 一文搞懂深度学习的精密率和召回率
一文搞懂深度学习的精密率和召回率
这里,我们将讨论两个重要的度量指标,即精度和召回率,它们被用于度量分类模型(即分类器)的性能。特别地,我们将讨论如何用这两个指标来评估决策树模型。
一般来说,精确度度量针对的问题是“有多少选定的项目是相关的?”而召回率度量针对的问题是“有多少相关的项目被选中?”
精密率和召回率的定义
在定义精确度和召回率之前,我们首先需要澄清几个概念。
假设我们有一个分类器来判断一张图片是否包含cat,目标标签(class)有两个值:[cat, non-cat]。分类器也会输出两个可能的值。例如,给定一组已标记的图片,我们应用分类器为每幅图片预测一个标签。如下表所示,根据图片实际标签和预测标签,有4种可能的情况。在许多文献中,该表也称为混淆矩阵。
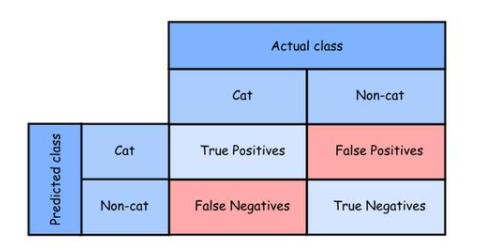
由于分类器的目的是预测图片中是否有猫,所以当分类器以“cat”的形式给出预测结果时,我们称预测结果为正,称“not-cat”预测结果为负。我们将上表中的4种情况详细说明如下:
True Positive (Tp)
对于一幅图,如果预测的类别是正的(例如cat),而该图的实际类别碰巧也是正的,则我们称这种情况为真正
True Negative (Tn)
对于一个图片,如果预测的类是负的(即not-cat),而实际的类碰巧也是负的,那么我们就称这种情况为真负。
False Positive (Fp)
对于一幅图,如果预测的类是正的(即cat),但该图的实际类是负的(not-cat),则我们称这种情况为假正。
False Negative (Fn)
对于一幅图片,如果所预测的类别是否定的(即not-cat),但该图片的实际类别是肯定的(即cat),则我们称这种情况为假否定。
根据上述定义,我们现在可以定义精确度和召回率的度量。
精度(P)定义为真正(Tp)与所有是正预测(Tp+Fp)的比值,即真正的数与假正的数的比值。
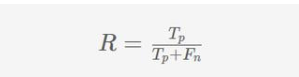
当分类器声称样本为正时,我们可以将精度度量解释为确定性。例如,一个标识符,如果Tp = Fp = 50,那么它的精度P = 50/(50 + 50) = 0.5 即我们可以说只要分类器声称,结果是正的,只有50%概率分类器实际上是正确的。
如果我们认为实际的正的项(样本)是“相关的”,声称的正的项目是“被选择的”,那么精度度量回答了多少被选择的项目是相关的问题,正如文章开始所述的那样。
召回率(R)定义为真正性(Tp)与所有正样本(Tp+Fn)的比值,即真正的数量与假负的数量之和。
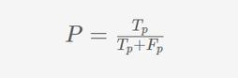
我们可以将召回度量解释为分类器识别出的实际正性案例的百分比。例如,一个标识符,如果Tp = Fn = 50 ,然后召回率R = 50/(50 + 50) = 0.5,也就是说我们只能说分类器仅获得50%实际正性案例的50%,而对另外50%的实际正案例进行了错误分类。
举个例子
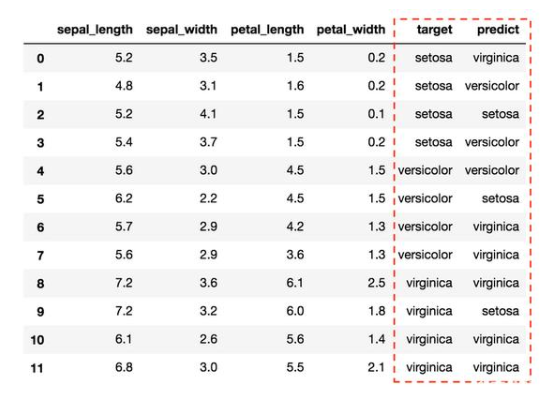
利用上述公式,我们可以得到每个标签的精度和召回率,如下:
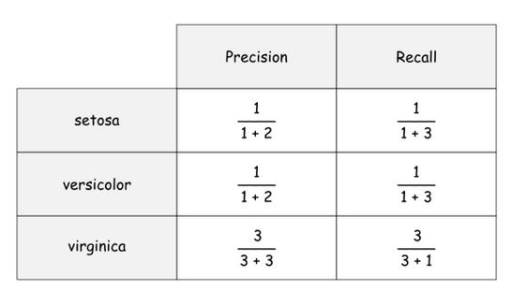
说明:我们以“setosa”这个标签为例来说明详细。对于“setosa”标签,从第0行到第3行总共有4个实际正的样本,模型给出了3个正预测(即在第2、5、9行),对于“setosa”标签,只有一个真实正,位于第2行。setosa的假正位于第5行和第9行。最后,setosa的假负性为3例,分别位于第0、1、3行。
什么是准确度???
除了精确率和召回率之外,还有一个众所周知的度量标准叫做准确度,它被用来衡量分类模型的性能。
准确性(A)定义为对所有预测(Tp+Tn+Fp+Fn)的真实结果(包括真正(Tp)和真负(Tn))的比例。
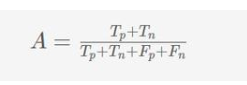
与精确率-召回率相比,准确率似乎是一种更加平衡的衡量标准,因为它同时考虑了真正的正因素和真正的负因素。然而,事实证明,准确性实际上是一个误导的度量,特别是对于不平衡的数据集。例如,对于包含5封垃圾邮件(即正样本)和95封普通邮件(即负样本)的数据集,简单地将所有样本预测为负(非垃圾邮件)的低级的垃圾邮件分类器将获得95%高精度。垃圾邮件分类器在使用精确率召回率度量时,其精确度和召回率为零,这更准确地反映了分类器的实际预测能力。因此,在实践中,人们更喜欢精确率召回率来度量而不是准确度作为他们分类器的基准。
-
分类器
+关注
关注
0文章
152浏览量
13180 -
性能指标
+关注
关注
0文章
14浏览量
7900 -
深度学习
+关注
关注
73文章
5500浏览量
121118
发布评论请先 登录
相关推荐


示波器的采样率和示波器存储深度
一文搞懂UPS主要内容
基于深度学习和3D图像处理的精密加工件外观缺陷检测系统
如何估算深度神经网络的最优学习率(附代码教程)
数据外补偿的深度网络超分辨率重建

深度学习优化器方法及学习率衰减方式的详细资料概述
AI垃圾分类的准确率和召回率达到99%
深度学习中的学习率调节实践
什么是基于深度学习的超分辨率





 工商网监
工商网监
评论