 NLP:用Cluster-to-Cluster生成更多样化的新数据
NLP:用Cluster-to-Cluster生成更多样化的新数据
论文名称:C2C-GenDA: Cluster-to-Cluster Generation for Data Augmentation of Slot Filling 论文作者:侯宇泰、陈三元、车万翔、陈成、刘挺 原创作者:侯宇泰 论文链接:https://arxiv.org/abs/2012.07004 出处:哈工大SCIR
1. 简介
1.1 研究背景
对话语言理解(Spoken Language Understanding,SLU)[1]经常面临领域和需求的频繁切换,这常常会导致训练数据在数量和质量上的不足。
数据增强(Data Augmentation)是一种自动生成新数据扩充训练集的威廉希尔官方网站 ,能够有效地缓解上述数据不足的带来的挑战 [2,3]。
1.2 研究动机
如图1(上)所示,现有数据增强,如基于Seq2Seq 的句子复述(re-phrasing)方法 [4,5,6],经常无法避免地生成没有意义的重复数据。这很大程度要归咎于现有的one-by-one数据生成模式。
相较之下,如图1(下)所示,one-by-one数据生成弊病可以天然地通过多到多(cluster-to-cluster)生成方式得到缓解。
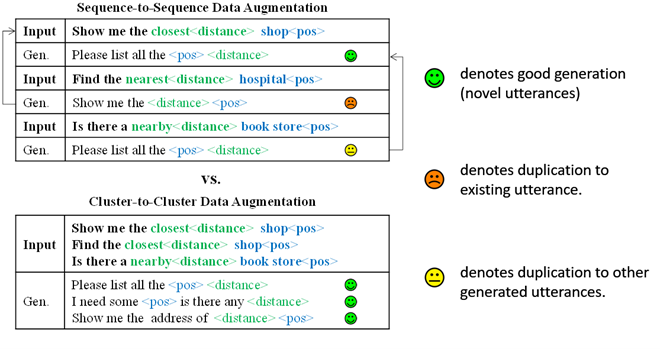
图1 示例:从已有句子生成新表述,现有one-by-one复述方法无法避免生成重复数据
1.3 我们的贡献
我们提出了一种全新的Cluster-to-Cluster生成范式来生成新数据,并基于此提出了一个全新的数据增强框架,称为C2C-GenDA。C2C-GenDA通过将现有句子重构为表达方式不同但语义相同的新句子,来扩大训练集。与过往的Data Augmentation(DA)方法逐句(One-by-one)构造新句子的做法不同,C2C-GenDA采用一种多到多(Cluster-to-Cluster)的全新的新语料生成方式。
具体的,C2C-GenDA联合地编码具有相同语义的多个现有句子,并同时解码出多个未见表达方式的新句子。
这样种的生成方式会直接带来如下好处:
(1)同时生成多个新话语可以让模型建模生成的新句子之间的关系,减少新句子间内部重复。
(2)联合地对多个现有句子进行编码让模型可以更广泛地看到已有的现有表达式,从而减少无意义的对已有数据的重复。
1.4实验效果
当只有数百句训练语料时,C2C-GenDA数据增强方法在了两个公开的槽位提取(slot filling)数据集上分别带来了 7.99 (11.9%↑) and 5.76 (13.6%↑) F-scores 的提升。
2. 方法
2.1 Cluster2Cluster 生成模型
给定具有相同语义框架(semantic frame)的一组多个句子,即input cluster, 模型一次性生成多个新句子,即output cluster。这些输出与输入的语义框架相同,但是具有不同的表达方式。
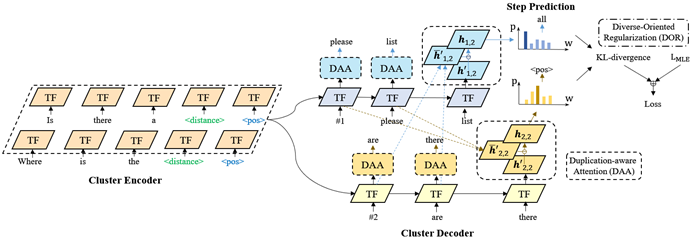
图2 Cluster2Cluster 生成模型
如图2所示,Cluster2Cluster模型采用基于Transformer的Encoder和Decoder。具体的,我们用特殊分割Token拼接input cluster中的句子,作为模型输入。在解码时,模型用多个共享参数的decoder同步解码多个新句子。
我们采用了前人添加Rank Token作为解码起步的方法[5]来让模型区分不同的输出句子。
同时,为了进一步提升句子的多样性,我们提出Duplication-aware Attention和Diverse-Oriented Regularization来进一步强化模型,如图2所示:
(1)Duplication-aware Attention(DAA):通过Attention为模型提供两方面的信息,即Input Cluster中已有的表达方式,和其他正在解码的句子中的表达方法。根据这些信息,我们采用一种类似Coverage Attention的方式对重复的表达生成进行惩罚。
(2)Diverse-Oriented Regularization(DOR):我们提出DOR来从Loss层面引导模型生成多样的句子。具体的,我们用不同句子,解码词分布之间的KL-散度作为loss,来约束模型避免在不同的句子中的相同step解码出相同的词。
2.2 Cluster2Cluster 模型训练
仅有多到多的生成模型显然不足以生成新的数据。为了让Cluster2Cluster模型具有生成新表述的能力,我们提出了Dispersed Cluster Pairing算法来构造多到多的复写(Paraphrase)训练数据。
具体的,如图3 和图4所示,给定具有相同语义的一组数据,我们首先找到一组表述相近的句子作为Input Cluster,然后贪心地构造Output Cluster:每次添加一句和Input Cluster以及现有Output Cluster表述差异最大的句子到 Output Cluster。
这样的作法旨在interwetten与威廉的赔率体系 从少量说法有限的句子生成多样的未见表述的过程。

图3构造多到多的Paraphrase训练数据

图4多到多的Paraphrase训练数据构造算法
2.3 数据增强实现
我们将原有的训练数据分为两份,一份训练C2C-GenDA模型,一份用来做数据增强的输入。
最后我们用所有新生成的句子和原有的句子作为增强后的训练集。
3. 实验:
3.1 主实验结果
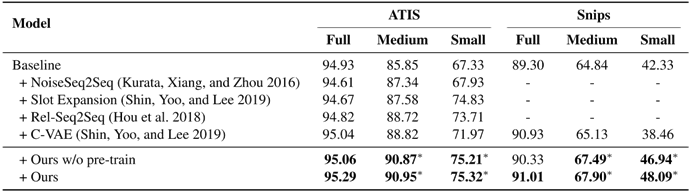
如表1所示,我们的方法能够大幅地提升Slot Filling模型效果(Baseline),并优于现有的数据增强方法。
表1 主实验结果
3.2 分析实验
如表2所示,在消融实验中,我们提出的各个模块都对最终的实验效果起到了作用。
表2 消融实验
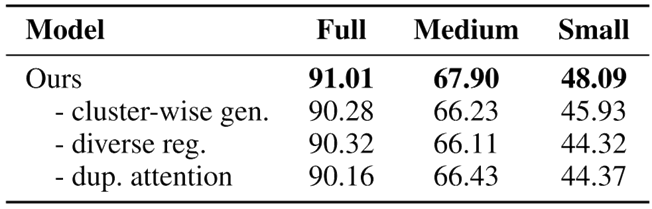
表3展示不同生成模型的生成数据和Inter和Intra多样性,结果显示采用Cluster2Cluster的生成方法可以让新数据的多样性产生巨大的提升。
表3 多样性分析实验
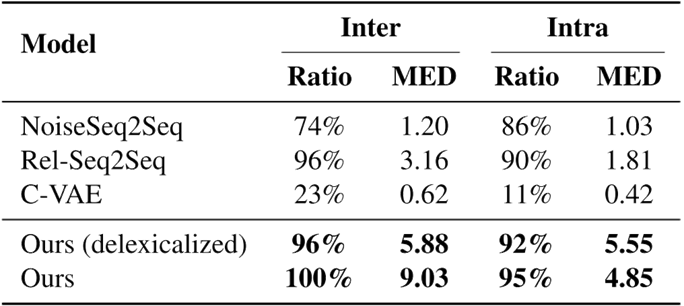
表4展示了由Cluster2Cluster模型生成的一些样例,可以看到Cluster2Cluster模型可以从多个角度生成一些有趣的新表述方式。
表4 样例分析

4.参考文献
[1] Young, S.; Gasiˇ c, M.; Thomson, B.; and Williams, J. D. ´ 2013. Pomdp-based statistical spoken dialog systems: A review. Proc. of the IEEE 101(5): 1160–1179.
[2] Kim, H.-Y.; Roh, Y.-H.; and Kim, Y.-G. 2019. Data Augmentation by Data Noising for Open-vocabulary Slots in Spoken Language Understanding. In Proc. of NAACL, 97– 102.
[3] Shin, Y.; Yoo, K. M.; and Lee, S.-G. 2019. Utterance Generation With Variational Auto-Encoder for Slot Filling in Spoken Language Understanding. IEEE Signal Processing Letters 26(3): 505–509.
[4] Yoo, K. M. 2020. Deep Generative Data Augmentation for Natural Language Processing. Ph.D. thesis, Seoul National University
[5] Hou, Y.; Liu, Y.; Che, W.; and Liu, T. 2018. Sequence-to-Sequence Data Augmentation for Dialogue Language Understanding. In Proc. of COLING, 1234–1245.
[6] Kurata, G.; Xiang, B.; and Zhou, B. 2016. Labeled Data Generation with Encoder-Decoder LSTM for Semantic Slot Filling. In Proc. of INTERSPEECH, 725–729.
责任编辑:xj
原文标题:【SCIR AAAI2021】数据增强没效果?试试用Cluster-to-Cluster生成更多样化的新数据吧
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
-
数据
+关注
关注
8文章
7017浏览量
89011 -
自然语言
+关注
关注
1文章
288浏览量
13348 -
nlp
+关注
关注
1文章
488浏览量
22034
原文标题:【SCIR AAAI2021】数据增强没效果?试试用Cluster-to-Cluster生成更多样化的新数据吧
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

NVIDIA Isaac Sim满足模型的多样化训练需求
如何使用OpenUSD构建支持生成式AI的合成数据工作流
博科测试IPO上市观察:产品布局完善,可满足多样化检测需求
室内人行与导航系统有哪些多样化的功能?
双路设计,满足光伏电站与充电桩多样化计量需求——安科瑞丁佳雯
润和软件星闪业务闪耀海外,亮相“面向智能社会的威廉希尔官方网站 多样化与产品战略论坛”

nlp自然语言处理模型怎么做
DC/AC电源模块:实现电力系统的多样化应用

长电科技为自动驾驶芯片客户提供多样化高可靠性的封装测试解决方案
联合电子携多样化解决方案和创新威廉希尔官方网站 亮相2024北京车展
【TE Connectivity】泰科电子低温升 Cluster Block连接器,无惧高温,“清新”来袭!






 工商网监
工商网监
评论