 揭开F2FS与FTL“剪不断理还乱”的“爱恨交织”
揭开F2FS与FTL“剪不断理还乱”的“爱恨交织”
F2FS (Flash Friendly File System) 是专门针对SSD、eMMC、UFS等闪存设备设计的文件系统。由三星工程师Jaegeuk Kim于2012年10月发布到Linux社区,并于2012年12月进入Linux 3.8 内核主线。和UBIFS、JFFS2等文件系统不同,F2FS并不直接面向裸NAND闪存设计,而是和其他通用文件系统一样基于块设备层接口实现。既然如此,为什么说F2FS是针对SSD、EMMC、UFS等闪存设备设计呢?另一方面SSD、eMMC、UFS等拥有FTL(Flash Translation Layer)的闪存存储已经对外提供了通用块设备接口,是否真的需要针对性地设计一个文件系统呢?F2FS的“Flash Friendly”体现在哪些方面呢?请跟随本文对F2FS的设计实现做详细拆解,揭开F2FS与FTL“剪不断理还乱”的“爱恨交织”。
F2FS继承了日志结构文件系统的衣钵,使用异地更新的数据写入方式化随机为顺序。同时改善了日志结构文件系统的一些已知问题,如滚雪球效应和高清理开销。而FTL为了对上隐藏NAND闪存无法覆盖写的特性(先擦后写),其内部实现也采用了类似的日志结构写入方式。从软件模块化设计的角度看,两个层次的相近冗余设计似乎并不合理。然而存在即合理,F2FS实际上是摸准了FTL的软肋:那就是由于缺少上层(系统层、应用层)信息,FTL并不能很好的实现冷热分离、做到高效垃圾回收、减少写放大。同时FTL承载了太多目标:地址映射、磨损均衡、坏块管理等等,以及一些器件厂商无法言说的原因导致将FTL上移到软件层或是提供地址映射表等接口困难重重。因此即使拥有FTL,SSD、eMMC、UFS等设备也是需要一个针对性设计的文件系统来实现性能和寿命的优化。
F2FS虽然基于通用块设备层接口实现,但并不像通用文件系统一样无差别的对待机械磁盘和闪存盘,在设计上是”flash-awared”。根据闪存内部结构和闪存管理机制(FTL),F2FS可通过多个参数配置磁盘布局、选择分配和回收单元大小从而适配不同实现的闪存存储设备。为方便理解F2FS,我们先简单介绍下FTL的地址映射方式和日志结构文件系统,然后从空间布局和索引结构入手建立F2FS的基本概念,进而深入到冷热分离、垃圾回收、块分配等细节中去。
FTL的地址映射方式
FTL(Flash Translation Layer)的本职工作是完成Host端逻辑地址到Flash侧物理地址的映射。需要地址映射的原因是闪存只能异地更新,为了对上支持数据块原地更新则需要通过地址转换实现。由于闪存先擦后写、擦写有次数限制(寿命)、使用过程中会不断出现坏块(块寿命不同)等特性,FTL还需具备垃圾回收、磨损均衡、坏块管理等十八般武艺。闪存内部的基本存储单位是Page(4KB),N个Page组成一个Block。这里主要介绍下逻辑地址LPN(Logical Page Number)到物理地址PPN(Physical Page Number)的映射方式:
块级映射:将块映射地址分为两部分:块地址和块内偏移。映射表只保存块的映射关系,块内偏移直接对应。映射表比较小,需要内存(RAM)少。但无法很好的处理随机写,容易产生频繁的有效数据搬移和块擦除操作。
页级映射:映射表维护每个页的映射关系,这种方式灵活,能有效减少数据搬移。缺点是映射表很大(每个表项内容为PPN以4字节计算,128GB的闪存存储需要128GB/4KB*4B=128MB大小的内存保存映射表),约占存储容量的千分之一。
混合映射:主要思路是针对频繁更新的数据采用页级映射,很少更新的数据采用块级映射。其中采用Log Structed思想的混合映射将存储分为数据块(Data Block)和日志块(Log Block)。数据块用于存储数据,采用块级映射,日志块用于存储对于数据块更新后的数据,采用页级映射。混合映射是低端SSD、eMMC、UFS广泛采用的映射方式。根据日志块和数据块的对应关系又可以分为全相关映射(FAST)、块相关映射(BAST)、组相关映射(SAST)等等。下图是SAST映射的一个示例:2个日志块对应4个数据块,当日志块用完时需要通过搬移有效数据回收日志块。对于顺序写场景,最好情况下日志块对应位置记录了数据块的更新,则可以无需搬移数据,直接将日志块作为新的数据块,数据块进行擦除操作作为新的日志块。对于大量随机写场景,则需要将日志块和数据块中的有效数据搬移到空闲块的对应位置作为新的数据块,然后擦除原日志块和数据块。
图1 SAST映射数据搬移示例
日志结构文件系统
日志结构文件系统,Log Structured File System(注意:不是Journaling File System。Journaling File System是指在磁盘特定区域记录所有写入动作以便在需要时回溯和恢复,如:EXT4)思想的提出非常早,可以追溯到1992年时任UC Berkeley计算机系教授的John Ousterhout和他的学生Mendel Rosenblum发表的论文“The Design and Implementation of a Log-Structured File System”。John Ousterhout还是强大的Tcl语言(Tool Command Language,读:tickle,不是家电品牌哦)的发明者,就是下图这位白眉老爷爷。
图2 Tcl、LFS作者John Ousterhout
日志结构文件系统将所有的更改以日志式的结构连续的写入磁盘,以此加速文件写入和崩溃恢复。日志中包含索引信息,文件可以被高效的读出。为了快速的写入需要保留大块的空闲区域,可以将日志分成多个固定大小的连续空间——段(segment),在空闲区域不足时通过在碎片化的段中搬移有效数据回收新的连续空间。文章中还介绍了基于日志结构文件系统理念实现的Sprite LFS,较当时的UNIX文件系统FFS在小文件随机写上性能提升一个数量级。即使去除垃圾回收的开销,仍可以利用70%的磁盘带宽。日志结构文件系统如此优秀的写入性能不是没有代价的,如何高效的进行垃圾回收保持较高的写入性能特别是剩余空间较少、碎片化严重后的性能一直是众多日志结构文件系统致力于解决的问题。
下图展示了一个日志结构文件系统基本的索引结构和空间布局,以及数据更新方式。超级块Super Block(SB)自不必说,用于保存文件系统的基础信息。检查点Checkpoint(CP)则是指文件系统某一时点所有文件系统有效数据、索引结构一致完整的记录。创建检查点通常分两步:1.落盘所有文件数据、索引、inode表、段使用情况表,2.在固定的检查点区记录所有有效的inode表和段使用情况表地址以及时间戳等。为了应对检查点过程中的系统崩溃,实际有两个检查点区交替更新。由于时间戳是检查点最后更新的内容,每次重启后只需选择最新的检查点区即可保证有效性。在恢复到检查点后,还可根据日志记录继续前向恢复(roll-forward)数据。F2FS就针对单个文件的fsync实现了前向恢复能力,fsync时只需落盘文件数据和其直接索引。
除了超级块和检查点是保存在固定位置的,其他元数据和数据都是异地更新的日志。以更新一个文件的内容为例:先写入文件数据内容,再更新各级索引块,最后还要更新Inode Map。这种更新数据带来的索引数据更新问题被形象的称为“滚雪球效应”(英文语境中为:Wandering Tree),这也是日志结构文件系统的另一大问题。
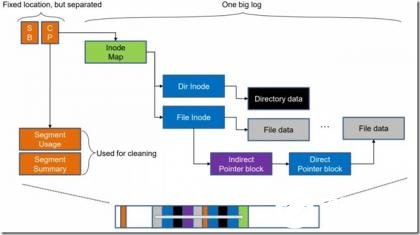
图3日志结构文件系统索引结构和数据更新示意图
接下来的部分,我们先看F2FS如何在空间布局和索引结构上解决“滚雪球”效应,再看基于空间布局的冷热分离和垃圾回收算法如何减少回收代价以及块分配策略对碎片化后写性能的改善。
空间布局和索引结构
F2FS的空间布局在设计上试图匹配闪存存储内部的组织和管理方式。如下图所示,整个存储空间被化分为固定大小的Segment。Segment是F2FS空间管理的基本单元,也确定了文件系统元数据的初始布局。一定数量连续的Segment组成Section,一定数量连续的Section组成Zone。Section和Zone是F2FS日志写入和清理的重要单元,通过配置合适的Section大小可以极大地减少FTL层面垃圾回收的开销。
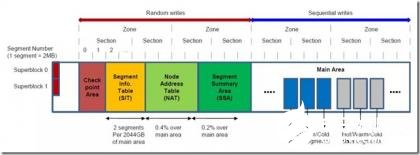
图4 F2FS空间布局
整个存储空间被划分为6个区域:
超级块(SB)包含基本分区信息和F2FS在格式化分区时确定不可更改的参数
检查点(CP)保存文件系统状态,有效NAT/SIT(见下文说明)集合的位图,孤儿inode列表(文件被删除时尚有引用无法立即释放时需被计入此列表,以便再次挂载时释放)和当前活跃段的所有者信息。和其他日志结构文件系统一样,F2FS检查点时某一给定时点一致的文件系统状态集合——可用于系统崩溃或掉电后的数据恢复。F2FS的两个检查点各占一个Segment,和前述不同的是,F2FS通过检查点头尾两个数据块中的version信息判断检查点是否有效。
段信息表Segment Information Table(SIT)包含主区域(Main Area,见下文说明)中每个段的有效块数和标记块是否有效的位图。SIT主要用于回收过程中选择需要搬移的段和识别段中有效数据。
索引节点地址表Node Address Table(NAT)用于定位所有主区域的索引节点块(包括:inode节点、直接索引节点、间接索引节点)地址。即NAT中存放的是inode或各类索引node的实际存放地址。
段摘要区Segment Summary Area (SSA)主区域所有数据块的所有者信息(即反向索引),包括:父inode号和内部偏移。SSA表项可用于搬移有效块前查找其父亲索引节点编号,
主区域 Main Area由4KB大小的数据块组成,每个块被分配用于存储数据(文件或目录内容)和索引(inode或数据块索引)。一定数量的连续块组成Segment,进而组成Section和Zone(如前所述)。一个Segment要么存储数据,要么存储索引,据此可将Segment划分为数据段和索引段。
由于NAT的存在,数据和各级索引节点之间的“滚雪球效应”被打破。如下图所示:当文件数据更新时,我们只需更新其直接索引块和NAT对应表项即可。其他间接索引块不会受到影响。
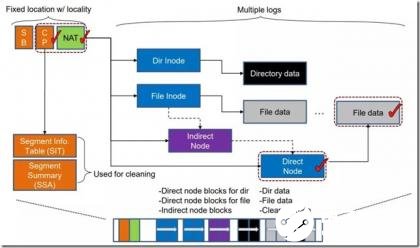
图5 F2FS索引结构
这里通过一个文件查找的小例子展示F2FS是如何工作的,假设要查找 “/dir/file”大致步骤如下:1)从NAT中获取根目录“/”的地址并读取,2)在根目录的数据块中查询目录项“dir”对应的inode号,3)通过NAT获取inode号对应的地址,4)读取“dir”的inode块,5)在目录“dir”的数据块中查询目录项“file”的inode号,然后重复类似3)和4)步的操作获取“file”的inode块。然后即可对该文件进行所需的操作,如下图所示文件数据可由inode中的文件索引获取。F2FS的inode多级索引结构类似EXT3,并没有EXT4的extent结构。这也是日志结构文件系统的普遍选择,因为考虑到垃圾回收过程对inode内部索引的改变,固定层次的索引可以避免extent区间范围变化导致索引存储空间变大的尴尬问题。F2FS最多有3级间接索引,单文件大小最大可达约3.94TB。因为数据块地址采用4字节存储,F2FS可支持的最大分区大小是16TB。从目前使用场景看,这不会成为明显限制。另外,F2FS支持inline data(数据直接存储在inode中),小文件大小最大可达约3.4KB,在Android大量小文件场景中对存取空间占用和性能有一定优化。
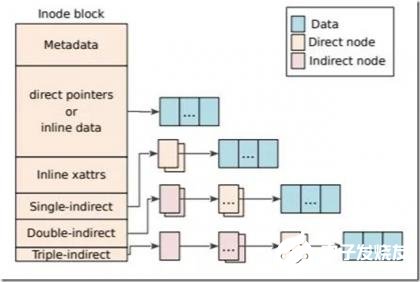
图6 F2FS的inode索引结构
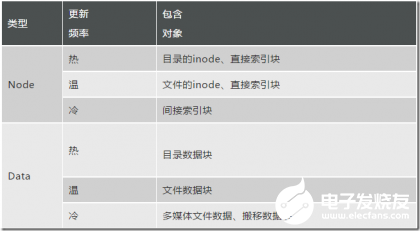
为了减少垃圾回收的开销,F2FS采用了多日志头的记录方式实现冷热数据分离。如下表所示,将数据区划分为多个不同冷热程度的Zone。如:目录文件的inode和直接索引更新频繁计入热节点区,多媒体文件数据和回收中被搬移的数据计入冷数据区。冷热分离的目的是使得各个区域数据更新的频率接近,存储空间中各个Section/Zone的有效块数量呈binomial分布(即:冷数据大多数保持有效因而无需搬移,热数据大多数更新后处于无效状态只需少量搬移)。目前F2FS的冷热分离还较为简单,结合应用场景有很大的优化空间。
表1 F2FS不同类型数据冷热划分
垃圾回收和块分配
F2FS的垃圾回收Garbage Collection(GC)分为前台GC和后台GC。当没有足够空闲Section时会触发前台GC,内核线程也会定期执行后台GC尝试清理。另外F2FS也会预留少量空间,保证GC在任何情况下都有足够空间存放搬移数据。GC过程分三步:1)搬移目标选择,两个著名的选择算法分别是贪心和成本最优(cost-benefit)。贪心算法挑选有效块最少的Section,一般用于前台GC以减少对IO的阻塞时间。Cost-benefit算法主要用于后台GC,综合了有效块数和Section中段的年龄(由SIT中Segment的更新时间计算)。该算法的主要思想是识别出冷数据进行搬移,热数据可能再接下来一段时间被更新无需搬移,这也是进行动态冷热分离的又一次机会。2)识别有效块并搬移,从SIT中可以获取所有有效块,然后在SSA中可以检索其父亲节点块信息。对于后台GC,F2FS并不会立即产生迁移块的I/O,而只是将相关数据块读入页缓存并标记为脏页交由后台回写进程处理。这个方式既能减少对其他I/O的影响,也有聚合、消除小的分散写的作用。3) 后续处理,迁移后的Section被标记为“预释放”状态,当下一个检查点完成中Section才真正变为空闲可被使用。因为检查点完成之前掉电后会恢复到前一个检查点,在前一个检查点中该Section还包含有效数据。
当空闲空间不足时,F2FS也不是“一根筋”的继续保持日志写的方式(Normal Logging)。直接向碎片化的Segment中的无效块写入数据是日志结构文件系统的另一个日志策略(Threaded Logging),又被称为SSR(Slack Space Recycling)。SSR虽然变成了随机写,但避免了被前台GC阻塞。同时通过以贪心方式选择做SSR的Section,写入位置仍然有一定的连续性。
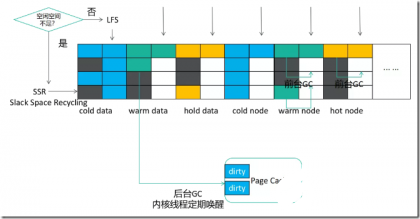
图6 F2FS的垃圾回收和空间分配
F2FS展望
F2FS从问世至今曾不被看好,某乎历史上有很多对各个手机厂商在F2FS上谜一样操作的疑问,如:“为什么三星发布的f2fs文件系统而自己的旗舰机都不使用这一文件系统?”,“F2FS文件系统既然被华为证实很好用,其他厂商为何不跟进?”。如今这些疑问都可画上句号,谷歌2018年在自家的Pixel 3手机上使用F2FS并推荐Android Go项目(低内存和存储容量配置的入门级设备)使用F2FS以改善器件寿命,三星在2019年自家旗舰上已经开始使用F2FS,目前很多手机厂商也都纷纷开始使用F2FS。
回首F2FS发展历程(放个马后炮),所有玩家的选择都是从商业利益出发:文件系统需要多年打磨才能达到稳定商用的程度,三星发布F2FS时深知这一点,通过开源借助社区力量补齐F2FS短板不可谓不“老谋深算”。华为“正面刚”则是希望借助新威廉希尔官方网站
打造品牌竞争力,F2FS之外还有方舟编译器、EROFS等等。何况还有F2FS作者Jaegeuk Kim坐镇,就是下图中这位大兄弟。其实从Jaegeuk Kim的工作履历(三星->摩托罗拉->华为->谷歌)也可以看出F2FS不断前进的路线,他不遗余力的面向Android平台推广也起到了相当程度的助力——F2FS多年来不断完善补齐特性,由于没有历史包袱大刀阔斧地针对Android平台优化。如:原子写特性提升SQLite数据库性能(DELETE等模式),优化discard下发机制和策略减少卡顿等。
图8 F2FS作者Jaegeuk Kim
展望F2FS的未来,可以看到社区的新特性(如:online resize,冷数据压缩等)在不断推出,且都能带来Android用户体验的优化,而其成熟度和稳定性也在不断提升。应用场景上,Android之外,叠瓦式磁记录盘SMR(Shingled Magnetic Recording)有望成为F2FS的又一用武之地。SMR由于磁盘设计上盘片磁道部分重叠部分存储空间只能顺序写,F2FS作为日志结构文件系统已有相应方案能很好的支持这类Zoned Block Device。限于篇幅,本文不再一一展开分析。
参考文献:
[1] Lee et. al, F2FS: A New File System for Flash Storage, FAST ‘15
[2] Rosenblum et. al, The Design and Implementation of a Log-Structured File System, SOSP ‘92
[3] Jaegeuk Kim, Flash-Friendly File System (F2FS), Korea Linux Forum(KLF) 2012
[4] SMR介绍,https://zonedstorage.io/getting-started/smr-disk/
-
NAND
+关注
关注
16文章
1682浏览量
136155 -
Linux
+关注
关注
87文章
11304浏览量
209476 -
SSD
+关注
关注
21文章
2862浏览量
117419 -
emmc
+关注
关注
7文章
216浏览量
52742 -
UFS
+关注
关注
6文章
104浏览量
24052
发布评论请先 登录
相关推荐
Micrium全家桶之uC-FS: 0x01 NAND FTL
使用ADC12DJ3200做采样系统时,发现SFDR受限于交织杂散,有什么方法降低Fs/2-Fin处的杂散?
鸿海夏普——剪不断 理还乱
如何学习嵌入式?
怎样将RK3399中data文件系统分区的格式由原先的f2fs格式变至ext4格式呢
用户论战运营商,数字电视理在谁?
剪不断,理还乱:缺“芯”危机日益严重
中关村:电子一条街的新生
三星GalaxyS10+和华为P30Pro买哪个好
Debian可以从F2FS根文件系统运行了
中美之间存在着剪不断理还乱的贸易关系






 工商网监
工商网监
评论