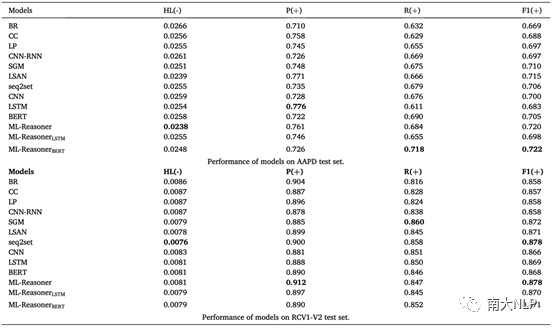
从表中可以看出,ML-Reasoner在两个数据集上均达到了SOTA水准,且在三种不同文本编码器上都能带来显著提升。
为了验证ML-Reasoner可以完全避免对标签顺序的依赖,我们随机打乱AAPD数据集的标签顺序,并进行了测试;各个模型的性能如表3所示。从表中可以看到,CC及seq2seq模型的性能受标签顺序的剧烈影响;seq2set可以显著缓解seq2seq的问题;而ML-Reasoner则完全不受标签顺序的影响。
表3各模型在标签打乱的AAPD数据集上的性能

我们也通过烧蚀实验(见图3),确定了推理机制确实是性能提升的关键。
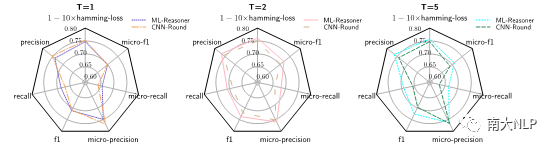
图3 ML-Reasoner(T=1,2,5)及CNN-Round(T=1,2,5)在AAPD测试集上的性能雷达图
我们也探究了迭代次数对模型性能的影响,由图4可知,进行了一次推理就可以带来显著提升;而推理次数的再次提高并不能带来更多的提升。这可能是因为模型及数据集的选择导致的。
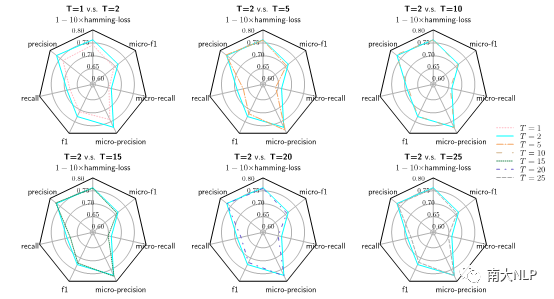
图4不同迭代轮数下的ML-Reasoner在AAPD测试集上的性能雷达图
为了进一步理解Reasoner发挥作用的机制,我们从数据集中选取了一些典型示例(见表4)。在第一个例子中,模型通过推理将相关标签math.OC添上;模型处理第二个例子时,则将无关标签cs.LO剔除;有时添加与删除的动作也会同时发生(见第三个例子)。当然,推理偶尔也会使预测结果变差(见第四、第五个例子)。
表4 AAPD测试集中一些由于推理机制预测结果出现变化的实例

为了验证上述例子的变化确实是因为考虑了标签之间的相关性,我们进一步统计模型在添加或删除某个标签时与其他标签的共现频率。从图5中,可以观察到模型往往在添加某个标签时,其共现频率(第二行)与真实共现频率接近(第一行);而删除某个标签时,其共现频率(第三行)与真实共现频率(第一行)则相差较远。
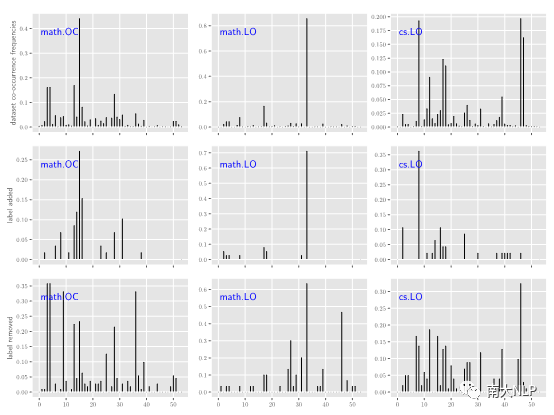
图5 AAPD标签的共现频率图
04
—
结论
在本文中,我们提出了算法ML-Reasoner。该算法可以同时预测所有标签进而避免了对标签顺序的依赖;之外,他通过新颖的推理机制利用了标签之间的高阶关系。实验结果表明了ML-Reasoner在捕获标签依赖之间的有效性;进一步的分析验证了其确实未对标签顺序产生依赖。一些经验性试验也揭示了该算法发挥作用的机制。由于ML-Reasoner未显式利用标签之间的关系,如层次结构等,如何将这些信息纳入考虑是值得进一步探索的。
原文标题:【IPM2020】一种处理多标签文本分类的新颖推理机制
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
人工智能
+关注
关注
1791文章
47243浏览量
238355 -
机器学习
+关注
关注
66文章
8414浏览量
132602 -
nlp
+关注
关注
1文章
488浏览量
22034
原文标题:【IPM2020】一种处理多标签文本分类的新颖推理机制
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
单日获客成本超20万,国产大模型开卷200万字以上的长文本处理

如何使用自然语言处理分析文本数据
BitEnergy AI公司开发出一种新AI处理方法
光学字符识别是什么的一种威廉希尔官方网站
【《大语言模型应用指南》阅读体验】+ 基础知识学习
如何训练一个有效的eIQ基本分类模型

利用TensorFlow实现基于深度神经网络的文本分类模型
llm模型有哪些格式
llm模型和chatGPT的区别
自然语言处理是什么威廉希尔官方网站 的一种应用
卷积神经网络在文本分类领域的应用
基于神经网络的呼吸音分类算法
一屏万象,场景无限: 蓝牙墨水屏标签多功能多场景应用带您领略未来

自动驾驶和多模态大语言模型的发展历程






 工商网监
工商网监
评论