 优必选服务机器人NLP威廉希尔官方网站
最新研究进展
优必选服务机器人NLP威廉希尔官方网站
最新研究进展
12月18日,优必选研究院威廉希尔官方网站 专家罗沛鹏在智东西公开课进行了一场的直播讲解,主题为《优必选服务机器人自然语言处理威廉希尔官方网站 》,这也是优必选专场第7讲。
在本次讲解中,罗沛鹏老师首先从自然语言处理威廉希尔官方网站 的研究出发,对优必选的自然语言处理在机器人中的应用,如场景交互中的多轮对话问题,以及AI写作创作等方面进行全面解析,并对优必选自然语言处理在机器人上的应用案例进行解析。
本文为此次专场主讲环节的图文整理:
各位朋友大家好,我是来自优必选研究院的罗沛鹏,今天由我给大家讲解优必选服务机器人自然语言处理威廉希尔官方网站 。内容会分为以下5个部分:
1、服务机器人语音交互威廉希尔官方网站 概述
2、自然语言处理威廉希尔官方网站 概述与发展
3、优必选自然语言处理威廉希尔官方网站 的研究与开发
4、优必选自然语言处理威廉希尔官方网站 在服务机器人上的应用
5、优必选自然语言处理威廉希尔官方网站 未来研究方向
正文:
服务机器人语音交互威廉希尔官方网站 概述
如上图所示,人的语音通过ASR(语音识别)把音频变成文本,文本经过NLU(语义理解)、DM(对话管理)以及NLG(语言生成),生成的语言在通过TTS(语音合成),最后机器人完成对话。
自然语言处理威廉希尔官方网站 概述与发展
首先来几个段子,相信大家在网上经常看到类似的段子,比如“货拉拉拉不拉拉布拉多”,这个是一个典型的中文分词问题,生活中给大家带来不少的麻烦。另外我相信大家都在拼音输入法上翻过车,“答辩”打成“大便”,这是一个典型的语言模型问题,后面会介绍语言相关的模型。还有在前段时间比较火的满分作文生成器,可以用它来生成类似的满分作文,后边也有文本生成的算法介绍,请大家拭目以待。
自然语言处理威廉希尔官方网站 可以分为基础威廉希尔官方网站 和核心应用。其中,基础威廉希尔官方网站 包括自动分词、词性标注、命名实体识别以及句法分析。
自动分词是自然语言处理领域最基础的工作,以前主要基于规则和概率统计,现在已经发展到基于深度学习。比如“武汉市长 江大桥”还是“武汉市 长江大桥”等都是通过统计模型可以把词分配好。
词性标注就是在分完词后,利用算法把每个词的词性标注上。通常词性标注的粒度可以很细,比如可以标注动词、副动词、趋向动词、不及物动词等。
命名体识别是指识别具有特定意义的实体,比如人名、地名、机构名、专有名词等。
句法分析主要是指分析句中的主谓宾、定状补的句法关系。它的应用非常广泛,情感、信息、问答、机器翻译、自动文摘、阅读理解以及文本分类等。
上图是自然语言处理的四个阶段,第一阶段:在2000年之前,主要是基于规则和基于概率统计的方法。在50年代提出了图灵测试的概念来判断机器是否会思考,到目前为止,还没有出现大家一致认可的对话系统通过图灵测试。第二阶段:在2013年,随着神经网络的兴起,极大的提升了NLP的各项能力。第三阶段:基于seq2seq模型的NLP和注意力机制,在文本生成和机器翻译方面获得了比较大的进展。第四阶段是2018年以来,大型预训练模型的发展,也是我们现在所处的阶段。
优必选自然语言处理威廉希尔官方网站 的研究与开发
目前,优必选的研究方向分为以下几种:
1、任务型对话,主要是把意图词槽以及上下文的一些信息给抽取出来,在日常生活和服务机器人上用的比较多。
2、开放式闲聊,主要基于多轮的语料,做了一些开放式的闲聊。
3、文本生成,主要是一些创作类的文本生成,开放式闲聊也用到了一些文本生成的威廉希尔官方网站 。
4、知识图谱,为了提升交互体验以及赋予对话更多的知识,我们也在做这方面的尝试。
5、相似问法生成,主要是为了平台的语料能够很好的自动扩展,提升泛化能力。
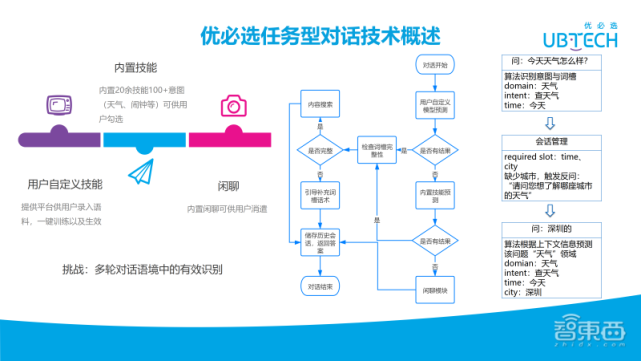
下面介绍下任务型对话的威廉希尔官方网站 概述,如上图所示,任务型对话主要分为用户自定义技能以及内置技能。自定义技能是提供一个平台可以让用户录入语料,一键训练后就会生效。内置技能则提供了20余个技能让用户可以勾选,比如天气、闹钟。
接下来看下上图右边的流程图,对话开始,然后采用用户自定义的模型去预测,如果有结果,则进入会话管理模块检查下词槽的完整性,如果完整,会进入内容的搜索,并储存历史会话信息;如果不完整,会引导补充词槽话术,然后储存历史会话信息,返回引导话术。如果对话开始,用户自定义模型预测是没有结果的,它会采用内置技能的模型去预测,看否有内置技能的结果,如果有结果,跟重复上面是一样的会话管理、完整性检查、历史会话存储等流程,直到对话结束。
如果内置的技能也没有,最后将走到闲聊模块。右边举了一个详细的例子,“今天天气怎么样”,算法会识别到领域意图、天气以及时间,然后识别到当前语句的语义之后,会进入会话管理模块,看下是否有一些缺少的词槽。比如天气缺少城市,它会触发“你想了解哪座城市的天气”。然后,用户问的下一轮,算法会根据上下文信息去预测该问题是哪个领域。例如“深圳的”上文可能是天气、交通或其他的一些领域。在此处根据上下文信息,可以预测到“深圳的”是属于是天气领域的。
具体实现可以看下上面的Demo,在上面的平台中提供给用户自己去配语料,然后一键触发训练并生效。平台需要添加词典,词典用于词槽抽取。平台也需要添加意图以及语料。同时平台还需要配置上下文信息,用于上下文预测算法以及会话管理。此外平台也可以配置必须填的词槽等。
为什么要做这样的平台?主要原因有三个:
第一是NLP场景特别多,机场、政府、商场的对话是完全不一样的,通过这个平台,公司的产品可以为每一台服务机器人定制特定的语料,减轻了算法工程师的工作量。
第二是迭代快,我们的平台自上线以来已经为咖啡机、防疫机器人等提供问答服务。尤其是防疫机器人在紧急情况下不到两周就完成了迭代。
第三是成本低,极大的降低了人力成本。
对话的核心是在多轮对话语境中的有效识别,那怎样在多轮对话语境中能够表现很好呢?我们需要一个好的主算法,如上图所示,先介绍下主算法的优点,它之所以适用于各种复杂的多轮对话语境中,是因为该算法基于预训练的BERT模型,泛化能力好。同时,由于在神经网络结构中有用到历史会话的上下文信息,所以该算法可以提升上下文的理解能力。此外,该算法在一个神经网络中能够同时识别意图、词槽。最后,通过数据增强等策略提升模型对低资源应用场景的适用性。
接着看上图左边,介绍深度算法的流程,u(t)表示用户当前的提问,s(t-1)表示机器人上一轮的回复,然后通过BERT提取特征,再进入到双向的GRU里,因为当前的语句只在后半部分u这边,该部分通过BERT的输出可以再输入到一个双向LSTM中,接着再输入到CRF里进行词槽的抽取。同时该GRU的左右双向的输出结果可以拼接在一起,通过线性的转换,然后通过sigmoid函数,进行动作的预测。该GRU用来做词槽抽取的特征也会输入到另外一个线性转换中,然后每一个分别输出一个key和value,再一一对应,输入到一个attention layer,进入线性的转换,最后进行意图的预测。
意图的数量是随着用户配置的意图数量而定,比如一个咖啡机可能配了10个意图。同时,该算法也是一个多分类的任务,因为这些意图之间存在一定的附属关系。举个例子,比如“今天天气怎么样”,这可能是“查天气”主意图,但说“明天呢”,可能是“天气查时间”子意图。因此融合上下文的信息,可以对意图进行比较好的预判。
下面重点讲下上下文的网络结构,上下文的输入u表示用户提问,s表示的机器人回复,可以通过BERT提取特征,进入双向的 GRU里,然后把该时刻的信息作为时间序列的一部分。这些信息根据时间序列输入到一个 GRU网络结构中。最后的输出将作为双向初始特征,用于输入意图、词槽的双向GRU网络中。
接下来介绍下平台训练的流程:导入词典、编辑意图、回复逻辑,然后再导入问法扩充模板,并导入一些实际的语料。在训练时,先加载语料,这时我们会通过聚类的分析去筛选验证集,因为我们想要验证集的分布与训练集是一致的。这里很重要,因为在自然语言处理中,每一个意图,比如查天气与查闹钟,它们的语料数量可能是不在一个数量级的。有可能查天气有1万条语料,而查闹钟只有区区几百条语料,这样造成了语料的不均衡。如果不用聚类算法把验证集的分布与训练集做的相似,采样时可能会漏掉一些语料少的意图。做完验证集的筛选后,我们会生成一批多轮对话语料去进行训练。为什么每次要生成语料,因为输入会涉及到历史的会话信息,所以在多轮的条件下,每次是不一样的。因此,每次生成一批语料,然后看模型是否收敛,收敛则发布模型,不收敛就重复该流程,直到达到限制条件。模型训练完发布后,进入使用阶段,在这个阶段用户输入对话,对它进行意图的识别,词槽的抽取,再经过一些会话管理的模块,最后结束。
深度学习的优点是对上下文的理解会非常精准,对平台的精准度提升非常有效,但是它的网络比较复杂,所以需要比较好的设备,那有没有比较节省成本的一些算法呢?我们还有一个快速算法,快速算法的特点是有以下三个:
1、只对语料模板进行训练,可以千百倍的减少训练时间;
2、模型体积较小,需要的硬件成本也较低;
3、在特定的场景下准确率也比较高。
那什么是快速算法?比如一句话“我想从北京去成都”,它拆成问法,就是“我想从去”。如果训练模型只对模板进行训练会很快,但也存在一个问题。比方说,句子中“我想从北京去成都”去预测时,需要把它还原成模板。然而,像“成都”这种词,可能既是歌名又是城市名,这时它会产生相当多的排列组合。因此,需要准确的挑出来,“我想从去”,“我想从去”则是错误的模板。
在训练时有大量的模板,有正例也有负例,因此有了第一个损失函数,令其中的正例模板为1,其他都是0。同时,还需要判断该问题的意图,即要知道这句话的意图是交通,所以,需要设计一个意图预测的损失函数。因此在训练时,让两个损失函数都收敛就得到一个快速模型。为什么要用RNN和CNN的算法呢?答案是因为速度比较快。以上就是训练的过程。
在预测时,需要先对句子进行词槽的提取。由于最初是不知道意图的,所以只能把它在相应的词典里的信息都提取出来,通过排列组合的方式,会得到一组模板的候选集(“我想从去”,“我想从去”),把它们输入到训练好的模型中,就可以预测出来。
下面介绍下优必选的闲聊威廉希尔官方网站 ,闲聊分为匹配式闲聊与生成式闲聊。匹配式闲聊是有一个Q&A库,Q&A库如果够大,可以达到一个比较好的闲聊效果。生成式闲聊不需要匹配,根据问题生成答案。他们各有优缺点,匹配式闲聊是可控的,可以通过语料的编撰,增加、删除等方式,包括一些敏感词可以在建立语料库把它给删除。生成式闲聊的对话时的变化会大一些,但是有一定的不可控性,有时语料不干净,会生成一些不太健康的内容,同时还会存在一定的语义、语法的问题。
优必选的闲聊如上图所示,首先进入匹配式闲聊,看库里有没有结果,如果有,储存历史多种信息并返回。如果没有,通过知识图谱问答,看知识图谱里是否能收到相应的知识,有结果,储存历史信息返回。如果知识图谱还没有,我们将进入生成式闲聊,然后储存历史对话信息、反馈结果。
那么历史多轮信息有什么用呢?历史多轮信息会用于生成式闲聊,不管是匹配式闲聊的答案,还是知识图谱答案,它的历史信息都将成为生成式闲聊的输入。
闲聊是NLP一个永恒的难题,主要是知识如汪洋之大海,永远缺乏高质量的对话;那算法求的只是一个概率,缺乏现实的逻辑推理;最后机器是不冷暖的,所以单凭文字不一定能够捕获到丰富的情感。这需要借助视觉,包括语音识别,各种声纹信息等。
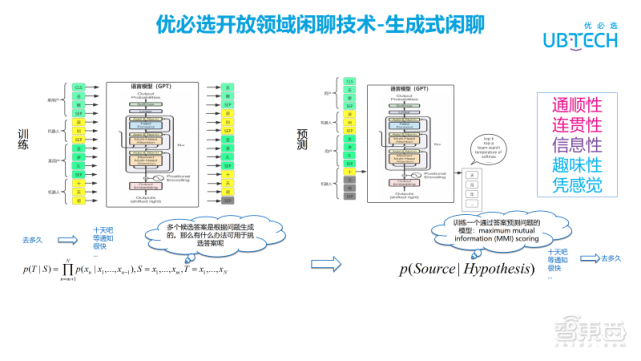
接着介绍下生成式闲聊,目前生成式闲聊主要基于GPT的模型,它本质上是语言模型,GPT是基于Transformer 的Decoder 部分。那语言模型是什么?语言模型是根据一个句子的已知序列信息去预测该句子的下一个字。那具体怎么操作?我们把用户的多轮闲聊作为语言模型的输入,然后训练模型,这是训练部分。对于预测,相对于训练多了一个环节,先根据历史的多轮闲聊序列通过gpt生成一个字,生成该字时会生成多个候选的字。可以通过一些top-k、beam search等算法,以及一些参数的调节,来挑选候选字中最合适的那个。接着,该字加入序列,重复使用此方法生成下一个字,直到生成结束符。
通常不会只生成一个答案,会生成多个候选答案,那么生成了多个候选答案,该如何挑选一个更加合适的答案呢?可以训练一个通过答案预测问题的模型,也就是最大互信息的评分。上图左边是回答生成的训练过程,右边的思路与左边的思路是反向的,是由答案生成问题。实际运用时,采用正确的时序生成多个候选答案。再把生成的候选集输入到训练好的最大互信息模型里,看预测到原始问题时,哪个候选答案的损失值最低,这种方法可作为候选答案的挑选。
我们的闲聊在内部做了一个评测,从它的通顺性、连贯性、信息性、趣味性以及凭感觉等方面打分。关于效果方面,通顺性和连贯性还不错,趣味性跟凭感觉方面,大家觉得还有优化的空间。除了上面提到的算法,还有其他一些比较优秀的算法,比如plato-2、blender等,但这两个算法推理比较慢,所以我们没有采用上面的算法。
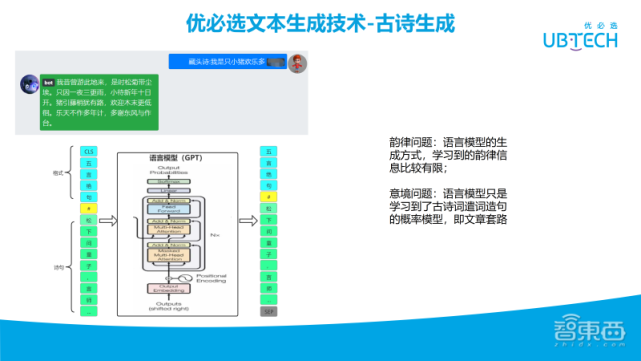
接下来是文本生成威廉希尔官方网站 ,比如古诗生成,输入“我是只小猪欢乐多”。生成的结果可以看下左上角的图,生成的古诗是押韵的,那怎么做的呢?同样还是采用GPT模型。首先要定义它的格式,比如五言绝句、七言绝句、词牌等,然后用分隔符分开,接下来把诗词给到模型,并且要带标点符号,然后通过语言模型训练,他具备这样的生成能力。
生成完后,就涉及到一些押韵的处理。具体首先需要进行预处理,并定义诗词的类型。然后,与诗词的内容并拼接起来。接着文本向量化输入到GPT里。接着也是一个字、一个字生成答案。当生成到有句尾标点符号时,要看最后一两个词与前一句是否押韵。如果不押韵,要重新生成一句话,以此来保证可以都押韵。但不一定保证所有情况都押运,可能预测很久都没有押韵,这时候,我们会设一个超时,超时后直接生成一个不押韵的句子。
古诗词生成存在一些问题,首先是押韵问题,语言模型学习到的韵律信息比较有限;其次是意境问题,语言模型只是学习到了古诗词遣词造句的概率模型,即文章套路,对比较有套路的文章,可以生成的比较好。于是乎,但是词(宋词)的效果比不上诗,因为词的套路很多,还有各类词牌,每句话字数也不一致,所以对词的效果会差很多。
在知识图谱方面,它的主要组成分三块:节点、属性、关系。在该图中,节点表示每个人,比如周杰伦;属性是他的出生、成就、身高等;连接节点之间的叫关系,比如周杰伦通过妻子的关系可以链接到昆凌。以关系相连各个节点,会组成一个庞大的知识网络,关系是具有方向性:单向或双向的,单向的比如昆凌是周杰伦的妻子;至于双向,比如同学关系,甲是乙的同学,乙是甲的同学。
知识图谱威廉希尔官方网站 目前只是用来做知识问答,用来丰富闲聊的交互体验。它的一个问答涉及到预处理、实体识别、实体链接、关系抽取、手写识别,主谓宾、施受关系检测,答案的生成以及排序,敏感词过滤等。
知识图谱存在很大的挑战,首先在问答挑战方面知识是无法穷尽的,知识的收集、梳理以及抽取是非常大的工作量,其次问法也是无穷无尽的,所以非常难理解到各种各样的问法。
知识图谱的应用主要是探索知识图谱与开放式对话等方面的融合威廉希尔官方网站 ,我们的目的是为了优化交互体验,提高对话系统的多样性、逻辑性、可解释性等。
优必选自然语言处理威廉希尔官方网站 在服务机器人上的应用
NLP在服务机器人上有哪些应用呢?首先是机器人问答,还有无人轮值客服、机场与车站、无人贩售等。具体应用案例包括无人咖啡馆、防疫机器人问答和uCode等。
无人咖啡馆
上面是我们咖啡机器人,它可以实现结合上下文语境,精准理解用户点单,避免人员直接接触。
防疫机器人问答
疫情期间,通过服务机器人的智能防疫问答,减少人员的聚集,为疫情的纾解提供有力保障。
uCode
uCode是优必选面向编程教育领域开发的一款软硬件结合的编程客户端,学生可以不使用键盘去敲代码,可以通过拖拽积木的方式编程。
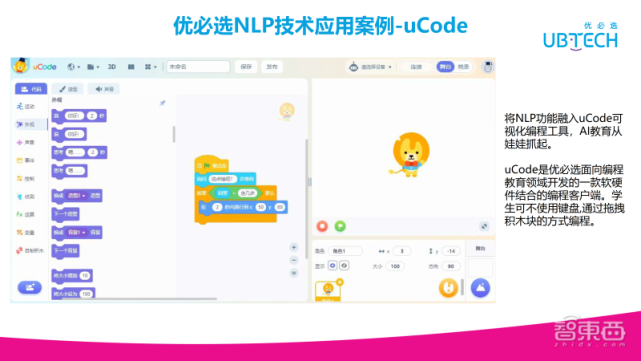
具体可以看到上图,涉及到语音识别以及文本匹配,用户可以输入“听到走几步”时,他做什么样的动作,可以通过语音识别把它变成文字,再进行动作匹配。涉及到语音识别时,由于环境中的噪音,可能会出现多一个字、少一个字。同时,编程为“走几步”时,用户在实际使用的时候也有可能说成“走几步吧”或“请走几步”类似的。有了NLP的文本模糊匹配功能,就解决了。其他的诸如于古诗词生成等,都可以加入到uCode编程中,提升uCode的教学能力。
优必选NLP未来的研究方向
接下来的方向一个是提升交互体验,要紧跟前沿走,探索交互体验;同时,还需要提升平台的能力,目前平台的能力是比较基础的,未来可能会增加语料自动扩展的功能;此外,系统还要增长知识,在智能对话中,知识是比较欠缺的。因此,我们正在做知识图谱这块,并在探索它跟对话的融合威廉希尔官方网站 ,为机器人的对话增智。
以上是今天的分享,谢谢大家。
原文标题:罗沛鹏:优必选服务机器人NLP威廉希尔官方网站 最新研究进展
文章出处:【微信公众号:中山市物联网协会】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
机器人
+关注
关注
211文章
28393浏览量
206962 -
自然语言
+关注
关注
1文章
288浏览量
13347 -
nlp
+关注
关注
1文章
488浏览量
22033
原文标题:罗沛鹏:优必选服务机器人NLP威廉希尔官方网站 最新研究进展
文章出处:【微信号:ZS-IOT,微信公众号:中山市物联网协会】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论