 多级分层分区和建模方案中涉及的主要时序和实现挑战
多级分层分区和建模方案中涉及的主要时序和实现挑战
多级分层分区和实现涉及包含内部物理子分区的分区。换句话说,在这种方法中,对分区本身进行分层分割。考虑SoC分区方案的示例,如图1所示。级别0对应于整个芯片的单个平面实现,其中唯一被建模的物理接口是与外部世界有关的那个(以蓝色显示)。换句话说,在芯片内部,只有逻辑边界,没有物理边界。

图1:SoC中典型的多级分层分区方案
跨越核心,APP_SUB_SYSTEM等的内部逻辑交互(以黑色显示)因此被覆盖在平面设计本身内。这种类型的方案本身具有最小的接口预算复杂性(在下一节中讨论),涉及分区间交互,因为只有一个分区。但是,这种方案不适用于大型设计,主要是由于EDA工具运行时间,内存和机器资源要求的限制。
为了简化这种设计方案,设计人员可以选择使用单级分层分区如第1级所示。在这种情况下,设计人员最终会得到4个物理分区或块,如表1所示。在这种方法中,工程资源方面的设计限制被放宽,但是分区间路径变得更加复杂,就预算而言,需要特别小心。将0级与1级进行比较,我们观察到在0级时只有外部接口路径导致了主要的不确定性,在1级中,几乎所有的分区间路径都为我们提供了I/O接口的类似不确定性和复杂性。然而,级别1和级别0(外部接口)的接口路径的性质或多或少相似,因此可以使用相同的方法和约束来对它们进行建模。级别0和级别1接口路径之间存在非常重要的差异。 0级接口路径由协议控制,其中一些协议具有为SoC给出的明确预算。 SoC只能遵守这些预算。另一方面,对于块间路径,预算编制位于设计者手中。没有标准协议来管理交互,预算分配通常是迭代的。
转向第2级,我们进一步将第1级的分区划分为更小的子块。有了这个,我们最终留下了7个独特的物理分区。这大大有助于减少工具运行时间和资源限制,因为设计已经分解成更小的部分;但是类似于1级,分区间路径&不确定性也在增加。在级别1的情况下,我们能够interwetten与威廉的赔率体系 类似于级别0的外部接口的分区接口;第2级带有更复杂的接口时序和实现,特别是如果涉及的路径跨越多个分区。此外,优化的好处也显着降低,因为跨物理边界的优化不会非常有效。
因此,在改进时序和实现关闭方面,多级分区通常可能是赌博。这种策略的回报取决于接口建模威廉希尔官方网站 的质量以及物理分区本身所涉及的逻辑的成熟度曲线。在下一节中,我们将讨论有关多级分区方案的一些独特挑战及其可能的解决方案(如果有的话)。
表I:图1所示设计中各种分区的层次结构级别。
TOP(1)
| 分区级别 | LEVEL 0(实例计数) | LEVEL 1(实例计数) | LEVEL 2(实例计数) |
|
分层 块 |
TOP_SOG(1) | TOP_SOG(1) | |
| DUAL_CORE_TOP(2) | DUAL_CORE_TOP (2)+核心(4) | ||
| GENERIC I/O CONTROLLER(2) | GENERIC I/O控制器(2)+IO_FIFO(2) | ||
| APP_SUB_SYSTEM(1) | APP_SUB_SYSTEM(1)+APP_CORE(1) | ||
| 总分区计数 | 1个唯一的 | 2唯一+ 2复制 | 3个唯一+4个重复 |
多级分层时序收敛和实施中的挑战
分层时序收敛固有地存在其缺点,主要是由物理边界上的界面不确定性和波纹效应驱动。除了计时,物理限制进一步造成了实施周期的其他方面的瓶颈,如平面图关闭,引脚布局,泄漏减少等。负责这些的主要因素可分为以下几类:
a)物理不确定性:
物理不确定性反映了由物理隔离引起的关闭不确定性在实现期间的分层分区。物理不确定性通常由于三个因素而产生:
i。跨接口的不可预测的数据路径分布:
跨分区边界的数据路径分布在很大程度上取决于分区的物理成熟度和逻辑成熟度。由于这种不可预测性而出现的最常见挑战之一是跨接口边界的输入/输出延迟的复杂和迭代预算。除此之外,基于附加阶段的放置,CTS和路由跳跃的不确定性进一步使这个简单的任务更加迭代和依赖于实现。让我们考虑多级分区APP_SUB_SYSTEM的例子,如图1所示。我们可以清楚地看到,在TOP_SOG界面,有两类交互:APP_SUB_SYSTEM与TOP_SOG& APP_CORE与TOP_SOG可以建模如下:
APP_SUB_SYSTEM - TOP_SOG预算公式:
的 的的
Logic_Distribution_Inside_APP_SUB_SYSTEM
+ Stage_Margin_APP_SUB_SYSTEM
+ Stage_Margin_TOP_SOG
APP_CORE - TOP_SOG预算公式:
Logic_Distribution_Inside_APP_CORE
+ Stage_Margin_APP_CORE
+ Stage_Margin_APP_SUB_SYSTEM
+ Logic_Distribution_Inside_APP_SUB_SYSTEM
+ Stage_Margin_TOP_SOG
上面的等式只是建议在为子预算建模时在多级分区设计中,必须考虑所有中间分区的阶段余量和逻辑分布(即路径开始和结束分区除外)。如果预算是从最高层开始的,那么这个预算也必须合理地分成相似的部分,以便正确实施和时间关闭。例如,让我们假设顶部给出了一个10ns的裕度(时钟周期的50%)到APP_CORE的IN2REG路径,时钟为20ns。现在,假设80%的逻辑位于APP_CORE内,而剩余的20%位于APP_SUB_SYSTEM内作为直通路径,这意味着在任何阶段APP_SUB_SYSTEM内的预算不应超过2ns,对于APP_CORE,它应限制在8ns。除此之外,还必须在此限制内对单个块阶段余量进行建模。
因此,设计人员必须将此路径建模为:
APP_CORE的I/P最大延迟= 20 - (0.8 * 10)= 12ns
I/P_port_budget + APP_CORE_stage_margin= 12ns
对于APP_SUB_SYSTEM的I/P到O/P最大延迟= 0.2 * 10 = 2ns
I/P_to_O/P_port_budget + APP_SUB_SYSTEM_margin= 2ns
虽然上述计算看起来相当简单,但问题在设计成熟,逻辑分布以及阶段边距发生变化时开始。因此,在多分区方案中,每个后续分区的数量变量将增加至少2,这通常会迫使设计人员进行多次迭代以使这些预算成熟,以实现正确的收敛时序收敛。
II。分区边界内外的不常见路径:
除逻辑分布外,不常见的时钟路径是另一个噩梦,在分层关闭的情况下困扰设计者。虽然不常见的路径不确定性的建模是与预算分布类似的类型的挑战,但是更加有害的方面来自与不常见路径相关联的不匹配的形式。不常见路径的一些常见后果是:
CPPR或CPPR降级的变化。
输入延迟的变化以及I/O建模
接口保持违规的大幅增加
由于时间窗口的变化引起的噪声变化
解决此类不匹配的唯一方法是减少跨越分区的不常见路径,并尝试对其进行建模,同时考虑与之相关的所有类型的不确定性。但是,随着分区级别的增加,不常见路径的建模和减少都会成为设计人员面临的主要挑战。在大多数情况下,由于非常见路径的余量通常有点悲观,因此当我们达到最低级别的分区时,通过每个分区级别关联的次要悲观倾向于累积到主要块中。
图2显示了一个典型示例,其中可以轻松地看到跨分区层次结构的不常见路径的变化。对于顶级分区TOP_SOG,非常见路径在Z之后立即开始,其中进一步进入APP_SUB_SYSTEM的层次结构,APP_CORE分别为Y和X.这意味着与TOP_SOG相比,在APP_CORE上应用时钟降额的影响要小得多,因此导致时序不匹配,这可能导致跨接口的保持违规大幅增加,并且由于APP_CORE与APP_SUB_SYSTEM不匹配而产生噪声变化。本身与TOP_SOG不匹配。
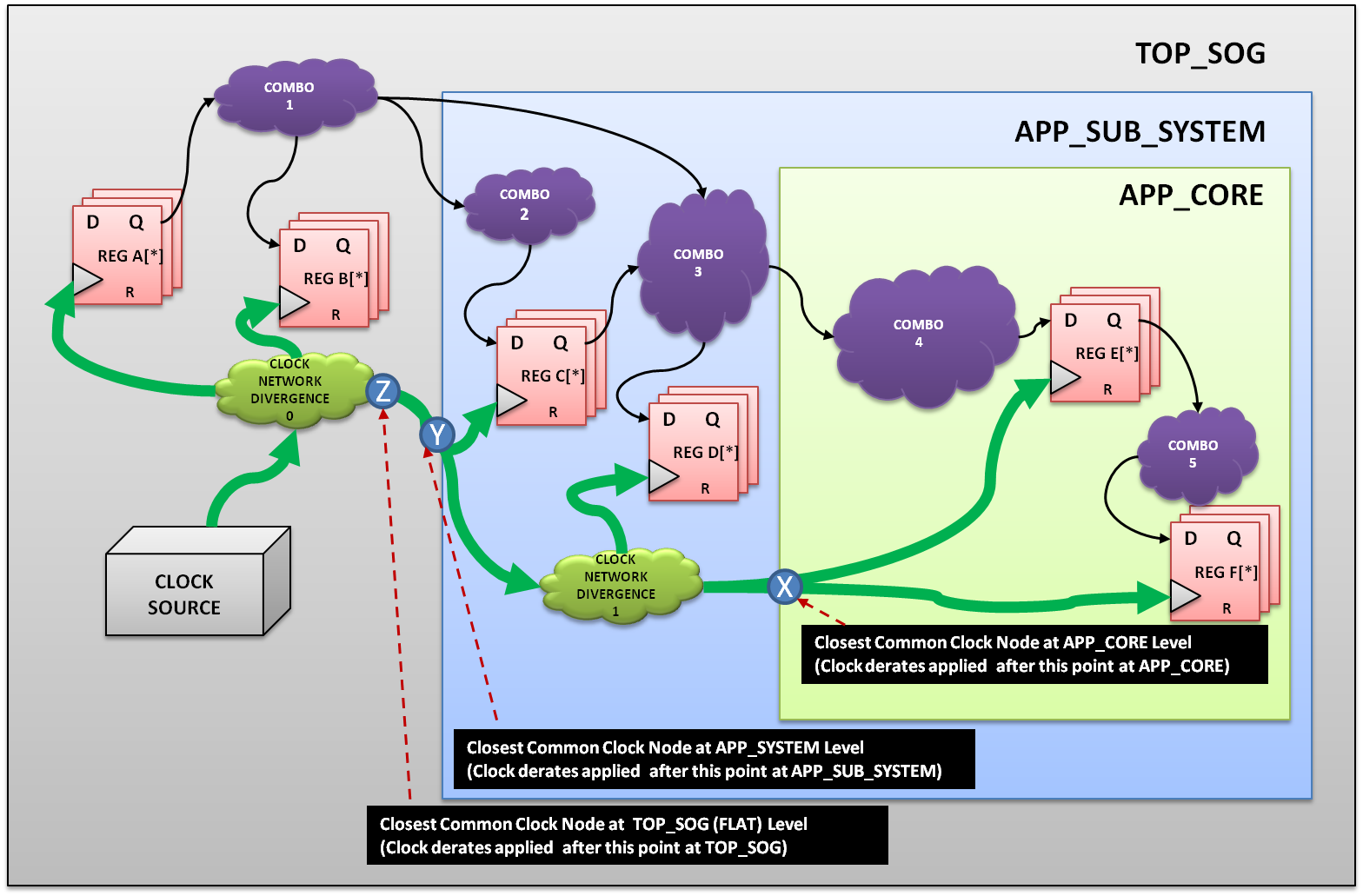
图2:多级分层设计中不常见和常见路径的影响。
iii。常见路径不匹配:
之前我们讨论了多级分区设计中不常见路径的不利影响,但是与外部接口相关的公共路径也同样关注,特别是在噪音分析的情况下。公共路径延迟的简单改变可以在正常分析中传递小的CPPR调整,然而,这种延迟的改变可能在早先没有贡献的时序窗口中产生重叠;因此,降低噪声分布并在甚至REG2REG内部路径中产生违规,这些路径早先遇到噪声。引入更多级别的分区进一步增加了这种不匹配的可能性,因此即使在噪声之后也会对块级设计闭合的质量产生怀疑。
考虑REG_REG路径跨越REG E和REG F在APP_CORE中如图所示图2.这是APP_CORE的完全内部路径,但是由于公共路径本身(直到X)的变化,从TOP_SOG和APP_SUB_SYSTEM级别看时钟边缘到达时延迟的变化会产生完全不同的时序窗口重叠,如图所示虽然这些路径可以通过过度优化来修复,以模拟这种不匹配,但仍然在设计执行期间,人们永远无法确定公共路径是否保持不变。
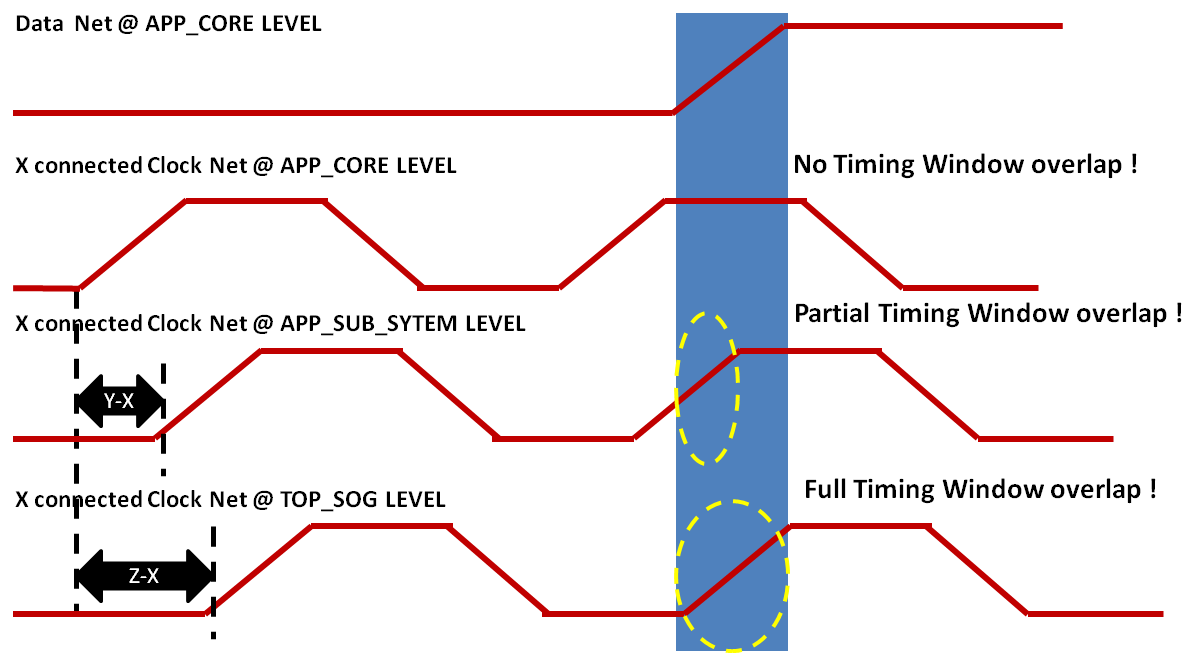
图3:共用路径对多级分层设计中SI(噪声)时序窗口的影响。
b)物理限制:
在多级分区中作为物理分区的数量增加,因为物理限制导致放置问题。物理限制通常反映在有限的端口/引脚/宏放置或建模中。以下是在处理物理挑战时应考虑的一些关键点:
i。块和子块的所有相同端口应放置在附近,它们之间的布局逻辑最小。这些端口通常用于为TOP和子块提供连接,因此应使用最小缓冲区并且应非常小心地处理放置。循环路径中涉及的端口,宏和逻辑的放置,即in2reg,然后是reg2out,反之亦然,应该通过考虑时间以及DRV和DRC的合理余量来驱动,因为这些很可能是瓶颈。后期设计阶段。
iii。子块可能存在一些时序模型问题。例如,当使用典型的物理实现EDA工具(如Cadence EDI)时,我们通常会为子块指定接口逻辑模型(ILM)。使用ILM时,有一些端口(复位,扫描启用等),由于其大小限制,其相关逻辑未被转储到ILM内部(复位转到所有触发器,因此如果在ILM中保留复位逻辑,则ILM压缩将为低)。这导致在相同端口之间留下未优化的逻辑,因为它在EDI端不可见,如图4所示。为解决此类情况,可以使用以下一些替代方案:
在较高层次分区内的此类端口之间设置最大延迟,其预算取决于它们的定时时钟。在多个时钟的情况下,我们需要给它们最坏的情况预算,以便信号可以从块端口到达子块。
如果有少数端口正在通话并且它们之间具有未优化的逻辑,我们可以手动更改该逻辑,以便它们花费最少的时间并将它们设置为在实现端不接触。然而,这种方法并不是一个明确的长期解决方案,因为在每次优化之后生成手动定时ECO可能会变得很麻烦。
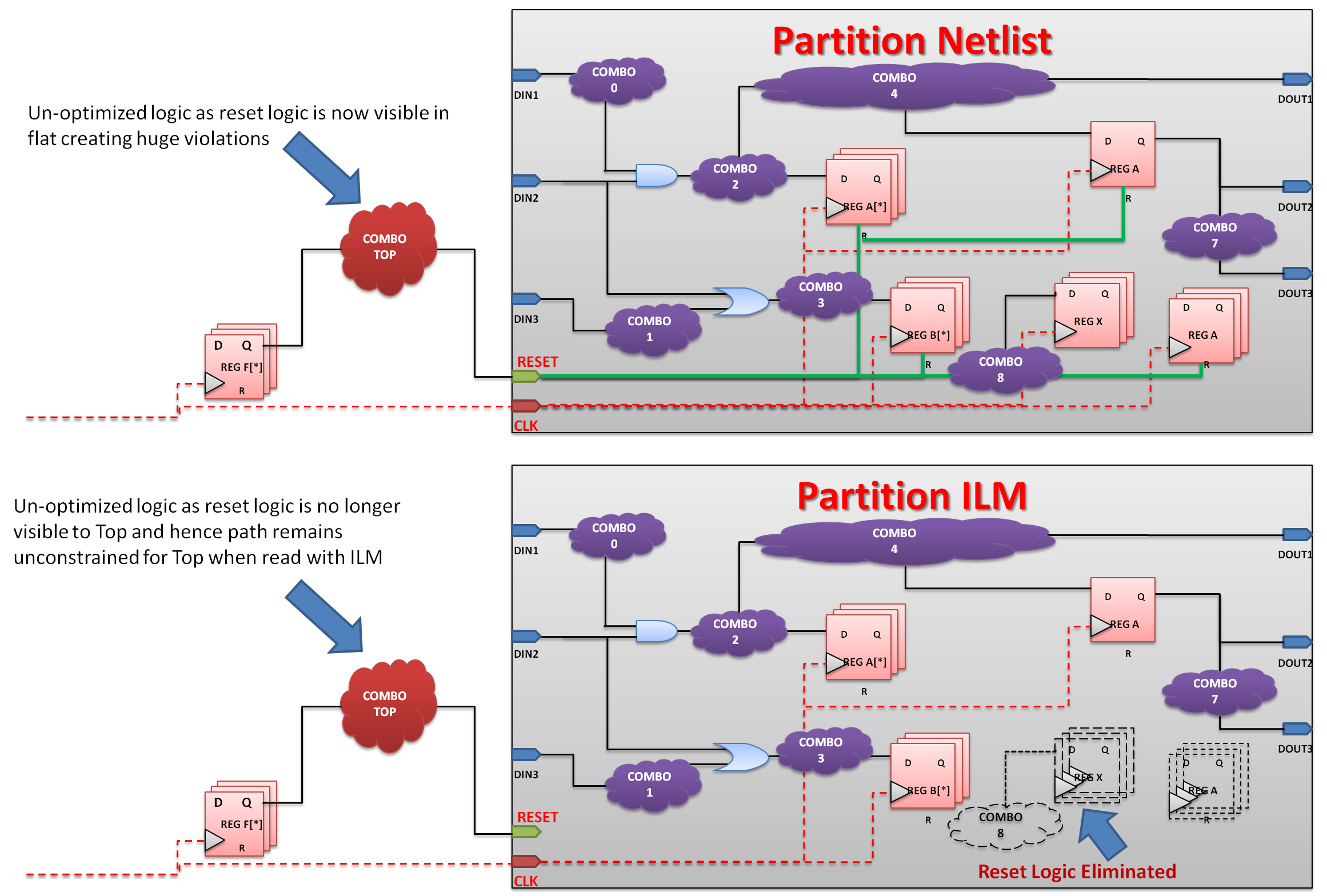
图4:基于ILM建模的未优化复位路径。
c)亚优化优化&复制问题:
次优优化是分层设计的主要实现相关限制。随着硬分区数量的增加,对边界和接口逻辑的优化也会增加。当大量使用这种分区的复制块时,这成为一个更令人担忧的问题。考虑图1中的 dual_core_top 模块。与内部逻辑定时相比,两个复制内核中的接口逻辑仍然没有那么优化。
因此,如果用户要离开示波器25mW泄漏减少,对于单个核心似乎是一个小问题,但是将其乘以复制品的数量,在图1的设计中,用户现在错过了相当于4 * 25 = 100mW的泄漏减少平面设计。此外,对于复制的分区,设计人员主要有两个选项,要么针对最坏情况优化块,要么针对常见场景对其进行优化。对于前者,设计师很可能最终不会优化设计,而对于后者,设计师可能最终会遇到可能无法轻易解决的问题。
例如,假设a公共存储器数据总线到达四核顶部分区的4个核心,如图5所示。现在由于物理位置,核心4的时钟延迟和总线数据偏差可能比core1高200-250ps。现在对于略微满足的路径,这可能会导致最佳角落中最近的core1的额外保持违规,而core4中的设置违规在最坏的角落中最远,而在core2和core3处不会出现此类违规。因此,如果设计者选择修复这些违规,尽管没有核心具有相同的设置以及关键路径,但是由于复制和物理放置,这种情况仍然可能存在。
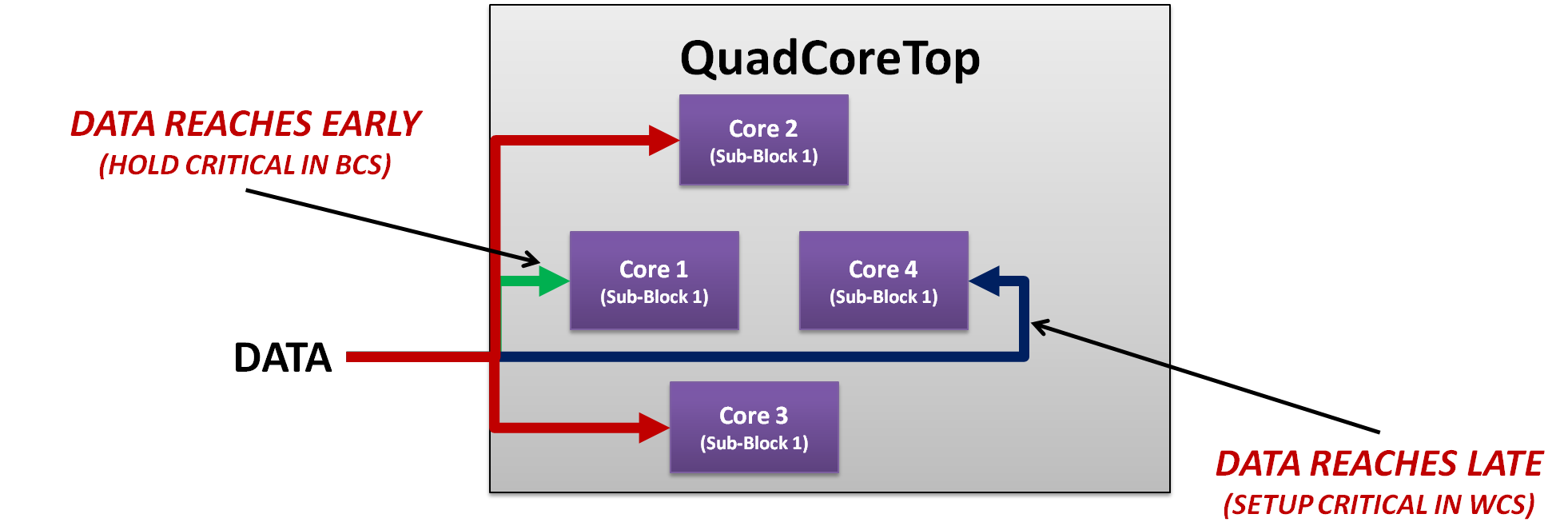
图5:复制在四核类似块内的多级分层分区中的影响。
-
PCB打样
+关注
关注
17文章
2968浏览量
21710 -
华强PCB
+关注
关注
8文章
1831浏览量
27762 -
华强pcb线路板打样
+关注
关注
5文章
14629浏览量
43051
发布评论请先 登录
相关推荐
关于功能验证、时序验证、形式验证、时序建模的论文
FPGA学习指南合集:Verilog HDL那些事儿(建模篇,时序篇,整合篇)
多片段时序数据建模预测实践资料分享
一种分层递阶机制的实时多层建模方法
基于Linux 的两种分层存储实现方案
RP Fiber Power中的多级放大器建模方案解析

在MATLAB/simulink中建模时的两种不同实现方式
MATLAB/simulink中两种实现建模方式的优势
低功耗系统在降低功耗的同时保持精度所涉及的时序因素和解决方案






 工商网监
工商网监
评论