 简要分析AI芯片的性能分析和应用介绍
简要分析AI芯片的性能分析和应用介绍
各大半导体厂商纷纷发布了人工智能相关产品。九月初,先是华为的麒麟970集成了寒武纪的人工智能加速器IP。之后,苹果在其发布会上展示了新一代的A11 Bionic SoC,其中集成了neural engine加速器。Imagination也不甘落后,在苹果之后也发布了PowerVR NNA神经网络处理器IP。九月底,Nvidia的开源深度学习加速器(DLA)正式上线,几乎与之同时,Intel也公布了Loihi芯片。本文将盘点以上几款产品,分析异同。
华为、苹果、Imagination:面向手机的成熟产品发布,移动端AI时代的敲门砖
2016年初,以Eyeriss为代表的深度学习加速器芯片乘着人工智能兴起的东风纷纷破土而出。目前基于深度学习的人工智能算法需要很大的计算量,而传统CPU芯片上用于计算的ALU数目并不多,性能不足以支持深度学习算法的流畅执行。
另外,GPU虽然在云端服务器获得大规模应用,但是一方面GPU架构的功耗太大,无法在移动端广泛使用;另一方面GPU最适合的是深度学习训练,在深度学习的推理应用中因为GPU基于batch运算的模式导致延迟过大,也不适合在移动端使用。
深度学习加速器目前主打的是性能和能效比,其性能能帮助深度学习的推理流畅执行,而其能效比则保证了算法加速过程中不会消耗太多电池,可以在移动端长时间使用。目前在移动领域,智能摄像头、无人机、手机等都是深度学习加速器潜在的应用领域,其中以手机的应用市场最大。
关于深度学习加速器的用法,一般分为芯片和IP两种。芯片的代表如Movidius的Myriad系列(以及基于Myriad芯片的neural stick产品)和,用户可以把芯片集成到自己的系统中来做深度学习加速。然而,在BOM可谓寸土寸金的手机领域,额外加一块芯片加速深度学习几乎不可能,可行的做法是在手机SoC里面集成一块深度学习加速器IP,在手机执行深度学习应用的时候可以把计算放到加速器模块去执行。

华为、苹果和Imagination纷纷发布人工智能加速IP
华为、苹果和Imagination发布的深度学习加速器产品都是这样的IP模块。这些模块经过长期设计和验证,已经非常成熟,可以进入大规模生产阶段。产品能进入量产阶段意味着之前已经经过了长期的威廉希尔官方网站 积累,正如苹果和华为透露他们的人工智能加速IP至少在两年前就已经立项了,可见这些手机巨头对于人工智能的远见和拿下市场的决心。
目前手机上的人工智能应用应该说还处于非常初期的阶段,硬件和软件属于“先有鸡还是先有蛋”的境况:在没有深度学习加速硬件的情况下开发手机端的人工智能应用,会导致硬件限制执行速度,用户体验不好;
而如果没有手机端的人工智能相关应用,硬件厂商往往就不会想到要去做专门的深度学习加速器。而华为、苹果和Imagination推出的手机端深度学习加速器IP可谓是打破了这个僵局,成为手机端人工智能应用普及的敲门砖。
华为、苹果和Imagination公布的加速器峰值性能分别是1.96 TOPS、0.6 TOPS和4TOPS,而实测的性能麒麟970可以到300 GOPS(执行VGG-16模型),Imagination约750 GOPS(执行GoogleNet模型),苹果的实测数据还没有公布,估计也是在100 GOPS的数量级。这样的数字能够支持基础的深度学习算法:
目前,苹果宣称其A11中的neural engine主要是加速Face ID应用,而华为的展示项目则是实时物体辨识。预期在未来,这些人工智能加速器的应用场景会远远多于这些,同时也促成移动端人工智能应用的井喷式发展。
另一方面,我们也应该看到,100GOPS数量级的算法运行计算量更大的实时物体检测(object detection,从画面中同时定位并识别多个物体)还不够流畅,因此深度学习IP还有不少进步的空间。
Nvidia DLA:为AI生态铺路的前瞻性产品
与华为、苹果等定制深度学习IP模块不同,Nvidia选择了开源其深度学习加速架构DLA。目前,DLA已经在github上发布了其RTL代码可供编译、仿真以及验证,预计在未来Nvidia将进一步公布其C模型等重要设计组件。
Nvidia DLA最主要的部分是计算单元,据悉目前DLA会使用Winograd算法来减小卷积的计算开销,同时也会使用数据压缩威廉希尔官方网站 ,来减少DRAM访问时的数据流量。
Nvidia同时给出了NVDLA构成的两种系统,在比较复杂的大系统中, DLA的接口包括与处理器交互的IRQ/CSB,与片外DRAM交互的DBBIF,以及与SRAM交互的SRAMIF,而在小系统的例子中,则省去了SRAMIF,因为小系统中的SRAM比较宝贵可能没有可供NVDLA使用的部分。
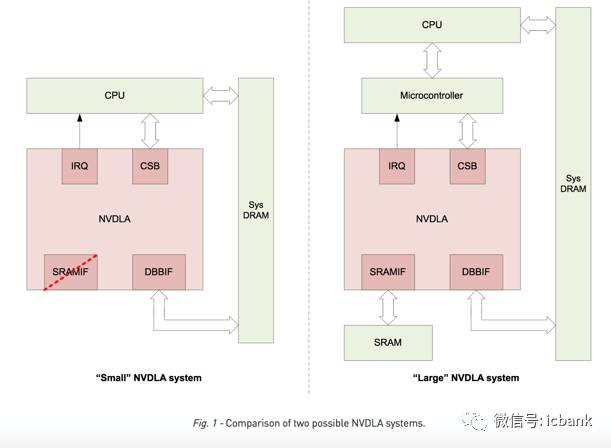
在性能方面,NVDLA在使用2048个MAC的时候可以每秒完成269次ResNet-50推理,相当于2.1TOPS的性能,当然其对于内存的带宽要求也达到了20GB/s,接近DDR4系列的最高带宽。

那么,Nvidia为什么选择了开源的形态呢?通过观察,我们不难发现目前在人工智能硬件领域,Nvidia已经成为云端人工智能加速的主宰者,而在发展潜力巨大的无人车领域,Nvidia也接连推出多款GPU产品布局,在竞争中也处于领跑地位。
在这些Nvidia具有竞争优势的领域,Nvidia的GPU都是作为一种性能强劲的计算加速器存在的。然而,对于产品种类多样而更适合使用SoC产品形态的移动领域,Nvidia一直没有打开局面。
之前Nvidia曾经推出过TK系列和TX系列作为带有深度学习和机器视觉硬件加速特性的SoC来试水移动市场,可惜这些产品的功耗都在10W左右,而且成本很高,导致一直无法占领移动端人工智能加速市场。Nvidia最担心的恐怕就是有一家芯片厂商在移动端人工加速市场脱颖而出,由下至上挑战Nvidia在人工智能加速硬件领域的地位。
因此,Nvidia开源其DLA加速模块,其实是让全球的SoC厂商帮Nvidia一起优化DLA加速模块,并且帮助Nvidia抢占移动端市场。另一方面,开源DLA也能加速移动端人工智能加速硬件的成熟,这样当硬件不再成为瓶颈后,移动端人工智能应用将迎来爆发。而Nvidia作为深度学习模型训练(GPU)以及优化(TensorRT)工具链生态环境的实际掌控者,在移动端人工智能市场真正蓬勃发展后,即使DLA不带来收入也能从人工智能产业链的上游获得大量收益,因此开源DLA的举动是Nvidia布局人工智能生态的重要一步。
Intel Loihi:神经拟态芯片,试验性产品
与前述的几家公司不同,Intel推出的Loihi是一款基于神经拟态(neuromorphic)的芯片。目前最流行的深度学习神经网络中,神经网络把人类的神经系统的统计行为抽象为一系列运算(高维卷积以及非线性运算)的数学系统,与真正的生物神经工作并不相同,而之前介绍的几款产品(以及绝大多数其他人工智能加速器硬件)都是加速这类经典神经网络结构的。
神经拟态则是几乎完全照搬生物神经系统,试图在模型中完全重现生物神经的工作方式(例如引入神经元电势可以充放电,在电势超过一定阈值后神经元就会放出电脉冲到其他相邻的神经元)。理论上,这种神经拟态芯片可以由异步系统实现,并且有很低的功耗。然而,目前神经拟态结构如何训练仍然是学术界没有解决的问题。
Intel发布的Loihi声称可以自我学习,然而学习的效果如何还不得而知。应该说在模型训练问题还没有解决前,神经拟态就基本无法与经典的深度学习在主流人工智能应用里正面竞争,而主要会用在一些实验性的应用,例如利用神经拟态芯片去完成脑科学研究,或者做一些专用场合的高效数据处理(例如三星就使用过IBM的True North神经拟态芯片来实现动态视觉传感器,只有在画面发生变化的时候该传感器才会记录)。而Intel发布的Loihi,也更多是一款试验性质的产品。
为什么大家纷纷推出AI芯片产品?
在一个月中,几家大公司相继发布AI芯片,这首先说明人工智能应用真正获得了市场的认可。如果我们回顾芯片市场,会发现总是先有软件应用出现,该应用在得到认可后快速发展很快遇到硬件瓶颈,于是推动相应硬件的开发,而在硬件瓶颈突破后,该应用又会获得更快速的普及,从而形成一个正循环。目前人工智能正处于该循环的第二步,即硬件限制了人工智能应用的普及,尤其是在移动端的普及,而各大硬件厂商正是看到了人工智能的巨大潜力,于是纷纷开发相关芯片并争相发布。
在未来的移动人工智能市场,由于移动产品的多样性(如要求高性能但是允许高功耗的智能摄像头市场,要求高性能但是同时要求低延迟和低功耗的无人机市场,要求中等性能但是对成本和功耗要求很高的手机市场,以及要求超低功耗但是对于性能要求也不高的物联网市场),预计还是会有多家公司分别占领不同的市场,而不太会出现一家独大通吃所有市场的情况。未来人工智能芯片预计会进入群雄逐鹿的时代。
-
人工智能
+关注
关注
1791文章
47279浏览量
238515 -
深度学习
+关注
关注
73文章
5503浏览量
121170 -
AI芯片
+关注
关注
17文章
1887浏览量
35027
发布评论请先 登录
相关推荐
什么是半导体芯片的失效切片分析?
FIB威廉希尔官方网站 :芯片失效分析的关键工具

云端AI开发环境分析
深蕾半导体HDMI AI分析盒子






 工商网监
工商网监
评论