 基于FPGA集群的NEST仿真器设计
基于FPGA集群的NEST仿真器设计
本案例来源于第三届全国大学生FPGA创新设计竞赛中江南大学的OpenHEC lab团队,他们的作品基于PYNQ开源软件框架。PYNQ框架提供了完整的访问FPGA资源的Python library,通过高层次的封装,让开发者通过Python API就可以轻松调用FPGA内的模块或算法,加速产品开发部署。
由于篇幅有限,我们将其作品分为两期进行介绍。这期我们主要介绍本作品的设计概述 和最终能达到的效果,下一期将会向大家展示作品详细的加速设计。有关作品的资料可以在参考文献中的GitHub链接自行下载。
第一部分 设计概述
1.1、设计目的
- 通过基于SNN的类脑计算方式更好地解决无监督的图像识别问题通过软硬件协同的方式更好地探索大规模、低功耗类脑系统的设计空间
- 通过开源开放推动更多人开展基于FPGA的类脑体系结构研究与学习[1]。
1.2、威廉希尔官方网站 特点
- 提供基于脉冲神经网络的图像识别的解决方案;
- 支持开源类脑计算仿真框架PYNN[2]、脉冲神经网络仿真器NEST[3];
- 提供基于类脑计算的神经元模块硬件加速和突触模块硬件加速模块;
- 支持PYNQ集群,采用MPI多进程和OpenMP多线程设计。
第二部分 系统组成及功能说明
2.1、基于脉冲网络的皮质层视觉仿真模型介绍
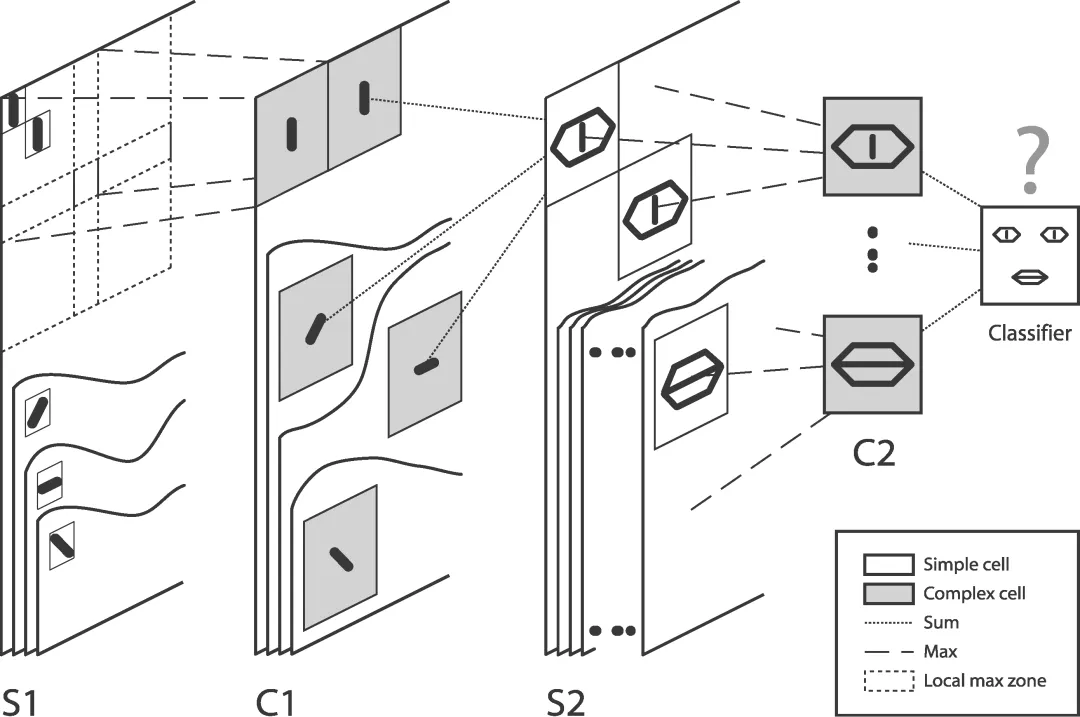
基于脉冲神经网络的皮质层视觉仿真模型由5层尖峰神经元组成。层与层之间以脉冲的方式进行信息传递,C1-S2层之间采用STDP(Spike-Timing-Dependent Plasticity)算法对对象特征进行学习。该网络架构属于麻省理工学院Riesenhuber&Poggio提出的HMAX模型中的一种[5][6],通过interwetten与威廉的赔率体系 哺乳动物脑皮层视觉,实现对图像识别的功能,如图1所示。
2.2、基于PYNQ集群的类脑计算平台介绍
本系统由包含PYNN类脑框架、NEST仿真器、FPGA神经元和STDP硬件模块。如图2所示,顶层应用设计语言为Python,在PYNN架构协助下调用NEST仿真器,各种命令通过python interpreter和SLI interpreter解释后,进入NEST kernel。根据各种命令进行底层网络创建包括神经元创建、突触连接创建、仿真时间设置等。
在此基础上,本组设计了FPGA神经元加速模块和FPGA STDP突触加速模块,根据不网络拓扑和计算要求,为不同计算密集点提供加速模块。
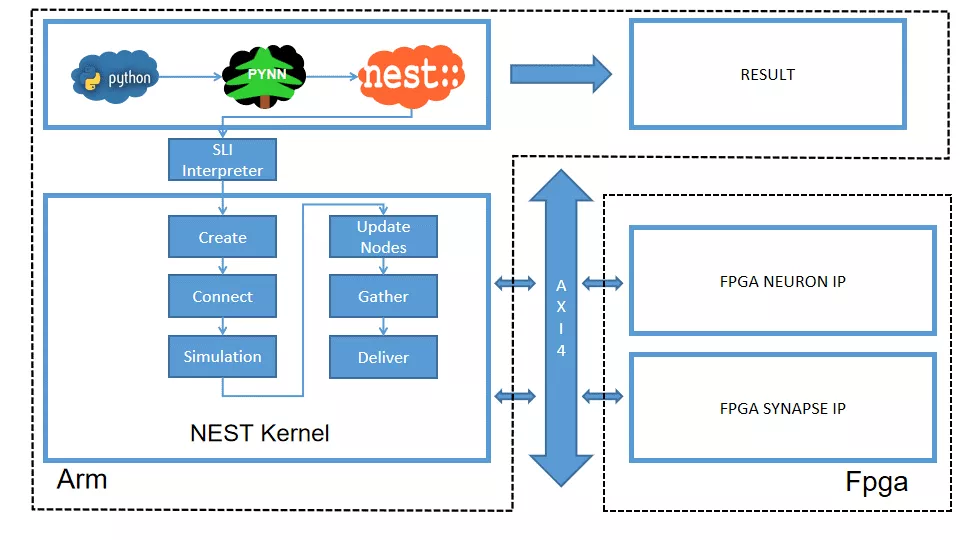
图2 类脑计算平台整体框架
2.3、通用的类脑仿真实验平台
如图3所示,本课题的通用平台集成8块PYNQ板,板级连接遵循TCP/IP协议。PYNQ-Z2 开发板以 ZYNQ XC7Z020 FPGA为核心,配备有以太网,HDMI输入/输出,MIC输入,音频输出,Arduino 接口,树莓派接口,2 个 Pmod,用户 LED,按钮和开关。
2.4、NEST系统介绍
NEST作为一款非常流行的类脑模拟器开源软件,应用广泛。NEST一大优势是可用于模拟任何规模的脉冲神经网络,如可模拟哺乳动物的视觉或听觉皮层这样的信息处理模型。也可模拟网络活动的动力学模型,比如层状皮质网络或平衡随机网络以及学习和可塑性模型。同时NEST的另一大优势就是支持集成式的MPI、OpenMP通讯协议,可以进行分布式计算大大提高仿真速度。
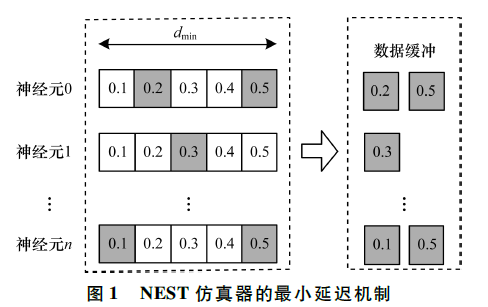
如图2所示,NEST的主体结构分为创建模型、连接模型,模拟仿真。仿真模块分为突触传递、更新神经元、MPI传输。针对对应用计算密集点分析,本设计主要是对于更新神经元模块和突触模块进行加速。
第三部分 完成情况及性能参数
3.1、软硬件环境介绍
- NEST仿真器: NEST 2.14.0版本。
- 皮质层视觉仿真模型:最小延迟为1ms,仿真精度为0.1ms,总生物仿真时间为50ms,神经元数量为48904,突触数量为275456。
- FPGA设计软件:Xilinx Vivado 2018、Xilinx Vivado HLS 2018。
- CPU:Inter Xenon E5-2620,其内存为128GB DDR3。
- FPGA集群系统:FPGA集群包含8个Xilinx PYNQ节点,每个节点包括PS(Process System)端的ARM A9双核处理器系统和一个PL(可编程逻辑)端的FPGA器件。FPGA时钟频率为100MHZ。FPGA板卡之间采用1000Mbps网络带宽的以太网进行通信,并采用TCP/IP协议。
3.2、皮质层视觉模型仿真结果
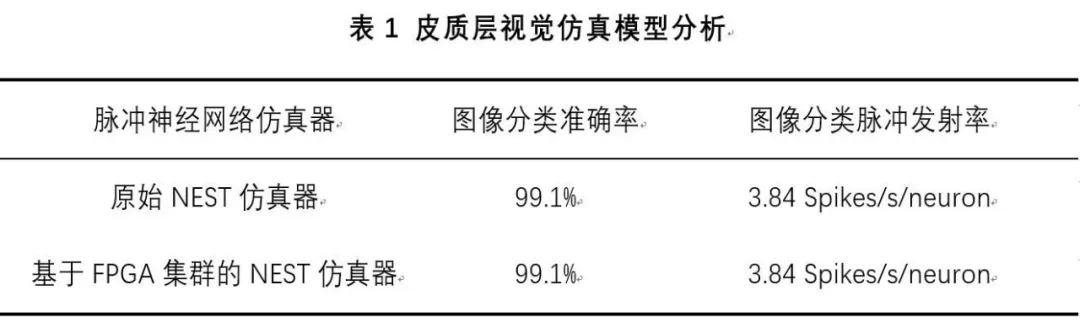
本文NEST仿真器中神经元计算模块采用单精度浮点数据精度,与原NEST仿真器的神经元计算模块双精度浮点数据精度相比,在皮质层视觉模型仿真图像分类的准确率和脉冲发射率方面并无差别,其结果如表1所示。
3.3、性能评估
本文实现基于FPGA集群的脉冲神经网络仿真器NEST,以皮质层视觉模型仿真为案例,分别对比Inter服务器版CPU Xenon E5-2620和ARM A9双核CPU,其时钟频率、内存、性能等,如表2所示:

本文中实现的基于FPGA集群的NEST仿真器,在计算能效方面,其单个节点能效是ARM A9的30倍,是Inter Xeon E5-2620的56.10倍;FPGA集群的能效是Inter Xeon E5-2620的43.93倍,是ARM A9的23.54倍。在速度方面,单个节点速度是ARM A9的33.21倍,是Inter Xeon E5-2620的1.97倍;FPGA集群的速度是ARM A9的208倍,是Inter Xeon E5-2620的12.36倍。
参考文献
1. https://github.com/OpenHEC/SNN-simulator-on-PYNQcluster.
2. http://neuralensemble.org/PyNN/.
3. https://www.nest-simulator.org/.
4. Masquelier, Timothée, Thorpe S J. Unsupervised Learning of Visual Features through Spike Timing Dependent Plasticity[J].PLoS Computational Biology, 2007, 3(2):e31.
5. Serre T, Wolf L, Poggio T (2005) Object recognition with features inspired by visual cortex. CVPR 2: 994–1000.
6. Riesenhuber M, Poggio T (1999) Hierarchical models of object recognition in cortex. Nat Neurosci 2: 1019–1025.
-
FPGA
+关注
关注
1629文章
21736浏览量
603259 -
仿真器
+关注
关注
14文章
1018浏览量
83739 -
图像识别
+关注
关注
9文章
520浏览量
38270 -
Nest
+关注
关注
1文章
47浏览量
16264
发布评论请先 登录
相关推荐
基于FPGA的类脑计算平台 —PYNQ 集群的无监督图像识别类脑计算系统
基于VC的飞行仿真器导航仿真系统开发
Ansoft仿真器
什么是单片机仿真器_单片机仿真器有什么用_单片机仿真器怎么用
米尔科技ULINKpro D 仿真器介绍

ModelSim仿真器的主要特点以及用法解析
基于FPGA集群的NEST脉冲神经网络仿真器
STM32-DAP仿真器的使用(1)

仿真器是什么?语音芯片的仿真器有几种?






 工商网监
工商网监
评论