 自动驾驶中的激光雷达点云如何做特征表达?
自动驾驶中的激光雷达点云如何做特征表达?
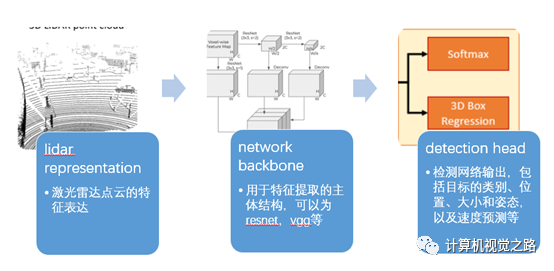
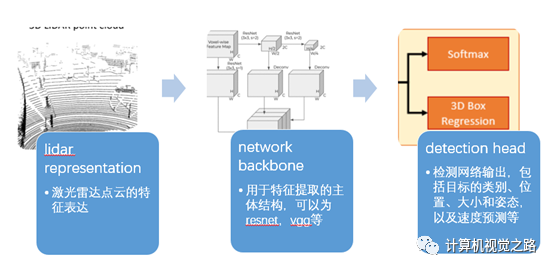
自动驾驶中的激光雷达点云如何做特征表达,将基于Lidar的目标检测方法分成了4类,即:基于BEV的目标检测方法,基于camera/range view的目标检测方法,基于point-wise feature的目标检测方法,基于融合特征的目标检测方法。本文对这4类方法讲解并总结,希望能帮助大家在实际使用中做出快速选择。基于lidar的目标检测方法可以分成3个部分:lidar representation,network backbone,detection head,如下图所示。
根据lidar不同的特征表达方式,可以将目标检测方法分成以下4种:基于BEV(bird’s eye view)的目标检测方法,基于camera view的目标检测方法,基于point-wise feature的目标检测方法,基于融合特征的目标检测方法。如下图所示。
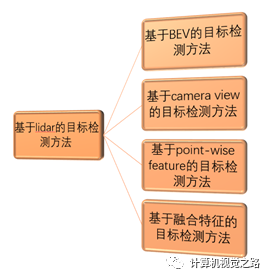
图1基于lidar目标检测方法分类
基于BEV的目标检测方法
基于bev的目标检测方法顾名思义是使用bev作为点云特征的表达,其检测流程如下图所示,包括3个部分:bev generator,network backbone, detection head。下面详细介绍一下这3个部分如何在基于bev的目标检测方法中发挥作用。

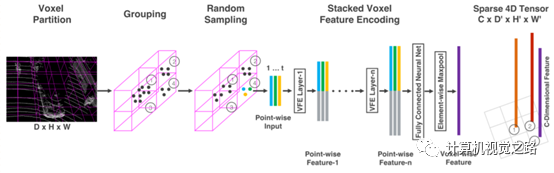
1. bevgenerator BEV图由激光雷达点云在XY坐标平面离散化后投影得到,其中需要人为规定离散化时的分辨率,即点云空间多大的长方体范围(Δl*Δw*Δh)对应离散化后的图像的一个像素点(或一组特征向量),如点云20cm*20cm*Δh的长方体空间,对应离散化后的图像的一个像素点。 在bev generator中,需要根据Δl*Δw*Δh来生成最后L*W*H大小的bev特征图,该特征图是network backbone特征提取网络的输入,因此该特征图的大小对整个网络的效率影响很大,如pointpillar通过对voxelnet中bev generator的优化,整个网络效率提高了7ms。 2. network backbone 网络结构的设计需要兼顾性能和效果,一般都是在现有比较大且性能比较好的网络结构基础上进行修改。以voxelnet和pointpillar为例,pointpillar以voxelnet为原型,不改变原流程的基础上,对voxelnet设计做了以下一些修改,使网络效率提高了10多倍,具体如下:简化bev中的网络结构voxelnet使用stacked vfe layer,在代码中使用了2个vfe layer,如下图所示。
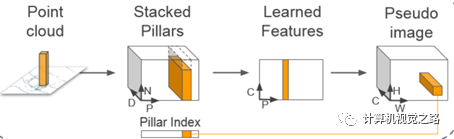
pointpillars简化了voxel表达形式,变成pillar,提高了数据生成效率,并且只使用了一个vfe layer,减少了2ms,如下图所示。
简化主网络结构
不使用3D卷积
输入特征图的channel数从128减少为64,网络耗时减少2.5ms
网络主结构所有层channel数减半,网络耗时减少4.5ms
Upsampling的channel数从256减少到128,减轻detection head,网络耗时减少3.9ms
Tensor RT加速,提速45.5%
Pointpillar[2]在保证网络性能提升的前提下,逐步提高网络效率,从不同角度优化网络流程,最后使网络效率提高10倍有余。 3.detection head detection head包括两个任务,即:目标分类与目标定位,由于bev将点云用图像的形式呈现,同时保留了障碍物在三维世界的空间关系,因此基于bev的目标检测方法可以和图像目标检测方法类比:目标分类任务与图像目标检测方法中目标分类任务没有差别;而目标定位任务可以直接回归目标的真实信息,但与图像目标检测方法中目标定位任务不同,该任务需要给出旋转框。与图像目标检测方法相同,基于bev的目标检测方法的detection head也分成anchor base的方法和anchor free的方法。 anchor base方法以voxelnet为例,需要人为设定anchor的大小,由于bev可以直接回归真实的目标大小,因此anchor也可以根据真实目标大小设定,如:以下单位为米,l、w、h分别表示anchor的长、宽、高,对于车来说anchor大小可以设定为la = 3.9,wa = 1.6,ha = 1.56,对于人la = 0.8,wa = 0.6,ha = 1.73,对于骑行者la =1.76,wa = 0.6,ha = 1.73,且对于每种anchor,设置了θa=0°和90°两种角度。由于目标有各种角度,因此为了得到更准确的角度回归,anchor的角度设置可以在[0°,180°)进行等间隔采样,获得更多不同角度的anchor,提高回归精度。回归误差的计算如下图所示。
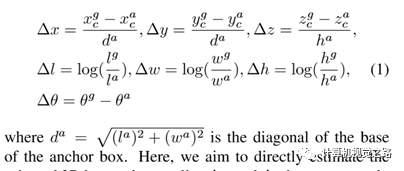
anchor free方法典型代表是pixor,对于bbox的回归,如下图所示,对于正样本的红点p(x,y),需要回归如下信息:{cos(θ), sin(θ), dx, dy, w, l},其中θ为障碍物偏角,dx、dy分别为p点相对障碍物中心点的偏移,w、l是障碍物大小的表达。没有anchor,对目标的回归是不是简单了很多。
以上为基于bev的目标检测方法的简单介绍,该方法在目前的自动驾驶的3D目标检测方案中应用较广。
基于camera/range view的目标检测方法
基于cameraview的目标检测方法顾名思义是使用camera view作为点云特征的表达,检测流程如下图所示,下面详细介绍一下这3个部分如何在基于camera view的目标检测方法中发挥作用。

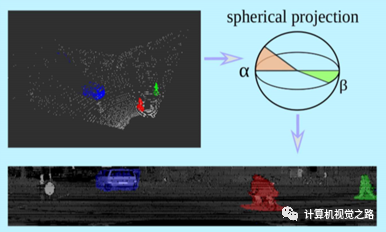
1. camera view generator camera view图是将每圈激光线拉成直线再按行累积而成,因此也称为range view,其中投影图的高为激光线数,宽为lidar扫描一圈的点数,如: 64线激光雷达,水平角分辨率为0.2°,生成的camera view的图大小为64*1800。camera view相对bev图小很多,因此基于camera view的方法效率都较高。camera view效果如下图。
2. networkbackbone 网络结构的设计要依据任务需求,基于camera view的目标检测方法,多是以分割任务为主,因此网络结构大都是encode+decode结构,如下图1所示。因此有关提高分割效果的网络 设计思想都可以在此使用,如图2中使用不同大小的dilation rate的卷积获得不同感受野的特征表达,如图3使用global attention增加上下文信息。更多分割增强模块,在后面会专门写一篇文章介绍。
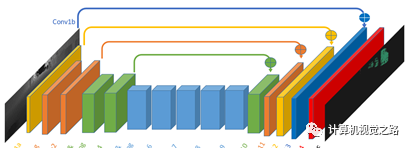
图1ecode+decode
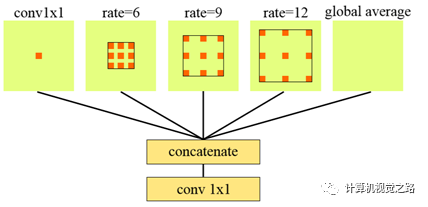
图2 不同dilate rate卷积
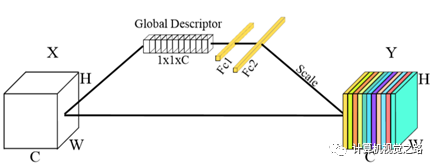
图3 global attention 3. detection head 基于camera view的目标检测方法有两种输出方式表达,一种是纯分割区域,另一种是分割与检测框。纯分割区域表达纯分割的输出是基于camera view的模型最直接、最好的一种输出。在原始3D点云中,尤其是远处的点,点与点之间的距离都较远,如bev投影图,造成点特征提取时很难融入上下文信息。而camera view投影图将点云中的点聚拢,每个点都可以很方便的获得更大范围的上下文信息,这种投影方式更适合分割任务。如在SqueezeSeg和PointSeg两篇文章中,都直接将分割作为最终任务目标,但是为了得到更好的联通区域,需要增加较多的后处理。如在SqueezeSeg,在模型输出后又增加了crf提高分割效果。在PointSeg中,使用RANSAC将异常点剔除,如下图,第一行为模型输入,第二行为模型直接的预测输出,第三行为将模型输出的camera view图反投影得到的点云图,第四行为经过ransac后再反投影得到的点云图,对比第三行和第四行对应的图可以看出,ransac有效的抑制很多离目标较远的点。
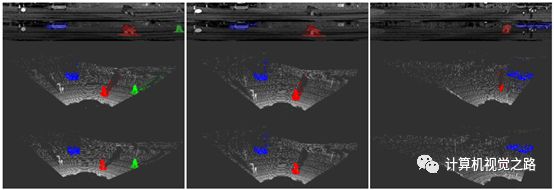
分割与检测表达分割任务对于基于camera view的模型相对简单,但是检测框的回归并不容易。camera view投影图增加了点云中点的上下文信息,但也将原本在3D空间分离的目标拉近,引入了遮挡与目标尺度变化,然而点云投影图又不像真实的图像那样有很丰富的纹理信息,造成了camera view图像很难做实例分割与目标框回归,因此,检测框的回归需要增加一些额外操作来实现。
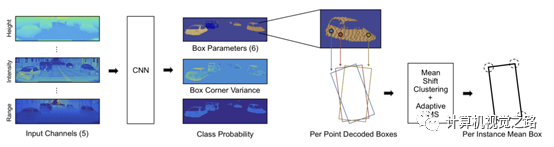
在lasernet中,对于目标框中的点(x,y)需要回归6个信息,如上图所示,Box Parameters为6,包括:该点相对中心点的偏移(dx,dy), 相对旋转角度 (ωx,ωy) = (cosω,sinω),以及框大小 (l,w),从而可以通过下述公式计算得到真正的目标框中心点bc以及旋转角φ,其中θ为该点在点云中的方位角,Rθ为以θ为旋转角的旋转矩阵。
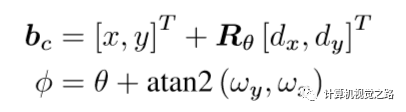
另外,由于对每个点的预测存在噪声,而后又在bev投影图中使用mean shift聚类方法得到更准确的目标框。 4. 小结 由于3D点云在做camera view投影的时候丢失了原来的3D结构信息,引入了图像中的尺度变化和遮挡两个问题,因此少有方法直接在这种模式下作3D目标检测,一般需要在网络输出基础上做比较多的后处理。但是camera view的表达模式,极大的增加了远处点云的上下文信息,也是一种极好的提高点云特征表达能力的方式。
基于point-wise feature的目标检测方法 我们从如下图所示的3个部分(lidar representation,network backbone,detection head),来介绍一下point-wise方法。其中lidar represention部分是直接使用点云做输入,即n*4的点集,不做单独介绍,下面重点介绍一下其他两个部分。
1. network backbone 提取点特征一般有两种方式:基于pointnet/pointnet++的点特征、voxel特征。如图1:在STD中,组合了两种方式。如图2,在PointRcnn中,仅使用了pointnet++提取点特征
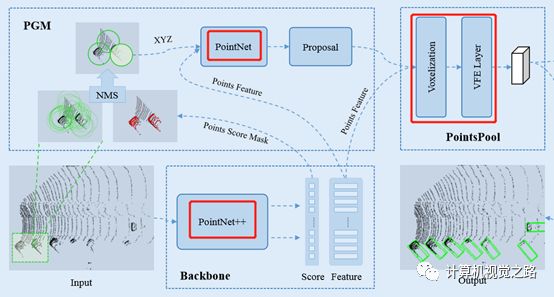
图1 STD特征提取方式
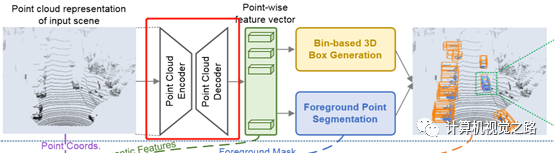
图2 PointRcnn中特征提取方式 在使用pointnet++[11]提取特征时,包含两个重要模块,即set abstraction(即,SA)和feature propagation(即,FP),如下图3所示其中SA是特征encoder过程,通过点云筛选与特征提取逐步减少点云点数,提高特征表达能力与感受,FP是特征decoder过程,通过点云上采样,获得稠密的点云表达,并级联SA过程的特征,提高最终的点云特征表达能力。
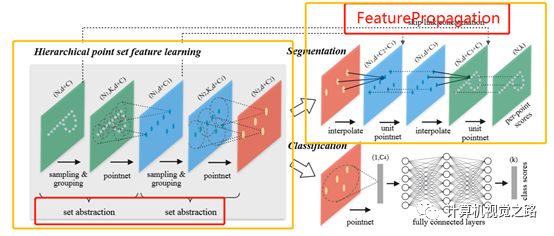
图3pointnet++特征表达 在3DSSD中,为了提高模型效率,去掉了耗时比较严重的FP模块,由于SA过程只筛选了一部分点做特征表达,对目标检测的召回影响很大,尤其对点云比较稀疏的远处的目标,影响更大,因此3DSSD在D-FPS的基础上,提出了F-FPS,即通过点的语义信息来做点的筛选,保留更多的正样本的点,保证最终的目标召回率。 2. detection head detection head除了完成目标分类与目标定位的任务,在two-stage detector中,还需要实现roi pooling,为第二阶段提供实例级别的特征,点云的特征表达还是有些差别的。 对于目标定位的任务,同样有anchor-base方法和anchor-free方法。在STD中,为应对有旋转角的box回归,提出了球形anchor,由于anchor没有角度的变化,直接将anchor数量减少50%,提高了计算效率。其他方法大都是anchor-free的方法,关于anchor-free的方法,推荐读一下kaiming大神的voteNet,比较好理解。 关于roi pooling,一般是针对单个目标,再次提取更丰富、更具表达能力的特征,因此在不同论文中,根据实例提取特征方式的不同,提出了不同的roi pooling方法,如在STD中,提出了PointsPool,在Part aware and aggregation中,提出了Roiaware Point Cloud Pooling,在pv-rcnn中提出了Roi grid Pooling。下面分别介绍一下。 PointsPool如下图4所示,分成三个步骤
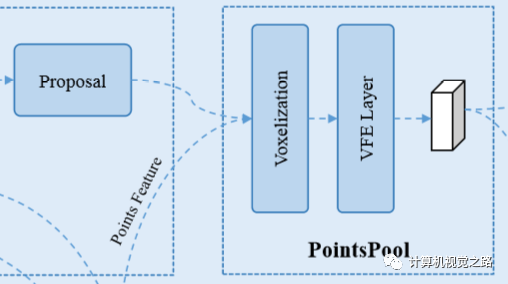
图4 PointsPool
特征提取:在proposal中随机筛选N个点,1)获得第一阶段的点特征;2)获得N个点的坐标,并用如下图5所示的canonical transformation得到与原坐标系无关的坐标特征。两种特征联合在一起,作为proposal中点的特征表达
Voxel表达:将不同大小的proposal,通过voxel统一化到相同大小:dl = 6,dw = 6,dh = 6
使用VFE layer提取最终特征
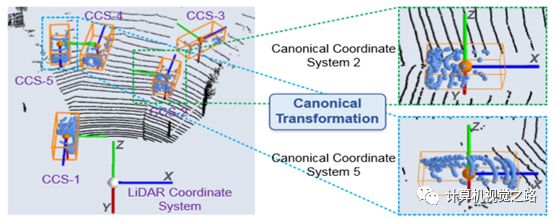
图5canonical transformation Roi aware Point Cloud Pooling整体流程如下图6所示,与STD中的pooling方法类似,首先将proposal分割成固定大小的voxel,如14×14×14,然后再提取voxel特征表达:
RoIAwareMaxPool:使用的是第一阶段输出的point-wise semantic part feature,在voxel中计算max pooling
RoIAwareAvgPool:使用的是proposal中经过canonical transformation点坐标特征和segmentation score,在voxel中计算avg pooling
最后将两组特征联合作为proposal的pooling特征。
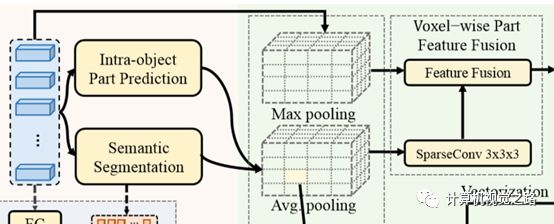
图6Roi aware Point Cloud Pooling Roi grid pooling与上面两种pooling方法不同的是,并没有将proposal通过voxel得到固定大小的特征图,而是根据pv-rcnn中提出的key point信息,将proposal用6*6*6=216个grid points表达,grid points是从proposal中的key points均匀采样获得,且RoI-grid point features提取过程和key point feature提取过程是相似的。简单来说就是以grid point为中心,r为半径的区域内提取不同尺度、不同感受野的特征,最后在使用2层的MLP网络获得最终的特征表达,如图7所示。
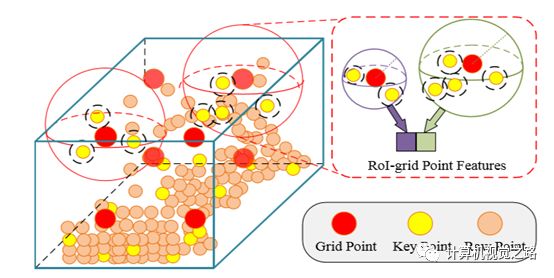
图7Roi grid point feature extraction3.小结与展望 目前基于point-wise feature的目标检测方法还处于研究阶段,效率无法保证,精度还未在真实自动驾驶车上测试,但由于该方法直接从点云提取特征,极大的保留了点云的原始信息,比较有潜力得到更好的效果。
基于融合特征的目标检测方法 Waymo在2020年初的文章“End-to-End Multi-View Fusionfor 3D Object Detection in LiDAR Point Clouds”使用了融合特征的方式,得到了不错的结果。下面详细介绍一下。
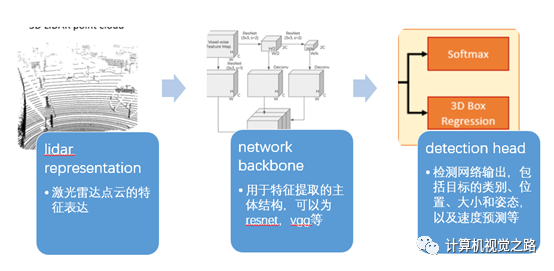
图1 目标检测流程 我们从如图1所示的3个部分(lidar representation,network backbone,detection head),来介绍一下融合特征的目标检测方法。文中主要和pointpillar做了对比,为了证明融合特征的有效性,在network backbone和detection head两部分的设计上保持了与pointpillars的一致性,这里不做单独介绍,下面重点介绍lidar representation,即如何获得融合特征。 1. lidar representation
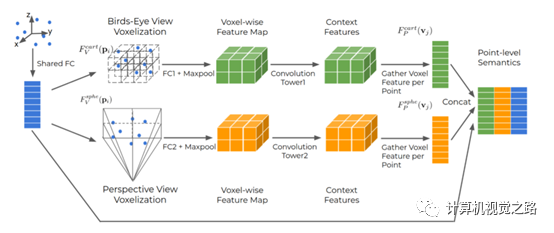
图2multi-view featurefusion的流程
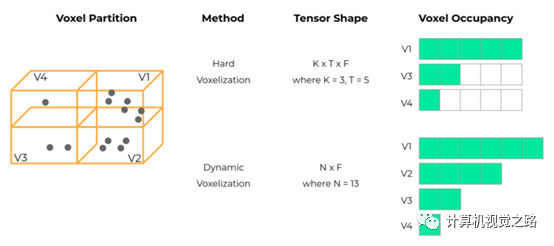
图3dynamicvoxelization计算流程 如图2所示为multi-view feature fusion的流程,融合了3部分特征:bev feature(如图中绿色部分)、camera/range view feature(如图中黄色部分)、point-wise feature(如图中蓝色部分)。具体流程如下:
对于原始点云,使用一个全连接层,获得point-wise feature。
在point-wise feature的基础上,提取bev feature。提出了使用动态voxel(dynamic voxelization,DV)的方式获得bev图,计算过程如图3所示,相对传统的voxel(Hard voxelization,HV),有3个好处,1)DV保留了voxel中的所有点,HV使用随机采样的方法选取固定的点数,有可能会丢失重要信息,如图3中v1的计算;2)HV中每个voxel中选择固定的点数,且对整个点云选择固定的voxel数量,因此会随机丢弃点甚至整个voxel,这种方式可能导致不稳定的检测结果,如图3中v2在HV中被丢弃;3)HV对于点数少于固定值的voxel使用0填充,这样会造成额外的计算,如图3中v2~v4。最后对于点云的每一个点,使用公式(1)获得点与voxel的投影关系,其中pi表示点云坐标,vj表示voxel,FV表示点到voxel的投影关系。
对于camera view,同样可以使用公式(1)计算得到,而camera view的投影计算
bev图和camera view图经过一个cnn后,获得相应的bev feature与camera view feature,再使用公式(2)(其中,FP表示voxel feature到点云的投影关系,是FV的逆)逆投影获得不同view的点特征的表达,最后与point-wise feature融合得到最终的点特征表达。
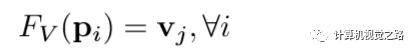
(1)
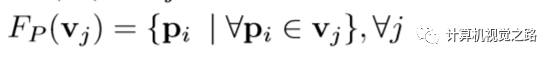
(2) 2. 结果与小结 在实验中,作者为了证明融合特征较强的表达能力,network backbone与detection head使用了与pointpillar相同的参数,并在waymo公开的数据库与kitti上做了实验。仅分析一下waymo公开数据库的结果,如图4中的table1和table 2。从结果可以看出,使用DV替换HV,使整体结果提高2个多点,再增加point-wise feature后,车辆检测结果再提高3个多点,行人检测结果再提高4个点,说明voxel中的每个点对voxel特征表达都重要,不能随机丢弃,更不能随机丢弃整个voxel,更精细的特征对小尺度的目标表达有帮助。耗时方面,由于mvf使用了与两种方法相同的网络配置,而又增加了新的特征表达,整体耗时高了20多ms,如果再对网络做一些优化,这种融合的方法对结果的提升意义很大。
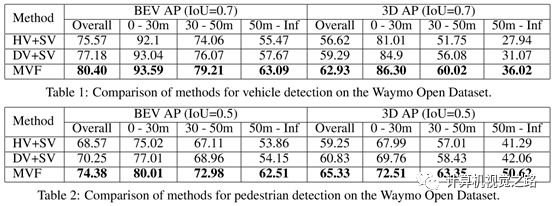
图4 waymo数据集结果
总结与展望 通过对整个检测流程的分析,将目标检测流程分成如下3个部分,如图2所示。并针对不同的目标检测方法,从这3个部分进行了详细的分析。
lidar representation:激光雷达点云的特征表达,包括bev图、camera/range view图、point-wise feature、融合特征。
network backbone:用于特征提取的主体结构,可以为resnet,vgg等,也包括增强特征的方式,如fpn
detection head:检测网络输出,包括目标的类别、位置、大小和姿态,以及速度预测等,对于two-stage detector来说,roi pooling也是很重要的一个环节。
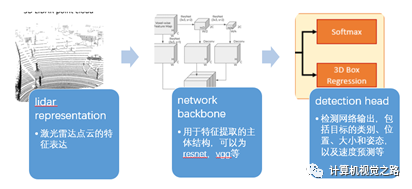
图2 目标检测流程 其实,在实际应用中,无论对于哪一种基于lidar的目标检测方法来说,我们评价其好坏,需要看精度与耗时之间的平衡。根据不同算法在kitti的bird’s eye view任务下公布的结果,将部分基于lidar的目标检测方法的moderate精度和latency总结如表1,并根据方法所属的不同类别画出分布图,如图3所示,横坐标表示算法耗时,单位ms,纵坐标表示算法在车辆检测任务中moderate精度,其中蓝点表示基于point-wise feature的目标检测方法,橙点表示基于BEV的目标检测方法,灰点表示基于camera view的目标检测方法。 表1不同算法检测效果
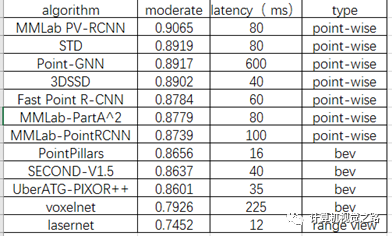
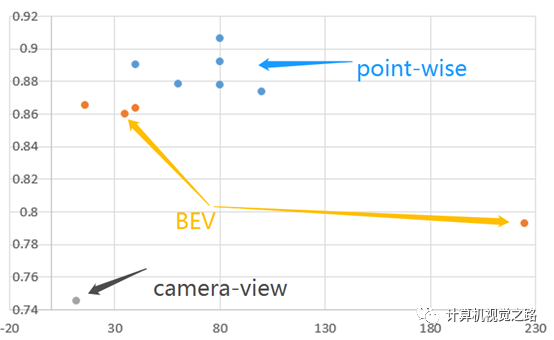
图3不同算法效果分布图 从图3,我们可以看出基于point-wise feature的目标检测方法精度最高,而且耗时有逐步减小的趋势,但是整体耗时依旧比其他两种方法高,其中耗时最低的是基于camera-view的目标检测方法,即LaserNet,仅有12ms,但是精度相对较最低;基于bev的目标检测方法在精度与耗时之间做了比较好的平衡,因此,在实际自动驾驶应用中,基于bev的目标检测方法应用最多。 之前在介绍基于point-wise feature的目标检测方法中说过,该方法潜力较大,其实从图3中也可以看出。如果从效率上可以优化一下,在实际应用的可能性也会变大。这个图仅是不同方法在车辆检测子任务上的效果,其实,相同的方法在自行车和人的检测任务中精度排名差别很大,如PV-RCNN在车辆检测中排名第2,在行人和自行车检测任务中分别滑到第6和第4;STD在车辆检测中排名第5,在行人和自行车检测任务中分别滑到第20和第13,如果基于point-wise feature的目标检测方法可以在不同任务间依然能保持精度优势,那么其落地的可能性又会增大很多。总之,我们需要从耗时、不同任务间精度平衡来评估算法的落地难易程度,但是对于有潜力的算法,我们更需要持续的投入,以期待解决未来更复杂的实际问题。
原文标题:一文览尽LiDAR点云目标检测方法
文章出处:【微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
激光雷达
+关注
关注
968文章
3972浏览量
189933 -
自动驾驶
+关注
关注
784文章
13816浏览量
166470 -
LIDAR
+关注
关注
10文章
326浏览量
29425
原文标题:一文览尽LiDAR点云目标检测方法
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
毫米波雷达与激光雷达比较 毫米波雷达在自动驾驶中的作用
激光雷达在自动驾驶中的应用
激光雷达与纯视觉方案,哪个才是自动驾驶最优选?
L4自动驾驶需求迭代,360°激光雷达也要进入芯片化时代

激光雷达点云数据包含哪些信息
聊聊自动驾驶离不开的感知硬件
激光雷达滤光片:自动驾驶的“眼睛之选”

FPGA在自动驾驶领域有哪些应用?
百度萝卜快跑第六代无人车携手禾赛AT128激光雷达,共筑自动驾驶新篇章
纳芯微GaN HEMT驱动芯片NSD2017在激光雷达中的优势
基于FPGA的激光雷达控制板

阜时科技近期签订商用车自动驾驶全固态激光雷达批量订单
激光雷达的应用场景
硅基片上激光雷达的测距原理






 工商网监
工商网监
评论