 解读NLPCC最佳学生论文:数据和预训练模型
解读NLPCC最佳学生论文:数据和预训练模型
在2020年初开始的新冠病毒蔓延影响下,NLPCC 2020采取线上+线下的会议方式,线上线下共缴费注册496人,其中现场参会总人数达372人,线上参会人数124人,另有15个赞助单位参展。汇聚了众多国内外NLP领域的知名学者。 本次会议总投稿数是445篇,会议有效投稿404篇。其中,主会有效总投稿377篇,Workshop有效投稿27篇。 在主会377篇有效投稿中,英文论文315篇,中文论文62篇;接收Oral论文83篇,其中英文论文70篇,中文论文13篇,录用率为22%;接收Poster 论文30篇。Workshop共计录取14篇论文。 在本次会议上评选出最佳论文、最佳学生论文各1篇,并进行了颁奖仪式。 来自清华大学朱小燕、黄民烈团队的王义达作为一作发表的《A Large-Scale Chinese Short-Text Conversation Dataset》获得了最佳学生论文,以下是王义达本人对获奖论文的亲自解读。

基于Transformer的大规模预训练语言模型极大地促进了开放领域对话的研究进展。然而目前这一威廉希尔官方网站 在中文对话领域并未被广泛应用,主要原因在于目前缺乏大规模高质量的中文对话开源数据。 为了推动中文对话领域的研究,弥补中文对话语料不足这一问题,我们发布了一个包含1200万对话的大规模中文对话数据集LCCC,并开源了在LCCC上预训练的大规模中文对话生成模型CDial-GPT。 开源地址:https://github.com/thu-coai/CDial-GPT 1
LCCC数据集的构建
LCCC(Large-scale Cleaned Chinese Conversation)数据集有LCCC-base与LCCC-large两个版本,其中LCCC-base和LCCC-large中各包含6.8M和12M对话。这些数据是从79M原始对话数据中经过严格清洗得到的,也是目前所开源的规模最大、清洗最严格的中文对话数据集。
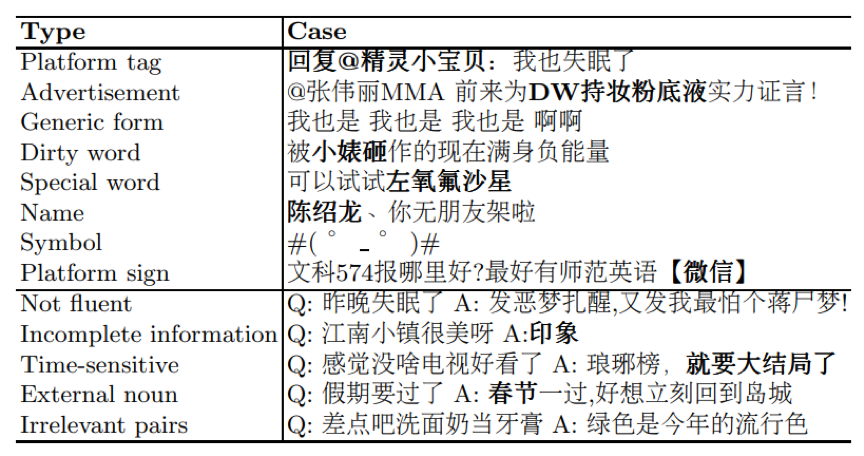
表1. 被过滤掉的噪音数据 开放领域对话数据的构建通常有三种方式:1、抽取剧本对话;2、人工众包构建对话;3、爬取社交媒体上用户的交流记录。 使用第一种方式构建的对话在内容上依赖于特定剧情和场景,与日常对话有较大差异。使用第二种方式构建的对话质量最高,但是由于人力成本过高,无法使用这一方式构建大规模数据集。使用第三种方式可以较为廉价地获取大规模对话数据,因此LCCC数据集中的原始数据主要使用第三种方式收集。 我们同时注意到,来自社交媒体的对话数据中存在各种各样的噪音(表1),为了保证LCCC中对话数据的质量,我们设计了如下数据获取和清洗策略:
1. 数据获取我们的数据获取流程分为两个阶段。在第一个阶段,我们挑选了微博上由专业媒体团队运营的新闻媒体账号,然后收集了一批在这些新闻媒体下留言互动的活跃用户。在第二个阶段中,我们收集了这些活跃用户微博下的留言互动,并将其作为我们的原始数据。微博下的留言回复一般以一个树形结构展开,我们将这一树形回复结构中每一条从根节点到叶子节点的路径作为一个完整对话,最终共收集到了79M对话数据。
2. 数据清洗为了保证数据质量,我们对收集到的原始对话数据进行了两个阶段的清洗。 第一阶段的清洗主要基于手工规则。这一阶段的主要目的是为了过滤掉对话数据中的明显噪声,如脏话、特殊符号、病句、复读机句式、广告、违法暴力信息等。在这一阶段中,我们花费了数周时间使用人工排查的方式优化规则。
第二阶段的清洗主要基于分类器过滤。在这一阶段中,我们基于BERT训练了两个文本分类器,第一个分类器主要用于甄别那些无法通过规则检测的噪音,如:1、语义模糊、语法错乱或有严重拼写错误的语句;2、时效性太强的对话;3、与上下文语义不相关的回复。 第二个分类器主要用于甄别那些需要依赖额外上下文信息,如图片或视频等,才能理解的对话。这两个分类器均使用人工标注数据训练,我们为其标注了共计11万对话数据,最终的分类器在人工标注的测试集上分别达到了73.76%和77.60%的准确率。我们通过F1-score选择阈值来过滤得到高质量的对话数据。
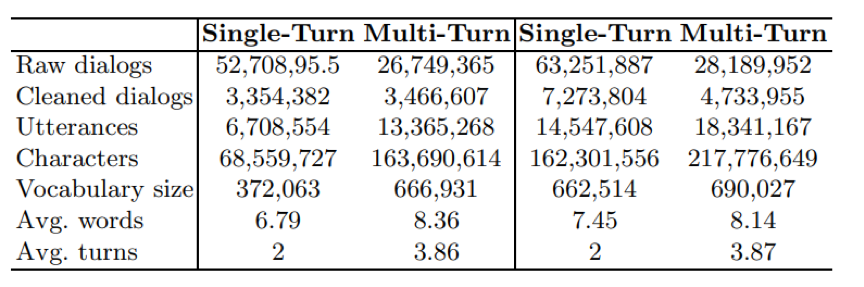
表2. 数据统计信息,左侧为LCCC-base,右侧为LCCC-large 最终我们基于上述原始对话数据过滤得到了6.8M高质量的对话数据LCCC-base。此外,我们还收集了目前已公开的其他对话数据,并使用同样的清洗流程,结合LCCC-base构造了包含12M对话的数据集LCCC-large。表2展示了这两个数据集中单轮对话和多轮对话的详细统计信息。 2
中文对话预训练模型CDial-GPT
为促进中文对话预训练模型的发展,我们基于LCCC数据集预训练了大规模中文对话生成模型CDial-GPT。该模型的训练过程包含两个阶段,首先,我们在总计5亿字符、包含各类题材的小说数据上训练得到了一个中文小说GPT预训练模型,然后在该模型的基础上,我们使用LCCC中的对话数据继续对模型进行训练,最终得到了中文对话预训练模型CDial-GPT。
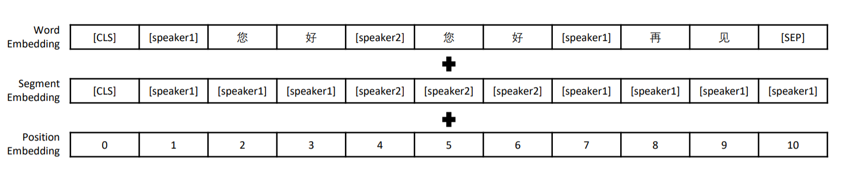
图1. 输入编码示例 该模型拥有12层Transformer结构,我们按字分词,字典大小13088,字向量维度768,最长上下文长度为513。我们沿用TransferTransfo的方式对对话进行建模,即把对话历史拼接为长文本,并使用段分割向量加以区分。具体来说:我们使用[CLS]字符标志文本起始,在段落后使用[SEP]字符表示段落结束,在段落中对相邻轮次对话使用[speaker1]、[speaker2]交替分割,并在segment embedding中使用[speaker1]、[speaker2]进行编码。图1为输入数据示例。 3
模型效果评测
为了评估对话预训练模型的质量,我们在440万规模的中文对话数据集STC上对其进行了评测实验,并对比了现有的中文对话预训练模型和一些经典的非预训练对话模型。我们主要通过PPL这一指标来反映模型的拟合能力,PPL越低表示模型的拟合能力越强。我们通过基于n-gram重合度的指标BLEU和基于Embedding相似度的指标Greedy Matching 和Embedding Average来衡量对话回复与真实回复的相关性,并通过Dist-n指标来衡量生成回复的多样性。实验结果展示在表3中。可以看到我们的模型在绝大多数指标上达到了最好的效果。由于自动指标无法完全反映生成对话的质量,于是我们对各模型生成的对话进行了人工评测。
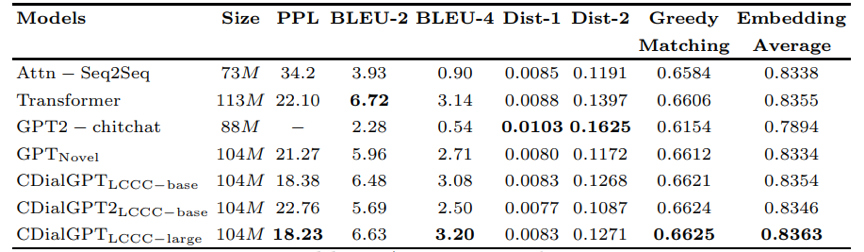
表3. 自动指标评估
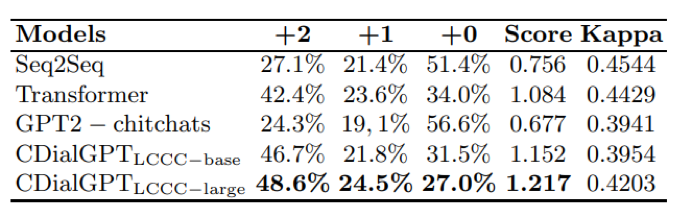
表4. 人工评价 在人工评测中我们主要考虑3个方面:1、语法性,也就是生成语句的流畅性;2、相关性,即生成语句与对话上文的相关性;3、信息量,即生成结果自身含有的信息量。具体来说,不符合语法性或与对话上文不相关的生成结果我们给予0分;语句流畅、和对话上文相关但信息量不足的生成结果给予1分;语句流畅、和对话上文相关并且信息量充足的生成结果给予2分,我们将人工评测结果展示在表4中。实验结果显示,我们的预训练模型拥有出色的生成质量,可以在生成信息量充足的回复的同时,保持较高的流畅性与相关性,优于其他基线模型,一些生成例子展示在表5,6中。
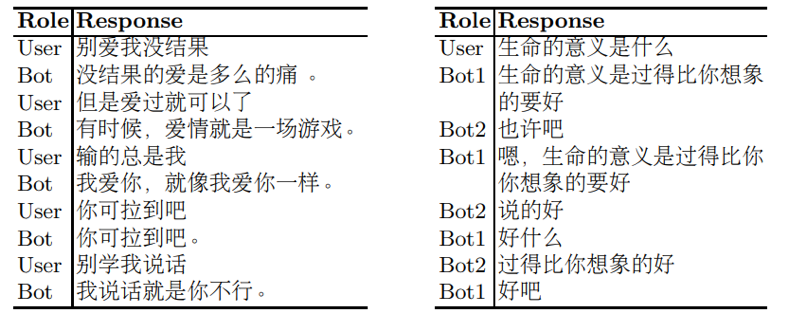
表5. 人机交互示例 (左)和 模型互相交互示例(右)
表6.在STC微调的生成结果示例 目前CDial-GPT模型以及LCCC数据集都已公开,我们提供了训练以及微调代码,可以方便地应用于各种数据和下游任务上。
责任编辑:xj
原文标题:一作解读NLPCC最佳学生论文:1200万中文对话数据和预训练模型CDial-GPT
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
-
数据
+关注
关注
8文章
7006浏览量
88955 -
nlp
+关注
关注
1文章
488浏览量
22033 -
训练模型
+关注
关注
1文章
36浏览量
3812
原文标题:一作解读NLPCC最佳学生论文:1200万中文对话数据和预训练模型CDial-GPT
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
KerasHub统一、全面的预训练模型库

直播预约 |数据智能系列讲座第4期:预训练的基础模型下的持续学习






 工商网监
工商网监
评论