 在语音处理中,通过使用大数据可以轻松解决很多任务
在语音处理中,通过使用大数据可以轻松解决很多任务
在语音处理中,通过使用大量数据可以轻松解决很多任务。例如,将语音转换为文本的 自动语音识别 (Automatic Speech Recognition,ASR)。相比之下,“非语义”任务侧重于语音中含义以外的其他方面,如“副语言(Paralinguistic)”任务中包含了语音情感识别等其他类型的任务,例如发言者识别、语言识别和某些基于语音的医疗诊断。完成这些任务的训练系统通常利用尽可能大的数据集来确保良好结果。然而,直接依赖海量数据集的机器学习威廉希尔官方网站 在小数据集上进行训练时往往不太成功。
为了缩小大数据集和小数据集之间的性能差距,可以在大数据集上训练 表征模型 (Representation Model),然后将其转移到小数据集的环境中。表征模型能够通过两种方式提高性能:将高维数据(如图像和音频)转换到较低维度进而训练小模型,而且表征模型还可以用作预训练。此外,如果表征模型小到可以在设备端运行或训练,就能让原始数据始终保留在设备中,在为用户提供个性化模型好处的同时,以保护隐私的方式提高性能。虽然表征学习已普遍用于文本领域(如 BERT和 ALBERT)和图像领域(如 Inception 层 和 SimCLR),但这种方法在语音领域尚未得到充分利用。
下:使用大型语音数据集训练模型,然后将其推广到其他环境;左上:设备端个性化 - 个性化的设备端模型将安全和隐私相结合;中上:嵌入向量的小模型 - 通用表征将高维度、少示例的数据集转换到低维度,同时不降低准确率;较小的模型训练速度更快,并且经过正则化。右上:全模型微调 - 大数据集可以使用嵌入向量模型作为预训练以提高性能
如果没有一个衡量“语音表征有用性”的标准基准,就很难显著地改进通用表征,尤其是对于非语义语音任务。尽管 T5框架系统地评估了文本嵌入向量,并且视觉领域任务自适应基准 (VTAB) 对图像嵌入向量评估进行了标准化,两者均促进了相应领域表征学习的进展,但对于非语义语音嵌入向量却没有类似基准。
在“Towards Learning a Universal Non-Semantic Representation of Speech”中,我们对语音相关应用的表征学习做出了三项努力:
提出一个比较语音表征的非语义语音 (NOn-Semantic Speech,NOSS) 基准,其中包括多样化的数据集和基准任务,例如语音情感识别、语言识别和发言者识别。这些数据集可在TensorFlow Datasets 的“音频”部分中找到。
创建并开源了 TRIpLet Loss 网络 (TRILL),此全新模型小到可以在设备端执行和微调,同时仍然优于其他表征模型。
进行了大规模研究来比较不同的表征,并开源了用于计算新表征性能的代码。
Towards Learning a Universal Non-Semantic Representation of Speech
https://arxiv.org/abs/2002.12764
这些数据集
https://tensorflow.google.cn/datasets/catalog/overview#audio
TensorFlow Datasets
https://tensorflow.google.cn/datasets/
TRIpLet Loss 网络
https://aihub.cloud.google.com/s?q=nonsemantic-speech-benchmark
开源
https://github.com/google-research/google-research/tree/master/non_semantic_speech_benchmark
语音嵌入向量的新基准
为了能够有效指导模型开发,基准必须包含具有类似解决方案的任务,并排除存在显著差异的任务。既往工作或为独立处理各种潜在语音任务,或为将语义任务和非语义任务归纳在一起。我们的工作在一定程度上通过关注在语音任务子集上表现良好的神经网络架构,提高了非语义语音任务的性能。
NOSS 基准的任务选择依据:
多样性 - 需要覆盖一系列使用案例;
复杂性 - 应该具有挑战性;
可用性,特别强调开源任务。
我们结合了具有不同规模和任务的六个数据集。
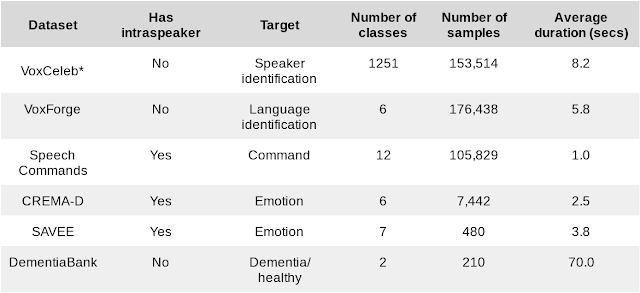
下游基准任务的数据集
*我们的研究使用根据内部政策筛选的数据集子集计算 VoxCeleb 结果
我们还引入了三个额外的演讲者内部任务,并测试个性化场景下的性能。在具有 k 个演讲者的某些数据集中,我们可以创建 k 个不同的任务,只针对单一演讲者进行训练和测试。整体性能是各演讲者的平均值。三个额外的演讲者内部任务衡量了嵌入向量适应特定演讲者的能力,这是个性化设备端模型的必要能力。随着 ML 向智能手机和物联网延伸,这些模型变得越来越重要。
为了帮助研究人员比较语音嵌入向量,我们已经将基准中的六个数据集添加到 TensorFlow Datasets 中(在“音频”部分),并开源了评估框架。
将基准中的六个数据集添加到 TensorFlow Datasets 中
https://tensorflow.google.cn/datasets/catalog/overview#audio
开源了评估框架
https://github.com/google-research/google-research/tree/master/non_semantic_speech_benchmark
TRILL:非语义语音分类的新威廉希尔官方网站
在语音领域中,从一个数据集学习嵌入向量并将其应用到其他任务不如其他模式中那样普遍。然而,使用一项任务的数据帮助另一项任务(不一定是嵌入向量)的迁移学习,作为一种更为通用的威廉希尔官方网站 ,具有一些引人注目的应用,例如个性化语音识别器和少量样本的语音模仿:文本到语音的转换。过去已经有多种语音表征,但其中大多是在较小规模和较低多样性的数据上进行训练,或主要在语音识别上进行测试,或两者皆有。
我们基于约 2500 小时语音的大型多样化数据集 AudioSet 为起点,创建跨环境和任务的实用数据衍生语音表征。我们通过先前的度量学习工作得出简单的自监督标准,在此标准上训练嵌入向量模型 - 来自相同音频的嵌入向量在嵌入向量空间中应该比来自不同音频的嵌入向量更为接近。与 BERT 和其他文本嵌入向量类似,自监督损失函数不需要标签,只依赖于数据本身的结构。这种自监督形式最适合非语义语音,因为非语义现象在时间上比 ASR 和其他亚秒级语音特征更稳定。这种简单的自监督标准捕获了下游任务所用的大量声学特性。
AudioSet
https://research.google.com/audioset/
TRILL 损失:来自相同音频的嵌入向量在嵌入空间中比来自不同音频的嵌入向量更为接近
TRILL 架构基于 MobileNet,其速度适合在移动设备上运行。为了在这种小架构上实现高准确率,我们在不降低性能的同时从更大的 ResNet50 模型中提取出嵌入向量。
基准结果
我们首先比较了 TRILL 与其他深度学习表征的性能。这些表征并不局限于语音识别,并在类似的不同数据集上进行训练。此外,我们还将 TRILL 与热门的 OpenSMILE 特征提取器进行比较。OpenSMILE 使用预深度学习威廉希尔官方网站 (如:傅里叶变换系数、使用基音测量的时间序列的“基音跟踪”等)以及随机初始化网络,这些威廉希尔官方网站 已被证明是强大的基线。
为了对不同性能特征的任务进行性能汇总,我们首先针对给定的任务和嵌入向量训练少量的简单模型,选择最佳结果。然后,为了了解特定嵌入向量对所有任务的影响,我们以模型和任务为解释变量,对观察到的精度进行了线性回归计算。模型对准确率的影响即为回归模型中的相关系数。对于给定任务,从一种模型切换到另一种模型时,产生的准确率变化的差异预计为下图中 y 值。
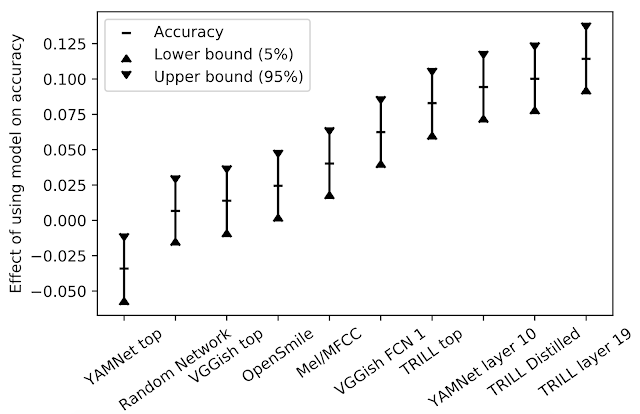
对模型准确率的影响
在我们的研究中,TRILL 性能优于其他表征。TRILL 的成功在于训练数据集的多样性、网络的上下文大窗口以及 TRILL 训练损失的通用性,最后一项因素保留了大量声学特征,而不是过早地关注特定方面。需要注意的是,来自网络层的中间表征往往更具有通用性。中间表征更大,时间粒度更细,在分类网络的情况下,它们保留了更通用的信息,而不像训练它们的类那样具体。
通用模型的另一个优势是可以在新任务上初始化模型。当新任务的样本量较小时,相较于从头训练模型,对现有模型进行微调可能会获得更好的结果。尽管没有针对特定数据集进行超参数调整,但使用此威廉希尔官方网站 ,我们仍然在六个基准任务的三个任务上取得了新的 SOTA 结果。
为了更新的表征,我们还在Interspeech 2020 Computational Paralinguistics Challenge (ComParE) 的口罩赛道中进行了测试。在挑战中,模型必须预测发言者是否佩戴口罩,因为口罩会影响语音。口罩的影响有时微乎其微,并且音频片段只有一秒。TRILL 线性模型表现比基线模型更好的性能,该模型融合了许多不同模型的特征,如传统的光谱和深度学习特征。
Interspeech 2020 Computational Paralinguistics Challenge (ComParE)
http://www.compare.openaudio.eu/compare2020/
基线模型
http://compare.openaudio.eu/wp-content/uploads/2020/05/INTERSPEECH_2020_ComParE.pdf
总结
评估 NOSS 的代码位于 GitHub,数据集位于 TensorFlow Datasets,TRILL 模型位于 AI Hub。
GitHub
https://github.com/google-research/google-research/tree/master/non_semantic_speech_benchmark
TensorFlow Datasets
https://tensorflow.google.cn/datasets/catalog/overview#audio
AI Hub
https://aihub.cloud.google.com/s?q=nonsemantic-speech-benchmark
非语义语音基准可帮助研究人员创建语音嵌入向量,适用于包括个性化和小数据集问题的各种环境。我们将 TRILL 模型提供给研究界,作为等待超越的基线嵌入向量。
致谢
这项工作的核心团队包括 Joel Shor、Aren Jansen、Ronnie Maor、Oran Lang、Omry Tuval、Felix de Chaumont Quitry、Marco Tagliasacchi、Ira Shavitt、Dotan Emanuel 和 Yinnon Haviv。我们还要感谢 Avinatan Hassidim 和 Yossi Matias 的威廉希尔官方网站 指导。
原文标题:通过自监督学习对语音表征与个性化模型进行改善
文章出处:【微信公众号:TensorFlow】欢迎添加关注!文章转载请注明出处。
-
大数据
+关注
关注
64文章
8884浏览量
137423 -
语言识别
+关注
关注
0文章
15浏览量
4825
原文标题:通过自监督学习对语音表征与个性化模型进行改善
文章出处:【微信号:tensorflowers,微信公众号:Tensorflowers】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论