 芯片设计阶段时关于PPA的考虑
芯片设计阶段时关于PPA的考虑
谈到芯片,首先想到的一定是性能,功耗,价格,成熟度,生态圈兼容性等。但是只针对芯片本身的话,是看芯片内部有什么运算能力,比如处理器,浮点器,编解码器,数字信号处理器,图形加速器,网络加速器等,还要看提供了什么接口,比如闪存,内存,PCIe,USB,SATA,以太网等,还有看里面自带了多少内存可供使用,以及功耗如何。
性能,对CPU来说就是基准测试程序能跑多少分,比如Dhrystone,Coremark,SPEC2000/2006等。针对不同的应用,比如手机,还会看图形处理器的跑分,而对网络处理器,会看包转发率。当然,还需要跑一些特定的应用程序,来得到更准确的性能评估。
功耗,从high level来看,也分动态功耗和静态功耗。动态功耗,就是在跑某个程序的时候,芯片的功率是多少瓦。通常,这时候处理器会跑在最高频率,但这并不意味着所有的晶体管都在工作,由于power gating和clock gating的存在,有些没有被用到的逻辑和片上内存块并没在耗电。芯片公司给出的处理器功耗,通常都是在跑Dhrystone。这个程序有个特点,它只在一级缓存之上运行,不会访问二级缓存,更不会访问内存。这样得出的功耗,其实并不是包含了内存访问的真实功耗,也不是最大功耗。为得到处理器最大功耗,需要运行于一级缓存之上的向量和浮点指令,其结果通常是Dhrystone功耗的2-3倍。但是从实际经验看,普通的应用程序并不能让处理器消耗更高的能量,所以用Dhrysone测量也没什么问题。当然,要准确衡量整体的芯片功耗,还得考虑各种加速器,总线和接口,并不仅仅是处理器。
在芯片设计阶段,最重要的就是PPA,它转化为设计,就是功能,性能,功耗,直接影响价格。其中,性能有两层含义。在前端设计上,它表示的是每赫兹能够跑多少标准测试程序分。通常来说,流水线级数越多,芯片能跑到的最高频率越高。可是并不是频率越高,性能就越高。这和处理器构架有很大关系。典型的反例就是Intel的奔腾4,30多级流水,最高频率高达3G赫兹,可是由于流水线太长,一旦指令预测错误,重新抓取的指令要重走这几十级流水线,代价是很大的。而它的指令又非常依赖于编译器来优化,当时编译器又没跟上,导致总体性能低下。而MIPS或者PowerPC的处理器频率都不高,但是每赫兹性能相对来说还不错,总体性能就会提高一些。所以性能要看总体跑分,而不是每赫兹跑分。
性能的另外一个含义就是指最高频率,这是从Backend设计角度来说的。Backend的人只看芯片能跑到多少频率,频率越高,对实现的时候的timing, noise等要求不一样。频率越高,在每赫兹跑分一定的情况下,总体性能就越高。请注意对于那些跑在一级缓存的程序,处理器每赫兹跑分不会随着频率的变化而变化。而如果考虑到多级缓存,总线和外围接口,那肯定就不是随处理器频率线性增加了。
从后端角度考虑,影响频率的因素有很多,比如:
首先,受工艺的影响。每一种制程(例如14nm)下面还有很多小的工艺节点,例如LP,HP等。他们之间的最高频率,漏电,成本等会有一些区别,适合不同的芯片,比如手机芯片喜欢漏电低,成本低的,服务器喜欢频率高的,不一而足。
其次,受后端库的影响。Foundry会把工艺中晶体管的参数抽象出来,做成一个物理层开发包(可以认为叫DK),提供给工具厂商,IP厂商和芯片厂商。而这些厂商的后端工程师,就会拿着这个物理层开发包,做自己的物理库。物理库一般包含逻辑和内存两大块。根据晶体管参数的不同,会有不同特性,适合于不同的用途。而怎么把这些不同特性的的库,合理的用到各个前端设计模块,就是一门大学问。一般来说,源极和漏极通道越短,电子漂移距离越短,能跑的频率就越高。可是,频率越高,动态功耗就越大,并且可能是按指数级上升。除此之外,还会有Track这种说法,指的是的标准单元的宽度。常见的有6.75T,9T等。宽度越大,电流越大,越容易做到高频,面积也越大。还有一个可调的参数就是阈值电压,决定了栅极的电压门限,门限越低,频率能冲的越高,静态功耗也越大,按对数级上升。比如需要低功耗(更多使用HVT的晶体管)或者高性能(更多使用LVT,ULVT)的晶体管。
接下来,受布局和布线的影响。芯片里面和主板一样,也是需要多层布线的,每一层都有个利用率。总体面积越小,利用率越高,布线就越困难。而层数越多,利用率越低,成本就越高。在给出一些初始和限制条件后,EDA软件会自己去不停的计算,最后给出一个可行的频率和面积。就好像下图,Metal Stack表明,整个芯片是9层Stack。
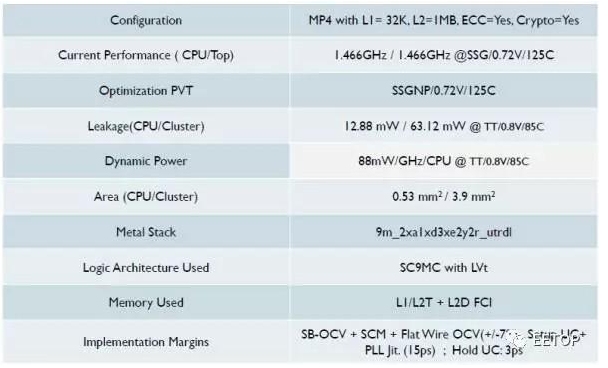
再次,受前后端协同设计的影响。处理器的关键路径直接决定了最高频率。这一部分,还没体会,先放着,不懂。
从功耗角度,同样是前后端协同设计,某个访问片上内存的操作,如果知道处理器会花多少时间,用哪些资源,就可以让内存的空闲块关闭,从而达到省电的目的。比如Clock Gating,Power Gating等都是用来干这事的。
对于移动产品,静态功耗也是很有用的一个指标。静态就是晶体管漏电造成的,大小和芯片工艺,晶体管数,电压相关。控制静态功耗的方法是power gating,关掉电源,那么静态和动态功耗都没了。
另外,就是动态功耗。动态是开关切换造成的,所以和晶体管数,频率,电压相关。动态调频调压(DVFS)的控制方法是clock gating,频率变小,自然动态功耗就小,降低电压,那么动态功耗和静态功耗自然都小。可是电压不能无限降低,否则电子没法漂移,晶体管就不工作了。并且,晶体管跑在不同的频率,所需要的电压是不一样的,拿16纳米来说,往下可以从0.9V变成0.72V,往上可以变成1V或者更高。别小看了这一点点的电压变化,动态功耗的变化,是和电压成2次方关系,和频率成线性关系的。而频率的上升,同样是依赖于电压提升的。所以,1.05V和0.72V,电压差了45%,动态功耗可以差3倍。
再往上,就是软件电源管理了,也就是芯片的Low Power管理策略。把每个大模块的clock gating和power gating进行组合,形成不同的休眠状态,软件可以根据温度和运行的任务,动态的告诉处理器每个模块进入不同的休眠状态,从而在任务不忙的时候降低功耗。这里就需要PVT Sensor。在每个芯片里面都有很多PVT Sensor。
频率和面积其实也是互相影响的。给定一个目标频率,选用了不同的物理库,不同的track(也就是不同的沟道宽度),不同的利用率,形成的芯片面积就会不一样。通常来说,越是需要跑高频的芯片,所需的面积越大。频率差一倍,面积可能有百分之几十的差别。对晶体管来说,面积就是成本,晶圆的总面积一定,价钱一定,那单颗芯片的面积越小,成本越低,并且此时良率也越高。
从上面我们看到,设计芯片很大程度上就是在平衡。影响因素,或者说坑,来自于方方面面,IP提供商,工厂,市场定义,工程团队。水很深,坑很大,没有完美的芯片,只有完美的平衡。在这点上,苹果是一个很典型的例子。苹果A10的CPU频率不很高,但是Geekbench单核跑分却比 A73高了整整75%,接近Intel桌面处理器的性能。为什么?因为苹果用了大量的面积换取性能和功耗。首先,它使用了六发射,而A73只有双发射,流水线宽了整整三倍。当然,三倍的发射宽度并不表示性能就是三倍,由于数据相关性的存在,发射宽度的效益是递减的。再一点,苹果使用了整整6MB的缓存,而这个数字在别的手机芯片上通常是2MB。对一些标准跑分,比如SpecInt2000/2006,128KB到256KB二级缓存带来的性能提升仅仅是7%左右,而256KB到1MB带来的提升更小,缓存面积却是4倍。第三,除了一二三级缓存之外,苹果大量增加处理器在各个环节的缓冲,比如指令预测器等。当然,面积的提升同样带来了静态功耗的增加,不过相对于提升频率,造成动态功耗增加来说,还是小的。再次,苹果引入的复杂的电源,电压和时钟控制,虽然增加了面积,但由于系统软件都是自己的,可以从软件层面就进行很精细的优化,将整体功耗控制的非常好。举个例子,Wiki上面可以得知,A10上的大核Hurricane面积在TSMC的16nm上是4.18平方毫米,而ARM的Enyo去掉二级缓存差不多是2.4平方毫米,在2.4Ghz时,SPECINT2000跑分接近,面积差了70%。
但是,也只有苹果能这么做,一般芯片公司绝对不会走苹果这样用大量面积换性能和功耗的路线,那样的话毛利就太低了。这也是为什么现在越来越多的整机厂家,愿意来自研芯片或者定制芯片的一个主要原因。
编辑:hfy
-
处理器
+关注
关注
68文章
19286浏览量
229853 -
电源管理
+关注
关注
115文章
6183浏览量
144508 -
cpu
+关注
关注
68文章
10863浏览量
211782 -
PowerPC
+关注
关注
2文章
39浏览量
30181 -
网络处理器
+关注
关注
0文章
48浏览量
13958
发布评论请先 登录
相关推荐
DFM在实际应用中的关键考虑和策略
谷歌Tensor G5芯片进入流片阶段
综合电磁兼容性设计与测试方法及案例分析

具备“制造意识“的超构透镜设计或可减少设计阶段到生产阶段转换时间
新思科技:精密光学与机器视觉应用大会分享超透镜设计制造威廉希尔官方网站
开关电源中“黑箱”的考虑

电源设计的10个阶段
6种线束设计阶段降成本方案
碳化硅芯片设计:创新引领电子威廉希尔官方网站 的未来
4月19日-20日《产品EMC正向设计与检视》公开课火热报名中
传英国芯片公司Graphcore考虑出售
英国AI芯片独角兽Graphcore考虑出售
请问DFM是如何高效PCB/PCBA可制造性设计分析的?
中国汽车制造商考虑扩大使用非车规级商用芯片范围
原理图设计阶段如何考虑静电防护设计






 工商网监
工商网监
评论