 并行循环冗余校验算法
并行循环冗余校验算法
另外,FPGA LUT可编程的内容也可以参考本公众号之前的文章《【重磅干货】手把手教你动态编辑Xilinx FPGA内LUT内容》。
循环冗余码校验(CRC)是一种众所周知的错误检测代码,已广泛用于以太网,PCIe和其他传输协议中。现有的基于FPGA的实现解决方案在高性能场景中会遇到资源过度利用的问题。填充零问题和可编程性的引入进一步加剧了这个问题。在本文中,提出了stride-by-5算法,以实现FPGA资源的最佳利用。提出了pipelining go back算法来解决填充零问题。提出了使用HWICAP进行重编程的方法,以实现资源占用少且恒定的可编程性。实验结果表明,所提出的非分段架构的资源利用率与两种基于FPGA的最新CRC实现相比,降低80.7%-87.5%和25.1%-46.2%,并且所提出的分段架构具有比两种最新状态更低的资源利用率,分别降低了81.7%-85.9%和2.9%-20.8%艺术建筑。此外,保证了吞吐量和可编程性。源代码已在GitHub开源。
1. 引言
“在硬件加速计算时代,识别并卸载通用的抽象和原语,而不是单独的算法和协议。”
随着网络吞吐量的不断增加,越来越多的数据包处理任务被转移到基于现场可编程门阵列的智能网卡上,包括循环冗余校验的生成和验证。400G等威廉希尔官方网站 和即将到来的多太比特以太网要求更快的CRC计算[5],而基于FPGAs的高性能CRC计算的实现必须满足三个要求:1)降低并行化成本。Dennard缩放[2]的结束导致了提高集成电路频率的瓶颈,更高的吞吐量意味着芯片中更宽的总线。4切片和8切片算法是在[3]中提出的并行处理算法,适用于CPU,但不适用于FPGAs [4]。2)解决补零问题。并行化意味着事务的最后一个字由有效字节和填充零组成。填充零的数量是不确定的,并且使用完整的最终字的循环冗余校验计算将导致错误的结果,这被称为填充零问题。[5]说明解决这个问题的最新方案。最后一个字对应的表是以流水线的方式组织的,每个流水线步骤对应于一个二叉查找树层。介绍了一种O(n)资源利用方式。3)保持可编程性。循环冗余校验算法的可编程实现可以实现更好的可重用性;因此,无需修改电路即可支持广泛的应用。需求可以在iSCSI [6]和P4 [7]找到。使用特定的电路架构来保证可编程性[8],但不适用于FPGAs。[4]是适用于FPGAs的最先进的方案,但它需要复杂的配置电路,导致资源利用率随着总线宽度的增加而大幅提高。
上述三个要求导致了可观的资源利用率。尽管slicing[3] [4]、aggressive strides、多个流的同时处理[5]以及支持循环冗余校验加速的许多其他原则是众所周知的,但它们不能同时实现低成本、高性能和可编程性。采用英特尔循环冗余校验指令[9]的多核多插槽系统可以实现高吞吐量,但在数据包处理应用中会面临高延迟和高功耗的问题。简单地说,提出了两种算法和一种对应于这三种要求的方法,以在保证吞吐量和可编程性的情况下降低资源利用率。首先,提出了stride-by-5算法,与slicing-by-4和slicing-by-8算法相比,该算法的资源利用率降低了79.69%-79.98%。其次,提出了pipelining go back算法来解决填充零问题,这将引入一个O (log2 n)资源利用率。最后,硬件内部配置访问端口(HWICAP)用于实现动态可编程性,无论总线宽度如何,它都可以实现小而恒定的资源利用率。
本文的其余部分组织如下。第二节介绍了一些基础知识。第三节讨论了系统架构和三个创新。第四节显示了综合结果。第五节是本文的结尾。
2. 基础知识
2.1 并行循环冗余校验算法
并行循环冗余校验算法可以同时处理多个数据输入位[10]。并行处理的位数设为,这也是本文剩余部分中内部总线的宽度。并行输入数据为
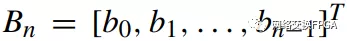 。在Bn进入之前,循环冗余校验寄存器的值为Ck。Cn+k和Ck的关系是:
。在Bn进入之前,循环冗余校验寄存器的值为Ck。Cn+k和Ck的关系是:
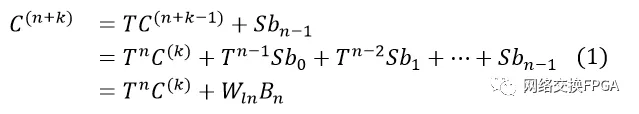


3. 设计思路
3.1 非分段系统架构
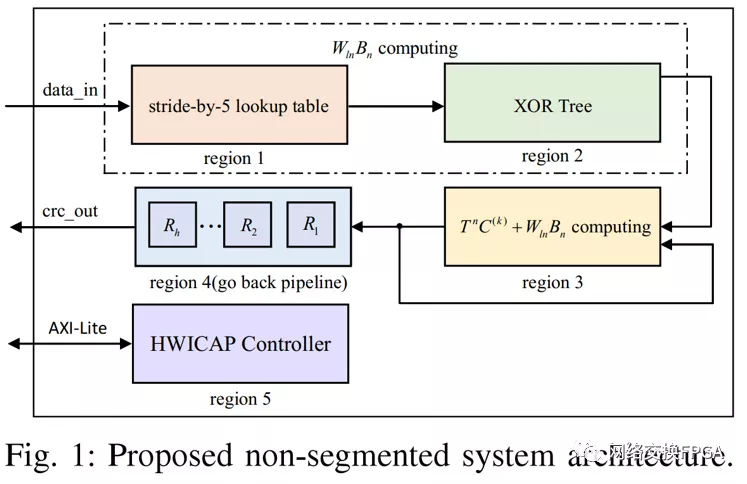
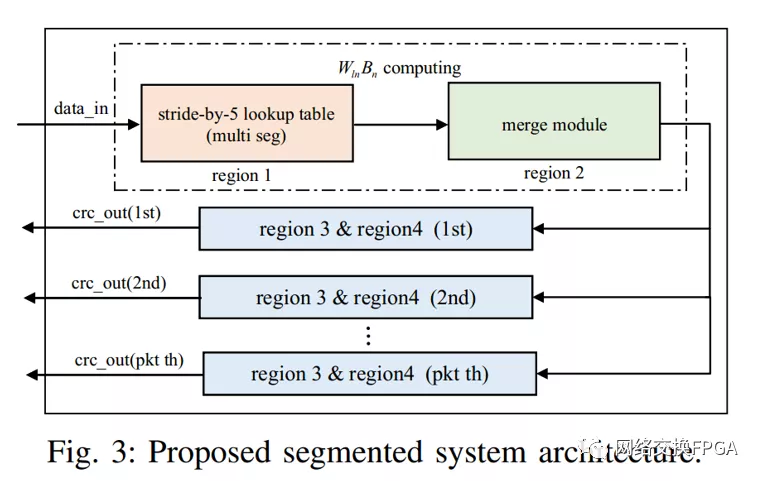
所提出的非分段系统架构如图1所示。在非分段系统架构中,单个字中应该有一个帧,分段系统架构可以同时处理多个帧[13]。区域1和2对应于(1)中WlnBn的计算。区域1消耗大部分查找表,消耗的查找表数量线性地取决于Wln的大小。在第二节中讨论的stride-by-5算法是为了减少区域1的LUT消耗而提出的。区域2通过异或树而不是一级异或函数来实现,以获得更高的性能。区域3完成了公式(1)的计算。区域4解决了填充零问题,并在第五节中提出和讨论了导致O(log2n)资源利用率的pipelining go back算法。区域5是一个HWICAP控制器,可以动态修改查找表的内容。操作程序在第四节中讨论。分段系统架构在第五节中提出。上述建议的实施细节可访问[1]。
3.2 stride-by-5算法

在这一部分中,建立了资源利用模型,证明了对于不同的总线宽度,5步是最佳的步幅(stride),stride-by-5算法在算法1中描述。顾名思义,Stride是指单个逻辑表处理的位数。逻辑表可以用FPGA LUTs实现,可以加载一个函数的真值表。例如,八输入函数定义为:
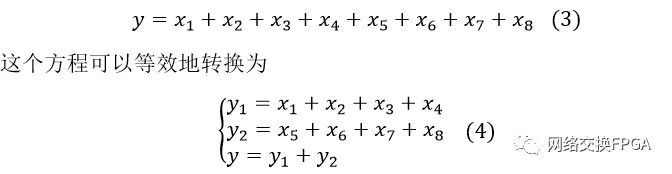
步幅为8和4的等式(3)和(4)可以分别如图2(a)和图2(b)所示实现。较小的步长意味着较小的逻辑表可以通过单个LUT或级联查找表来实现。步长等于1可以认为是FPGA实现的最佳步距吗?我们将建立资源利用模型并确定答案。
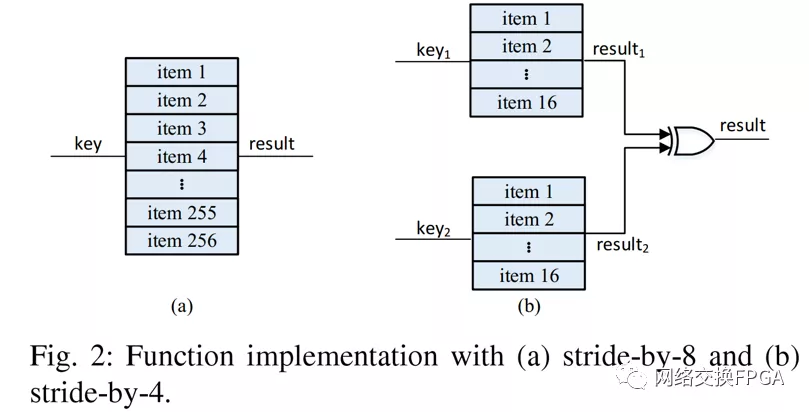

stride-by-5算法对于FPGAs中的5输入查找表是最佳的。与slicing-by-4和slicing-by-8算法中使用的stride-by-8相比,stride-by-5将资源利用率降低了79.69%-79.98%。对于具有非5输入查找表的FPGAs(Xilinx Virtex-5或Altera Stratix II之前),应使用由LUT输入数定义的步长,并应利用LUT共享机制。stride-by-5算法在算法1中描述;它在这里处理区域1中的计算,但是该算法也可以在区域3和4中使用。
3.3 Pipelining Go Back算法
在这一部分中,提出了一种资源利用率为O(log2n)的pipelining go back算法,并给出了算法的推导和描述。

q可以表示为:


3.4 通过HWICAP进行重编程
图1中的区域5代表一个HWICAP IP核,它可以动态修改查找表的内容。对于任何总线宽度,它消耗186个查找表。相比之下,逻辑资源实现的配置逻辑导致n ≥ 1024 [4]时消耗几千个lut,资源利用率随着总线宽度的增加而增加。使用HWICAP IP核重新编程的操作程序如下所述:
1. 完成初始设计,使用Vivado生成比特流,并将比特流下载到FPGA
2. 提取所用查找表的位置;
3. 当需要重新编程时,使用(1)和(12)计算查找表的新内容;
4. 将查找表的内容映射到查找表的初始值;
5. 使用HWICAP IP核的AXI Lite 接口将初始值写入查找表。
重编程方法在工程上是有用的。我们的贡献如下:
1. 我们验证了使用HWICAP IP核对循环冗余校验算法的现场可编程门阵列实现进行重新编程的可行性。不考虑总线宽度,导致资源利用率小且恒定;
2. 该方法可以直接改变循环冗余校验多项式,无需重新编码和合成;
3. 上述程序的代码可作为整个项目的一部分在[1]中访问。据我们所知,这是第一个涵盖上述整个过程的开源代码。
3.5 分段系统架构
非分段系统架构无法在一个字(时钟)中处理多个帧,这降低了短帧或未对齐帧的吞吐量。这就是总线效率问题。针对这一问题,提出了一种分段的系统架构。总线格式与[5]中的相同,[5]中的块(block)是[13]中段(segment)的另一个名称。比如一条4096位总线可以同时处理8个完整的帧;因此,总线可以分为八个区域[5]。区域的数量仅取决于总线宽度。不同的段宽度是可行的,如果选择64位的段宽度,一个区域可以分成八个段(块)。图3示出了所提出的分段系统架构。与建议的非分段系统架构相比,建议的分段系统架构具有稍微更复杂的区域1和区域2以及区域3和区域4的多个副本。重复的数量只是单个字中处理的最大帧数。
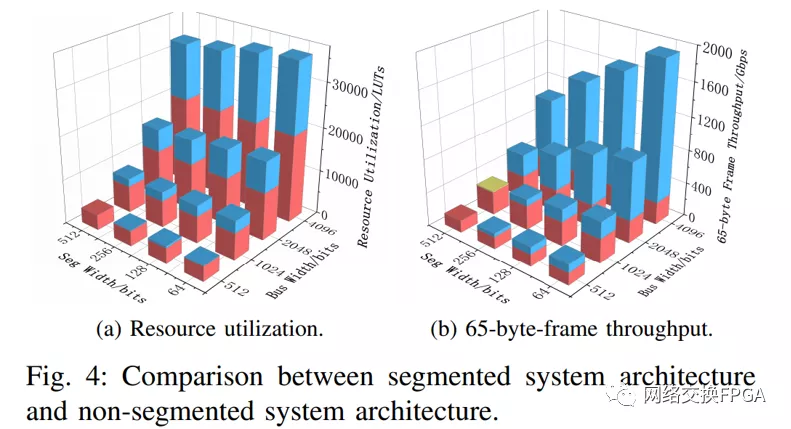
在图4中可以找到所提出的分段系统架构和所提出的非分段系统架构之间的比较。红色长方体代表非分段系统架构。蓝色长方体表示建议的分段系统架构和建议的非分段系统架构之间的增量。黄色切片(总线宽度= 1024,段宽度=512) 表示两种体系结构之间的减量。图4a示出了资源利用率的增加主要取决于总线宽度而不是段宽度。这是因为资源利用率的增加主要取决于区域3和4的副本数量,而区域3和4的副本数量仅取决于总线宽度。图4b显示,在大多数情况下,65字节帧吞吐量的增加是明显的。当总线宽度为1024位,段宽度为512位时,吞吐量只会下降,其中两种架构对于65字节帧吞吐量具有相同的总线效率,而非分段架构的频率略高。因此,在本文的其余部分,选择64位作为段宽。分段和非分段架构之间的详细比较可以在本简报的扩展版本中找到[11]。
4. 实验结果
有三个最先进的研究[5][4][14]。[4][14]中的体系结构可以重新编程,而[5]中的体系结构不能重新编程。提出的两种架构分别用Virtex-7 XC7VX690T实现,[5][4][14]使用Virtex-7 XCVH870T、Virtex-6 XC6VLX550T和Stratix-V 5SGSED6N1F45I2。在本节中,从资源利用率和最大吞吐量的角度将两种建议的体系结构与这些工作进行了比较。就各种帧长度的吞吐量而言,将所提出的分段架构与[5]进行了比较。还报告了两种建议架构的功耗。在下文中,我们使用SA来指代分段架构。
综合结果如图5所示。图5a示出了建议的非SA的资源利用率较分别比[4]和[5]中的体系结构低80.7%-87.5%和25.1%-46.2%,SA的分别为81.7%-85.9%和2.9%-20.8%。资源利用率较低是由于实施了第三节中描述的算法和方法,这也可以保证高性能和可编程性。[14]中的体系结构的资源利用率比非SA体系结构低74.4%-81.3%。[14]资源利用率较低的原因如下:1)。[14]只需要处理半满和全满的数据包。换句话说,补零问题得到了部分解决。相比之下,两个建议的架构和[5][4]可以完全解决填充零问题。2)。Nios II IP核的成本在[14]中没有考虑。相比之下,两种建议的体系结构都考虑了HWICAP的成本。此外,很难将[14]的总线宽度扩展到1024位。
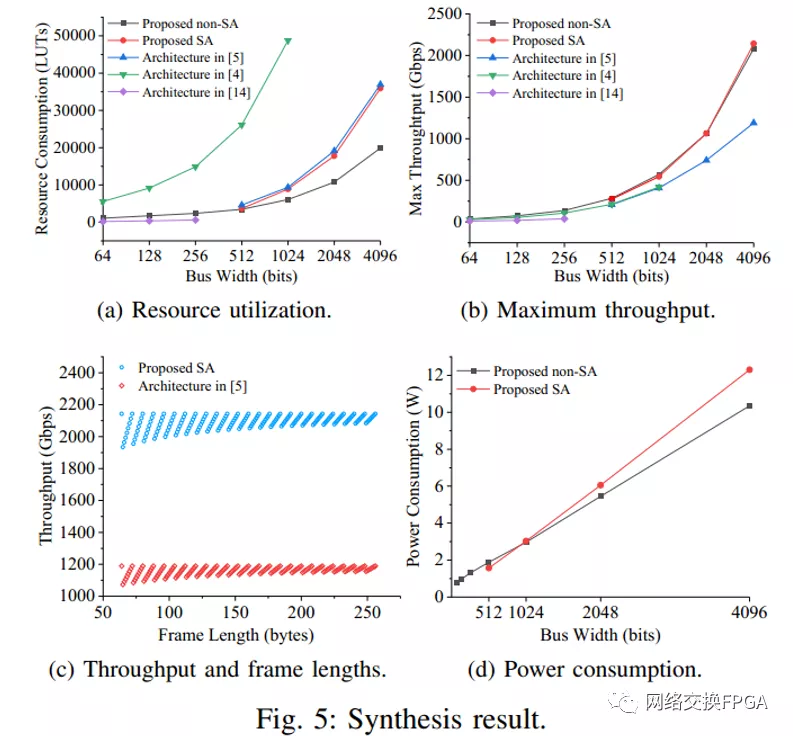
图5b显示,所提出的非SA的最大吞吐量分别比[4][5][14]中的架构高24.2%-37.9%、37.4%-75.0%和259.4%-284.5%。提出的SA的最大吞吐量分别比[4][5]中的架构高28.7%-30.2%和32.2%-80.2%。更高的频率导致更高的吞吐量,并且两个建议的架构可以为区域1、2和4中排列良好的流水线实现更高的频率。
帧长度从64字节到256字节的吞吐量可以在图5c中找到。只有[5]和提议的SA被比较,因为它们在一个字中处理多个帧的能力。这两种架构使用4096位总线宽度和64位段宽度;因此,它们具有相同的总线效率。提议的SA的频率和吞吐量比[5]高80.2%。当帧长度为65字节时,最低吞吐量为1933.9 Gbps。
两种提出架构的功耗如图5d所示。它们以500Mhz运行。数据集来自vivado生成的实施后功耗报告。功耗由静态功耗和动态功耗组成。静态功耗从0.32 W到0.48 W不等,动态功耗随着总线宽度的增加而线性增加。提议的SA的功耗比提议的非SA的功耗增长更快。这是因为提议的SA的资源消耗比提议的非SA的资源消耗增加得更快。
板级实现和与其他作品的比较可以在本文的扩展版本中找到[11]。
5. 结论和未来工作
本文提出了两种算法和一种方法来实现低成本、高性能和可编程的循环冗余校验计算。这些算法和所提出的方法可用于分段或非分段架构。综合结果表明,与现有的两种体系结构相比,所提出的体系结构可以实现更低的资源利用率和更高的吞吐量。源代码可以在[1]中访问。我们未来的工作将集中在使硬件重配置方法(HWICAP)威廉希尔官方网站 独立。
审核编辑:何安
-
算法
+关注
关注
23文章
4608浏览量
92845
发布评论请先 登录
相关推荐
什么是raid磁盘冗余阵列
冗余电压采集威廉希尔官方网站 有哪些 冗余电压不足的原因是什么
冗余电源怎么接线
循环神经网络算法原理及特点
循环神经网络算法有哪几种
Hex文件格式CRC校验,怎么编写计算校验的程序?
FPGA压缩算法有哪些

verilog中for循环是串行执行还是并行执行
什么是PLC的软冗余和硬冗余?PLC不做性能冗余可不可以?
fpga报告crc故障是什么意思
虹科威廉希尔官方网站 | 保障数据传输稳定性:BabyLIN产品的CRC算法实现

虹科威廉希尔官方网站 |保障数据传输稳定性:BabyLIN产品的CRC算法实现





 工商网监
工商网监
评论