 电子发烧友App
电子发烧友App


内存解耦合(memory disaggregation)是一种前景广阔的现代数据中心架构,将计算和内存资源分开为独立的资源池,通过超高速网络连接,可提高内存利用率、降低成本,并实现计算和内存资源的弹性扩展。然而,现有基于远程直接内存访问(RDMA)的内存解耦合解决方案存在较高的延迟和额外开销,包括页面错误和代码重构。新兴的缓存一致性互连威廉希尔官方网站 (如CXL)为重构高性能内存解耦合提供了机会。然而,现有基于CXL的方法存在物理距离限制,并且无法跨机架部署。
本文提出了一种基于RDMA和CXL的新型低延迟、高可扩展性的内存解耦合系统Rcmp。其显著特点是通过CXL提高了基于RDMA系统的性能,并利用RDMA克服了CXL的距离限制。为解决RDMA和CXL在粒度、通信和性能方面的不匹配,Rcmp:(1)提供基于全局页面的内存空间管理,实现细粒度数据访问;(2)设计了一种有效的通信机制,避免了通信阻塞问题;(3)提出了一种热页识别和交换策略,减少了RDMA通信;(4)设计了一个RDMA优化的RPC框架,加速了RDMA传输。我们实现了Rcmp的原型,并通过微基准测试和运行带有YCSB基准测试的键值存储来评估其性能。结果显示,Rcmp比基于RDMA的系统的延迟降低了5.2倍,吞吐量提高了3.8倍。我们还证明,Rcmp可以随着节点数量的增加而良好扩展,而不会影响性能。
01. 引言
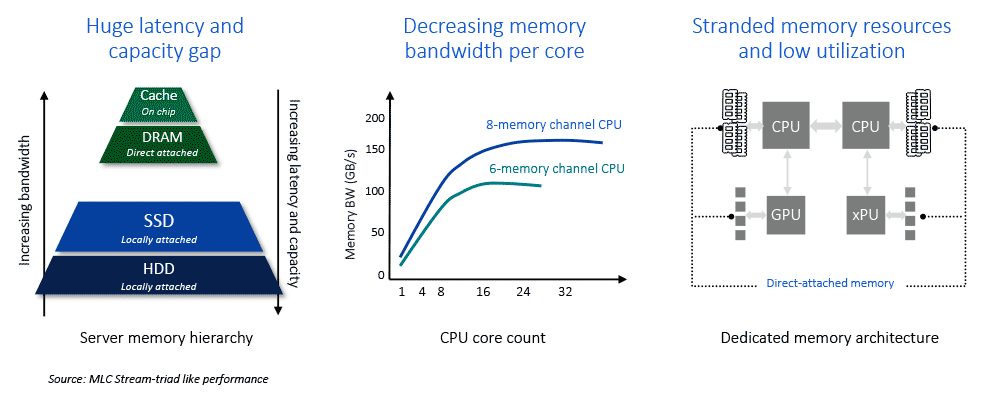
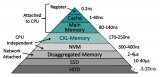
内存解耦合在数据中心(例如,RSA [48],WSC [5]和dReD-Box [27]),云服务器(例如,Pond [30]和Amazon Aurora [53]),内存数据库(例如,PolarDB [11]和LegoBase [65])以及高性能计算(HPC)系统 [37, 55]等领域越来越受青睐,因为它可以提高资源利用率、灵活的硬件可扩展性和降低成本。这种架构(见图1)将计算和内存资源从传统的单体服务器中解耦,形成独立的资源池。计算池包含丰富的CPU资源但最少的内存资源,而内存池包含大量内存但几乎没有计算能力。内存解耦合可以提供全局共享内存池,并允许不同资源独立扩展,为构建成本效益和弹性数据中心提供了机会。
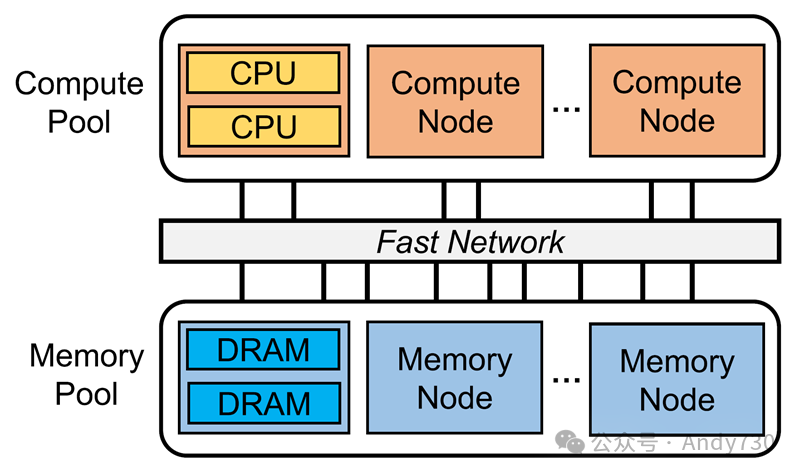
图1. 内存解耦合
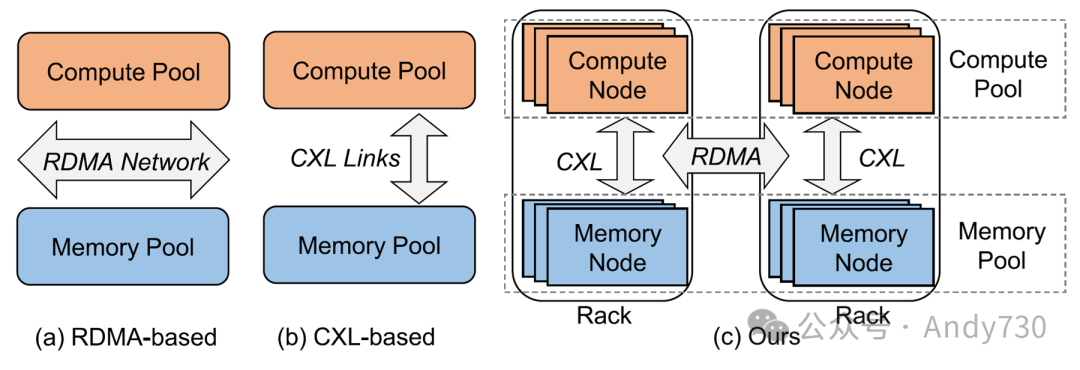
图2. 不同的内存解耦合架构
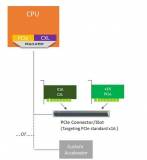
远程直接内存访问(RDMA)网络通常被采用在内存解耦合系统中连接计算和内存池(见图2(a))。然而,现有基于RDMA的内存解耦合解决方案存在显著缺陷。一个是高延迟。当前的RDMA可以支持单位数微秒级别的延迟(1.5∼3 μs)[17, 64],但仍然比DRAM内存延迟(80∼140 ns)相差几个数量级。RDMA通信成为访问内存池的性能瓶颈。另一个是额外的开销。由于内存语义不是原生支持的,RDMA在原系统上产生了侵入性的代码修改和中断开销。具体来说,当前基于RDMA的内存解耦合包括基于页面和基于对象的方法,根据数据交换粒度的不同而不同。然而,基于页面的方法涉及额外的页面错误处理和读/写放大开销 [10, 41],而基于对象的方法则需要定制接口更改和源代码级别的修改,这会牺牲透明度 [17, 56]。
CXL(Compute Express Link)是一种基于PCIe的缓存一致性互连协议,它能够实现对远程内存设备的直接和一致访问,无需CPU干预[45, 52]。CXL原生支持内存语义,并具有类似多插槽NUMA访问延迟(约90∼150 ns [21, 45])的特性,具有克服RDMA缺点、实现低成本、高性能内存解耦合的潜力。近年来,基于CXL的内存解耦合威廉希尔官方网站 在学术界和工业界引起了广泛关注[10, 21, 30, 56]。
重构基于CXL的内存解耦合架构(见图2(b))以取代RDMA是一项有前景的研究,但是CXL威廉希尔官方网站 的不成熟和缺乏工业级产品使其在实践中变得困难。首先,存在物理限制。现有基于CXL的内存解耦合面临着长距离部署的限制,通常仅限于数据中心内部的机架级别,即使对于最新的CXL 3.0规范也是如此[14, 45, 56]。物理距离限制导致无法在机架之间部署内存池,失去了高度可扩展性。其次,成本高昂。用CXL硬件替换数据中心中的所有RDMA硬件的成本非常高昂,特别是对于大规模集群而言。此外,由于缺乏商业化的大规模生产的CXL硬件和支持基础设施,目前对CXL内存的研究依赖于定制的FPGA原型[21, 49]或者使用无CPU NUMA节点进行仿真[30, 32]。
在本文中,我们探讨了一种结合了CXL和RDMA的混合内存解耦合架构,旨在保留并利用RDMA,使CXL能够打破距离约束。在这样的架构中(见图2(c)),在一个机架中建立一个小型基于CXL的内存池,使用RDMA连接机架,形成一个更大的内存池。这种方法利用CXL提高基于RDMA的内存解耦合的性能,并忽略了CXL的物理距离限制。然而,它在实施过程中面临着巨大挑战,包括RDMA和CXL的粒度不匹配、通信不匹配和性能不匹配(第3.3节)。特别是,由于RDMA和CXL之间的延迟差距,机架之间的RDMA通信成为主要的性能瓶颈。一些研究提出了一种基于RDMA驱动的加速框架[61],使用缓存一致性加速器连接到类似CXL的缓存一致性内存,但这种方法需要定制的硬件。
为解决这些问题,我们提出了一种新颖的基于RDMA和CXL的内存解耦合系统Rcmp,提供低延迟和可扩展的内存池服务。如图2(c)所示,Rcmp的显著特点是将基于RDMA的方法(见图2(a))和基于CXL的方法(见图2(b))结合起来,以克服两者的缺点,并最大化CXL的性能优势。Rcmp提出了几个优化设计来解决上述挑战。具体来说,Rcmp具有四个关键特性。首先,Rcmp提供全局内存分配和地址管理,将数据移动大小(缓存行粒度)与内存分配大小(页面粒度)解耦。细粒度数据访问可以避免IO放大 [10, 56]。其次,Rcmp设计了一种高效的机架内和机架间通信机制,以避免通信阻塞问题。第三,Rcmp提出了一种热页识别和交换策略,以及一种CXL内存缓存策略和同步机制,以减少机架间的访问。第四,Rcmp设计了一个高性能的RDMA感知RPC框架,加速机架间的RDMA传输。
我们以6483行C++代码实现了Rcmp作为用户级架构。Rcmp为内存池服务提供了简单的API,易于应用程序使用。此外,Rcmp通过与FUSE [1]集成,提供了简单的高容量内存文件系统接口。我们使用微基准测试评估了Rcmp,并在YCSB工作负载下运行了一个键值存储(哈希表)。评估结果表明,Rcmp在所有工作负载下均实现了高性能和稳定性。具体而言,与基于RDMA的内存解耦合系统相比,Rcmp在微基准测试下将延迟降低了3到8倍,在YCSB工作负载下将吞吐量提高了2到4倍。此外,随着节点或机架数量的增加,Rcmp具有良好的可扩展性。本文中Rcmp的开源代码和实验数据集可在https://github.com/PDS-Lab/Rcmp 上获取。
总之,我们的工作主要贡献如下:
分析了当前内存解耦合系统的缺点,指出基于RDMA的系统存在高延迟、额外开销和通信不佳的问题,而基于CXL的系统受到物理距离限制和缺乏可用产品的影响。
设计并实现了Rcmp,一个新颖的内存池系统,通过结合RDMA和CXL的优势,实现了高性能和可扩展性。据我们所知,这是第一个利用RDMA和CXL威廉希尔官方网站 构建内存解耦合架构的工作。
提出了许多优化设计,以克服将RDMA和CXL结合时遇到的性能挑战,包括全局内存管理、高效的通信机制、热页交换策略和高性能RPC框架。
对Rcmp的性能进行了全面评估,并与最先进的内存解耦合系统进行了比较。结果表明,Rcmp在性能和可扩展性方面明显优于这些系统。
本文的其余部分组织如下。第2和第3节介绍了背景和动机。第4和第5节介绍了Rcmp的设计思想和系统架构细节。第6节展示了全面的评估结果。第7节总结了相关工作。第8节对全文进行了总结。
02. 背景
2.1 内存解耦合 新兴应用程序,如大数据[31, 39],深度学习[4, 28],HPC[37, 55],以及大型语言模型(例如,ChatGpt[7]和GPT-3[19]),在现代数据中心中越来越普遍,这导致了对内存的巨大需求[2, 3, 44, 56]。然而,当今的数据中心主要使用单体服务器架构,其中CPU和内存紧密耦合,面临着日益增长的内存需求带来的重大挑战: 低内存利用率:在单体服务器中,由于单个实例占用的内存资源无法跨服务器边界分配,很难充分利用内存资源。表1显示,典型数据中心、云平台和HPC系统的内存利用率通常低于50%。此外,实际应用程序经常请求大量内存,但实际上内存并未充分利用。例如,在Microsoft Azure和Google的集群中[30, 33, 56],分配的内存约有30%到61%长时间处于空闲状态。
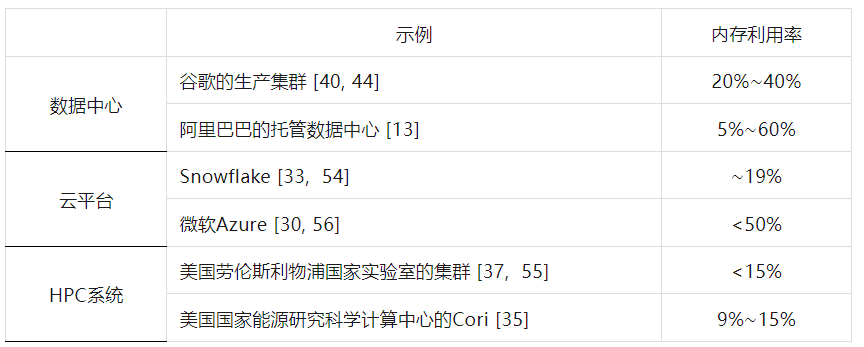
表1. 典型系统中的内存利用率 弹性不足:在单体服务器中安装内存或CPU资源后,很难对其进行缩小/扩大。因此,服务器配置必须事先规划,并且动态调整通常会导致现有服务器硬件的浪费[44, 65]。此外,由于固定的CPU到内存比率,很难将单个服务器的内存容量灵活地扩展到所需大小[44, 56]。
成本高昂:大量未使用的内存资源导致运营成本高和能源浪费[11, 65]。此外,现代数据中心设备故障频繁,几乎每天都会发生[13, 40, 58]。采用单体架构时,当服务器内的任何一个硬件组件发生故障时,通常整个服务器无法使用。这种粗粒度的故障管理导致了高昂的成本[44]。 为应对这些问题,提出了内存解耦合的方案,并在学术界和工业界引起了广泛关注[3, 17, 21, 43, 51, 56, 63, 66]。内存解耦合将数据中心中的内存资源与计算资源分离开来,形成通过快速网络连接的独立资源池。这使得不同资源可以独立管理和扩展,实现了更高的内存利用率、弹性扩展和降低成本。 如图1所示,在这样的架构中,计算池中的计算节点(CNs)包含大量的CPU核心和少量的本地DRAM,而内存池中的内存节点(MNs)则托管大容量内存,几乎没有计算能力。微秒级延迟网络(例如,RDMA)或缓存一致性互连协议(例如,CXL)通常是从CNs到MNs的物理传输方式。
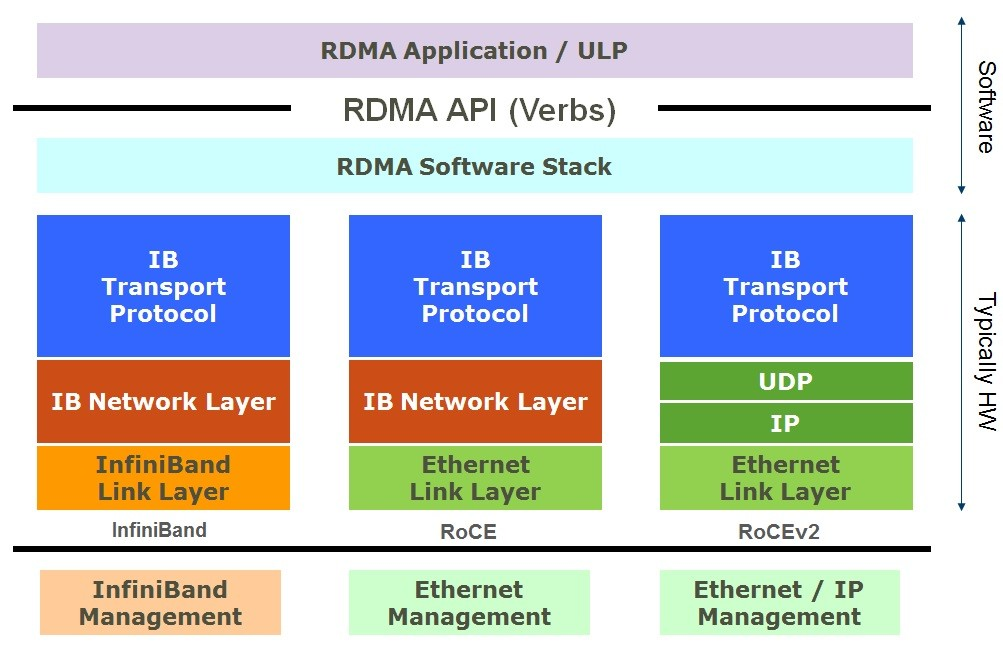
2.2 RDMA威廉希尔官方网站 RDMA是一系列允许一台计算机直接访问网络中其它计算机数据的协议。RDMA协议通常直接固化在RDMA网卡(RNIC)上,并且具有高带宽(>10 GB/s)和微秒级低延迟(∼2 μs),被InfiniBand、RoCE、OmniPath等广泛支持 [20, 47, 62]。RDMA提供基于两种操作原语的数据传输服务:单边操作包括RDMA READ、WRITE、ATOMIC(例如,FAA、CAS),双边操作包括RDMA SEND、RECV。RDMA通信是通过一个消息队列模型实现的,称为队列对(QP)和完成队列(CQ)。QP包括发送队列(SQ)和接收队列(RQ)。发送方将请求提交到SQ(单边或双边操作),而RQ用于在双边操作中排队RDMA RECV请求。CQ与指定的QP关联。同一SQ中的请求按顺序执行。通过使用门铃批处理(doorbell batching) [47, 64],多个RDMA操作可以合并为单个请求。然后,这些请求由RNIC读取,RNIC异步地从远程内存中写入或读取数据。当发送方的请求完成时,RNIC将完成条目写入CQ,以便发送方可以通过轮询CQ来知道完成情况。
2.3 CXL协议 CXL是一种基于PCIe的开放行业标准,用于处理器、加速器和内存之间的高速通信,采用Load/Store语义以缓存一致的方式进行。CXL包含三种独立的协议,包括CXL.io、CXL.cache和CXL.mem。其中,CXL.mem允许CPU通过PCIe总线(FlexBus)直接访问底层内存,而无需涉及页面错误或DMA。因此,CXL可以在相同的物理地址空间中提供字节可寻址的内存(CXL内存),并允许透明内存分配。使用PCIe 5.0,CPU到CXL互连带宽将类似于NUMA体系结构中的跨NUMA互连。从软件的角度来看,CXL内存可以被视为一个无CPU的NUMA节点,访问延迟也与NUMA访问延迟相似(约为90∼150 ns [21, 45])。甚至CXL 3.0规范 [45] 报告称,CXL.mem的访问延迟接近于普通DRAM(约为40-ns读延迟和80-ns写延迟)。然而,大多数论文中使用的当前CXL原型的访问延迟明显更高,约为170到250 ns [30, 32, 49]。
03. 现有内存解耦合架构及其局限性
3.1 基于RDMA的方法
基于RDMA的内存解耦合可大致分为两种方式:基于页面(page based)和基于对象(object based)。基于页面的方法(如Infiniswap [22],LegoOS [44],Fastswap [3])使用虚拟内存机制将内存池中的远程页面缓存在本地DRAM中。它通过触发页面故障和交换本地内存页面和远程页面来实现对远程内存池的访问。优点在于其简单易用,并对应用程序透明。基于对象的方法(如FaRM [17],FaRMV2 [43],AIFM [41],Gengar [18])通过定制的对象语义(如键值接口)实现细粒度的内存管理。单边操作使得计算节点可以直接访问内存节点,而无需涉及远程CPU,这更适合于内存解耦合,因为内存节点几乎没有计算能力。然而,如果在内存解耦合系统中仅使用单边RDMA原语进行通信,单个数据查询可能涉及多次读写操作,导致延迟较高 [25, 26]。因此,许多研究提出了基于RDMA的高性能RPC框架(如FaSST [26],FaRM [17])或采用不涉及RDMA原语的通用RPC库 [24]。
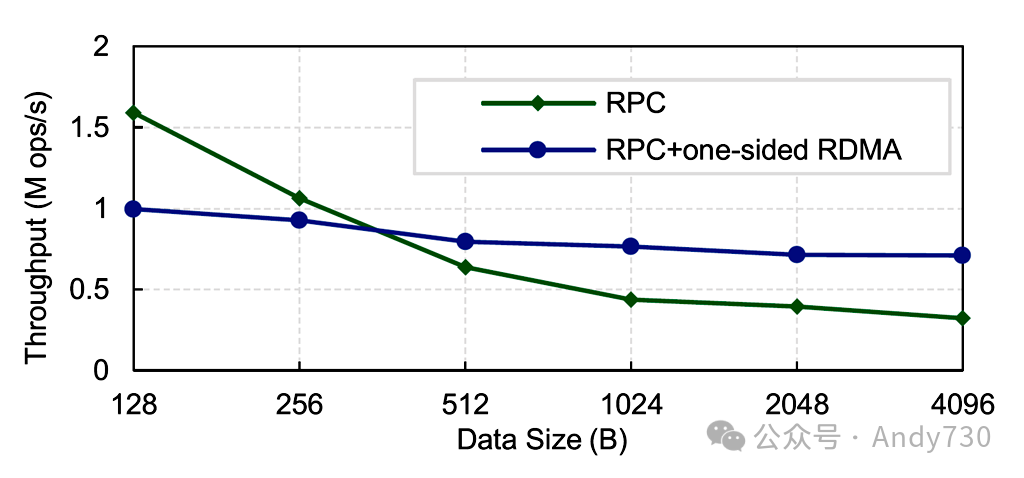
图3. 通信测试

表2. 延迟比较 基于RDMA的方法存在以下缺点。
问题1:高延迟。RDMA通信和内存访问之间存在较大的延迟差异,超过20倍。这使得RDMA网络成为基于RDMA的内存解耦合系统的主要性能瓶颈。
问题2:高开销。基于页面的方法由于页面故障开销而性能下降。例如,Fastswap [3]具有较高的远程访问延迟。此外,对于细粒度访问,会发生读/写放大,因为数据始终以页面粒度传输。基于对象的方法可以避免页面故障开销,但需要进行侵入式的代码修改,并且根据应用程序的语义而变化,导致复杂性更高。
问题3:通信不佳。现有的RDMA通信方法未充分利用RDMA带宽。我们使用主流通信框架(包括(1)仅RPC(使用eRPC [24]),以及(2)单边RDMA和RPC混合模式[17, 26])测试了不同数据大小的吞吐量。结果表明,RPC通信适用于小数据传输,而混合模式在大数据场景下具有更高的吞吐量。512字节是一个分界点,这启发我们设计动态策略。总之,基于RDMA的解决方案总结如表3所示。
3.2 基于CXL的方法 许多研究提出了使用CXL的内存解耦合架构,以克服基于RDMA的方法的缺点,并实现更低的访问延迟。基于CXL的内存解耦合可以提供共享的缓存一致性内存池,并支持缓存行粒度访问,而无需进行侵入性更改。总的来说,基于CXL的方法相对于基于RDMA的方法具有以下优势:
较少的软件开销:CXL在主机处理器(CPU)和任何连接的CXL设备上的内存之间维护统一的一致性内存空间。基于CXL的方法减少了软件堆栈的复杂性,避免了页面故障开销。
细粒度访问:CXL支持CPU、GPU和其它处理器通过原生Load/Store指令访问内存池。基于CXL的方法允许缓存行粒度访问,避免了基于RDMA的方法的读/写放大问题。
低延迟:CXL提供接近内存的延迟,基于CXL的方法缓解了网络瓶颈和内存过度配置的问题。
弹性:基于CXL的方法具有出色的可扩展性,因为可以连接更多的PCIe设备,而不像用于DRAM的DIMM(双列直插式内存模块)那样受限。 然而,基于CXL的方法也存在以下缺点。
问题1:物理距离限制。由于PCIe总线长度有限,基于CXL的方法在机架级别内受限(现有的CXL产品最大距离为2米),无法直接应用于大规模数据中心。可以使用PCIe灵活延长网线,但仍存在最大长度限制。一个正在进行的研究工作是将PCIe 5.0电信号转换为光信号,目前仍处于测试阶段,需要专门的硬件。这种方法也存在潜在的开销,包括信号损失、功耗、部署成本等。在3到4米的距离上,仅光传输时间就超过了现代内存的首字节访问延迟。因此,如果基于CXL的内存解耦合超出机架边界,将会对延迟敏感的应用程序产生明显影响。
问题2:高成本。当前CXL产品尚未成熟,大多数研究仍处于仿真阶段,包括基于FPGA的原型和使用NUMA节点的interwetten与威廉的赔率体系 。早期使用FPGA的CXL产品尚未针对延迟进行优化,并且报告的延迟较高。因此,NUMA基础的模拟仍然是CXL概念验证的更流行方法。此外,当前CXL产品的昂贵价格使得将数据中心中的所有RDMA硬件替换为CXL硬件变得不切实际。
3.3 混合方法和挑战 一种可能的解决方案是利用网络来克服CXL的机架距离限制。最先进的案例是CXL-over-Ethernet。它将计算和内存池部署在不同的机架中,并在计算池中使用CXL提供全局一致内存抽象,因此CPU可以通过Load/Store语义直接访问分离的内存。然后,采用以太网来传输CXL内存访问请求到内存池。这种方法可以支持缓存行访问粒度,但每个远程访问仍然需要网络,并且无法利用CXL的低延迟。正在进行的优化是在CXL内存中仔细设计缓存策略。表3显示了现有内存解耦合方法的比较,它们都有优点和局限性。
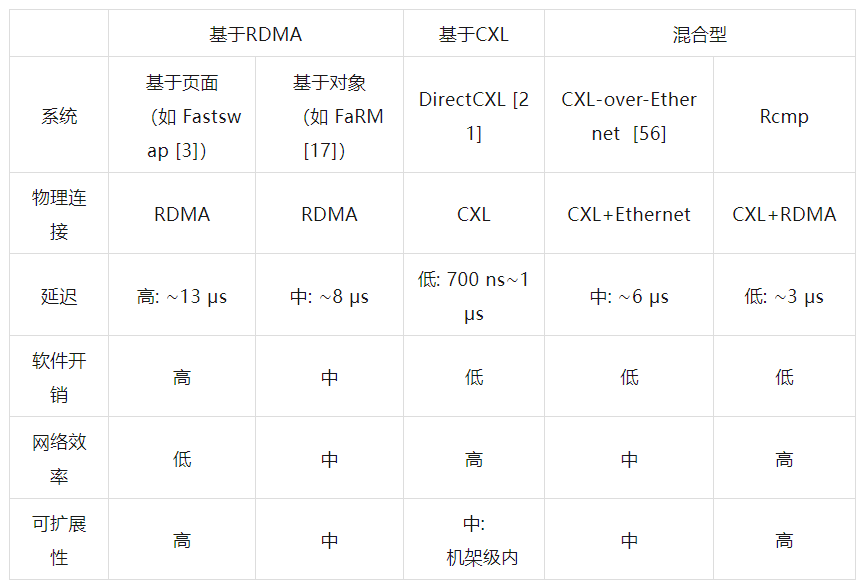
表3. 内存解耦合方法比较
正如许多研究人员认为的那样,CXL和RDMA是互补的威廉希尔官方网站 ,将两者结合起来是有前途的研究。在本文中,我们通过结合基于CXL和基于RDMA的方法(即,在机架内通过CXL构建小型内存池,并通过RDMA连接这些小型内存池)来探索一种新的混合架构。这种对称架构允许在每个小型内存池中充分利用CXL的优势,并通过RDMA提高可扩展性。然而,这种混合架构面临以下挑战。
挑战1:粒度不匹配。基于CXL的方法支持以缓存行为访问粒度的缓存一致性。基于RDMA的方法的访问粒度是页面或对象,比缓存行粒度大得多。需要为混合架构重新设计内存管理和访问机制。
挑战2:通信不匹配。RDMA通信依赖于RNIC和消息队列,而CXL基于高速链路和缓存一致性协议。需要实现统一和高效的抽象,以用于机架内和机架间的通信。
挑战3:性能不匹配。RDMA的延迟远远大于CXL(超过10倍)。性能不匹配将导致非统一的访问模式(类似于NUMA架构)——即,访问本地机架内存(本地机架访问)比访问远程机架内存(远程机架访问)要快得多。
04. 设计思路
为了解决这些挑战,我们提出了 Rcmp,一种新型的混合内存池系统,采用 RDMA 和 CXL。如表3所示,Rcmp 实现了更好的性能和可扩展性。主要的设计权衡和思路如下所述。
4.1 全局内存管理 Rcmp 通过基于页面的方法实现全局内存管理,原因有两点。首先,页面管理方法易于采用,并对所有用户应用程序透明。其次,基于页面的方法更适合 CXL 的字节访问特性,而对象基方法则带来额外的索引开销。每个页面被划分为许多 slab 以进行细粒度管理。此外,Rcmp 为内存池提供全局地址管理,并最初使用集中式元数据服务器(MS)来管理内存地址的分配和映射。 Rcmp 以缓存行粒度访问和移动数据,与内存页面大小解耦。由于 CXL 支持内存语义,Rcmp 可以自然地在机架内以缓存行粒度进行访问。对于远程机架访问,Rcmp 避免了性能下降,采用直接访问模式(Direct-I/O)而不是由页面错误触发的页面交换。
4.2 高效通信机制 如图4所示,混合架构有三种远程机架通信的可选方法。在方法(a)中,每个计算节点通过自己的 RNIC 访问远程机架中的内存池。这种方法有明显的缺点。首先是高昂的成本,由于过多的 RNIC 设备;其次,每个计算节点都有 CXL 链接和 RDMA 接口,导致高一致性维护开销;第三,与有限的 RNIC 内存存在高竞争,导致频繁的缓存失效和更高的通信延迟。在方法(b)中,每个机架上都使用一个守护进程服务器(配备有 RNIC)来管理对远程机架的访问请求。守护进程服务器可以降低成本和一致性开销,但是单个守护进程(带有一个 RNIC)将导致有限的 RDMA 带宽。在方法(c)中,使用哈希将计算节点分组,每个组对应一个守护进程,以避免单个守护进程成为性能瓶颈。所有守护进程都建立在相同的 CXL 内存上,易于保证一致性。Rcmp 支持后两种方法,方法(b)在小规模节点下默认采用。

图4. 机架间通信方法
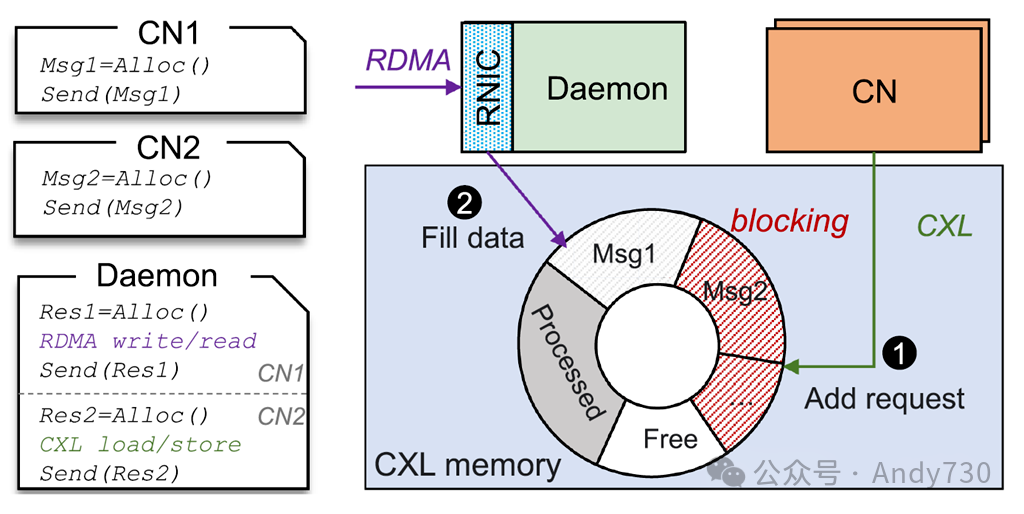
图5. 通信阻塞 与最新的内存解耦合解决方案一样,Rcmp 使用无锁环形缓冲区实现高效的机架内和机架间通信。
机架内通信。引入守护进程后,计算节点需要首先与守护进程通信,确定数据存储位置。简单的解决方案是在 CXL 内存中维护一个环形缓冲区,以管理计算节点与守护进程之间的通信,这可能会导致混合架构中的消息阻塞。如图5所示,计算节点将访问请求添加到环形缓冲区并等待守护进程轮询。在此示例中,CN1 首先发送 Msg1,然后 CN2 发送 Msg2。当数据填满时,当前消息(Msg1)完成,下一个消息(Msg2)将被处理。如果 Msg1 是一个远程机架访问请求,而 Msg2 是一个本地机架访问请求,那么由于 RDMA 和 CXL 之间的性能差距,可能会先填满 Msg2。由于每条消息的长度可变,守护进程无法获取 Msg2 的头指针以跳过 Msg1 并首先处理 Msg2。Msg2 必须等待 Msg1 完成,导致消息阻塞。为避免通信阻塞,Rcmp 将本地和远程机架访问解耦,并使用不同的环形缓冲区结构,其中远程机架访问采用双层环形缓冲区。
机架间通信。不同机架中的守护进程服务器通过具有单边 RDMA 写入/读取的环形缓冲区进行通信。
4.3 远程机架访问优化 由于非均匀访问特性,远程机架访问将是混合架构的主要性能瓶颈。此外,由于直接I/O模型,对于任何粒度的远程机架数据访问,都需要一次RDMA通信,导致高延迟,特别是对于频繁的小数据访问。Rcmp通过两种方式优化了这个问题:减少和加速远程机架访问。
减少远程机架访问。在真实数据中心中,访问分布不均和热点问题广泛存在。因此,Rcmp提出了一种基于页面的热度识别和用户级热页面交换方案,将频繁访问的页面(热页面)迁移到本地机架,以减少远程机架访问。 为了进一步利用时间和空间局部性,Rcmp将远程机架的细粒度访问缓存在CXL内存中,并将写请求批处理到远程机架。
加速RDMA通信。Rcmp提出了一种高性能的RDMA RPC(RRPC)框架,采用混合传输模式和其它优化措施(例如,门铃批处理),充分利用RDMA网络的高带宽。
05. RCMP系统
在本章中,我们详细描述了Rcmp系统和优化策略。
5.1系统概述
Rcmp系统概述如图6所示。Rcmp以机架为单位管理集群。机架内所有 CN 和 MN 通过 CXL 链接相互连接,形成一个小的 CXL 内存池。不同的机架通过 RDMA 连接起来,形成一个更大的内存池。与基于 RDMA 的系统相比,Rcmp 可以实现更好的性能,与基于 CXL 的系统相比,具有更高的可扩展性。MS 用于全局地址分配和元数据维护。在一个机架中,所有 CN 共享统一的 CXL 内存。CN Lib 提供内存池的 API。Daemon 服务器是机架的中央控制节点。它负责处理访问请求,包括 CXL 请求(CXL 代理)和 RDMA 请求(消息管理器),交换热页(交换管理器),管理 slab 分配器,并维护 CXL 内存空间(资源管理器)。Daemon 运行在每个机架内的服务器上,与 CN 相同。此外,Rcmp 是一个用户级架构,避免了内核和用户空间之间的上下文切换开销。
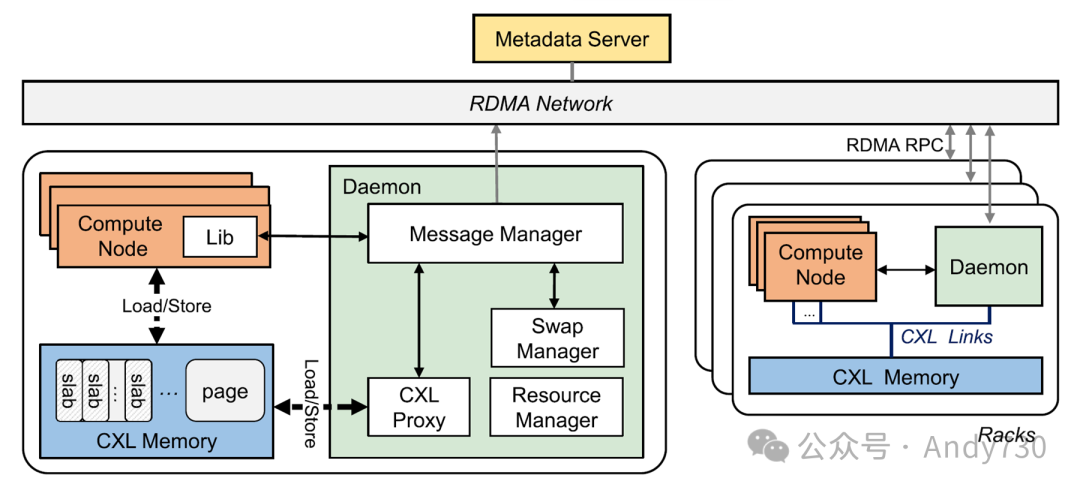
图6. Rcmp系统概述
全局内存管理。Rcmp 提供全局内存地址管理,如图7(a)所示。MS 以粗粒度页面进行内存分配。全局地址 GAddr(page_id,page_offset)由 MS 分配的页面 ID 和 CXL 内存中的页面偏移组成。Rcmp 使用两个哈希表来存储地址映射。具体来说,页面目录(在 MS 中)记录了页面 ID 到机架的映射,页面表(在 Daemon 中)记录了页面 ID 到 CXL 内存的映射。此外,为了支持细粒度数据访问,Rcmp 使用 slab 分配器(一种对象缓存内核内存分配器)来处理细粒度内存分配。页面是2的幂的 slab 集合。
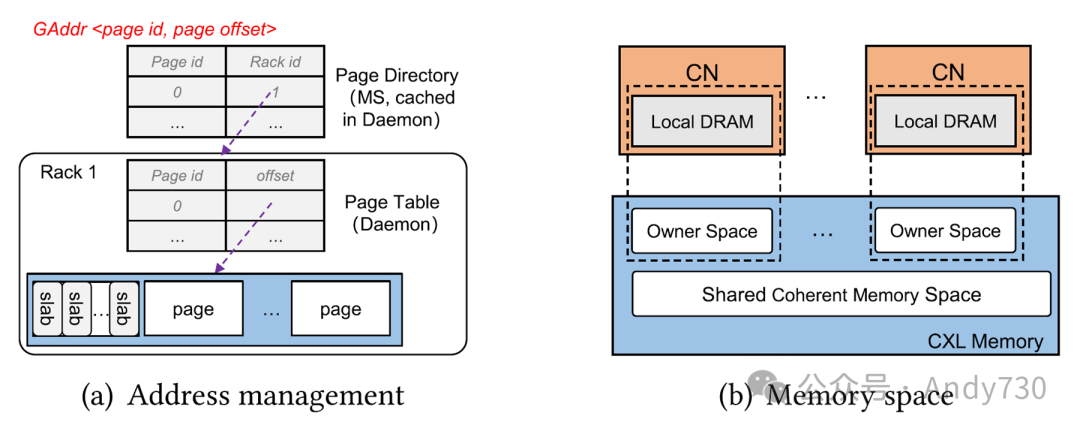
图7. 全局内存和地址管理 内存空间包括 CXL 内存和 CN 和 Daemon 的本地 DRAM,如图7(b)所示。在一个机架中,每个 CN 都有用于缓存本地机架页面的元数据的小型本地 DRAM,包括页面表和热度信息。Daemon 的本地 DRAM(1)存储本地机架页面表和远程访问的页面热度元数据,(2)缓存页面目录和远程机架的页面表。CXL 内存由两部分组成:一个大型的共享一致内存空间和每个 CN 注册的所有者内存空间。所有者内存用作远程机架的 CXL 缓存,用于写缓冲和页面缓存。
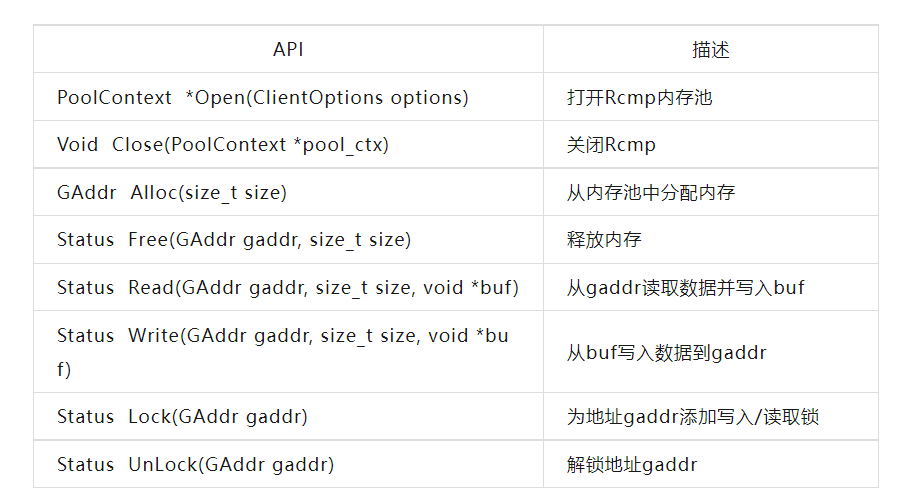
表4. Rcmp API
接口。如表4所示,Rcmp提供了常见的内存池接口,包括打开/关闭、内存分配/释放、数据读取/写入以及锁定/解锁。打开操作根据用户配置(ClientOptions)打开内存池,在成功时返回内存池上下文(PoolContext)指针,否则返回 nullptr。使用分配操作时,Daemon 在 CXL 内存中为应用程序查找一个空闲页面,并更新页面表。如果没有空闲页面,则根据接近原则在本地机架中分配页面。如果机架中没有空闲空间,则随机在远程机架中分配页面(例如,使用哈希函数)。读取/写入操作通过 CXL 在本地机架或 RDMA 在远程机架中读取/写入任意大小的数据。包括 RLock 和 WLock 的锁定操作用于并发控制。锁定地址必须首先进行初始化。使用这些 API 来编程 Rcmp 的示例如图8所示。

图8. 使用Rcmp API的示例代码
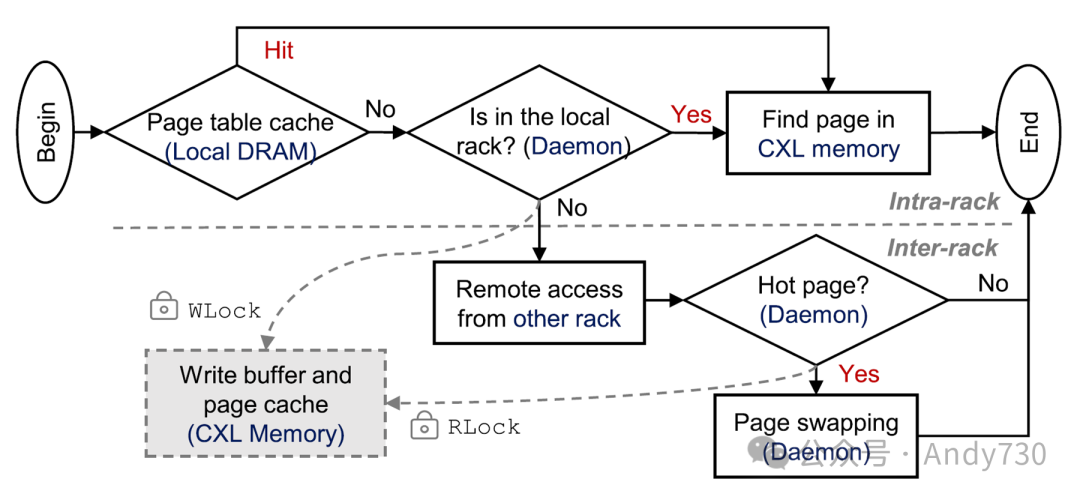
图9. Rcmp的工作流程
工作流程。Rcmp 的访问工作流程如图9所示。当 CN 中的应用程序使用读取或写入操作访问内存池时,请注意以下事项。首先,如果在本地 DRAM 中缓存的页面表中找到页面,则通过 Load/Store 操作直接访问 CXL 内存。其次,否则,从 MS 中找到页面所在的机架,并且页面目录被缓存在 Daemon 的本地 DRAM 中。之后,就不需要联系 MS,CN 直接与 Daemon 通信。第三,对于本地机架访问,CN 通过搜索 Daemon 中的页面表获取数据位置(页面偏移量)。然后,直接在 CXL 内存中访问。第四,对于远程机架访问,Daemon 通过与远程机架中的 Daemon 通信获取页面偏移量并缓存页面表。然后通过单边 RDMA READ/WRITE 操作直接访问远程机架中的数据。在这个过程中,远程机架中的 Daemon 通过 CXL 代理接收访问请求并访问 CXL 内存。第五,如果在远程机架访问时存在热页,则会触发页面交换机制。第六,如果存在 WLock 或 RLock,Rcmp 启用写入缓冲或页面缓存以减少远程机架访问。
5.2 机架内通信 CN需要与 Daemon 通信以确定它们是本地机架访问还是远程机架访问,但是两种情况的访问延迟存在显著差异。为防止通信阻塞,Rcmp 针对不同的访问场景使用两种环形缓冲区结构,如图10所示。
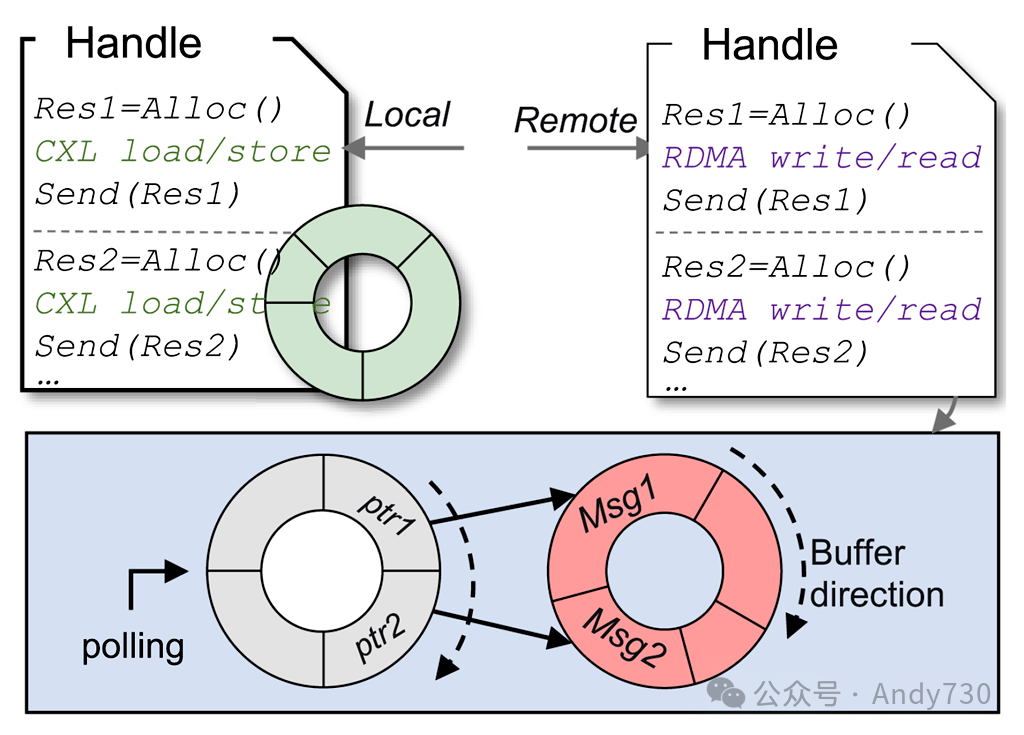
图10. 机架内通信机制
对于本地机架访问,使用普通的环形缓冲区进行通信。图中的绿色缓冲区是一个示例。在这种情况下,由于所有访问都是超低延迟(通过 CXL),即使在高冲突情况下也不会发生阻塞。此外,基于 Flock 的方法[36],环形缓冲区(和 RDMA QP)在线程(一个 CN)之间共享,以实现高并发性。
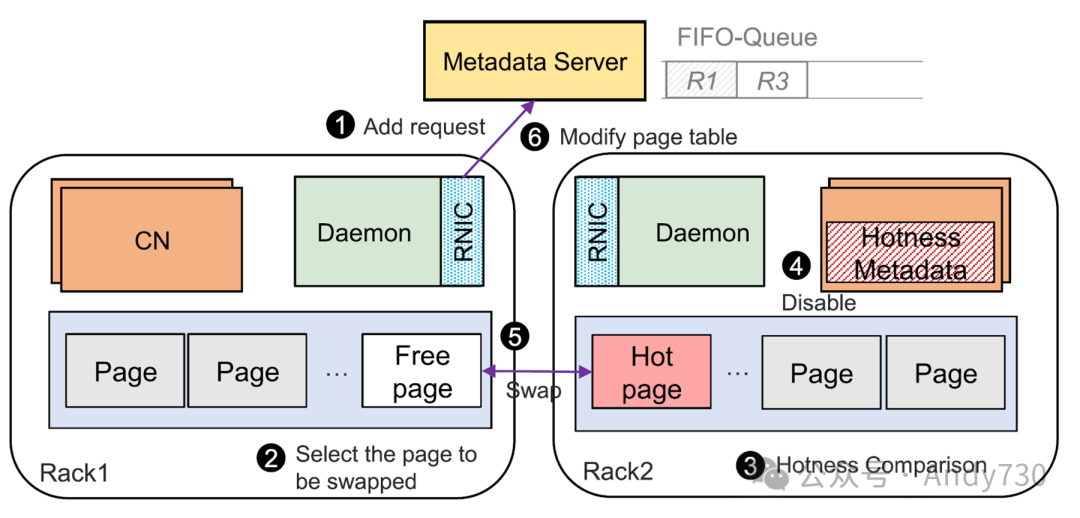
图11. 热页交换
对于远程机架访问,使用双层环形缓冲区进行高效和并发的通信,如图10所示。第一个环形缓冲区(轮询缓冲区)存储消息元数据(例如,类型、大小)和一个指向第二个缓冲区(数据缓冲区)的指针 ptr,后者存储消息数据。轮询缓冲区中的数据长度固定,而数据缓冲区中的消息长度可变。当数据缓冲区中的消息完成时,将请求添加到轮询缓冲区。Daemon 轮询轮询缓冲区以处理当前 ptr 指向的消息。例如,在图10中,数据缓冲区中的后续消息 Msg2 首先填充,并且请求首先添加到轮询缓冲区。因此,Msg2 将首先被处理,而不会发生阻塞。此外,不同的消息可以同时处理。在实现中,我们使用无锁 KFIFO 队列[50]作为轮询缓冲区,数据缓冲区是普通的环形缓冲区。 5.3 热页识别与交换 为了减少远程机架访问,Rcmp 设计了热页识别和交换策略。其目的是识别远程机架中经常访问的热页,并将它们迁移到本地机架。
热页识别。我们提出了一种过期策略来识别热页。具体来说,一个页面的热度由其访问频率和自上次访问以来的时间段来衡量。我们维护三个变量,分别命名为 Curr、Curw 和 lastTime,用来表示页面的读访问次数、写访问次数和最近一次访问的时间。在访问页面并计算热度时,我们首先得到 Δt,即当前时间减去 lastTime。如果 Δt 大于有效生存期阈值 Tl,则将页面定义为“过期”,并将 Curr、Curw 清零。页面的热度等于 α × (Curr + Curw) + 1,其中 α 是指数衰减因子,α = e^-λΔt,λ 是一个“衰减”常数。然后,根据访问类型,Curr 或 Curw 加 1。如果热度大于阈值 Hp,则页面为“热页”。此外,如果热页的 (Curr/Curw) 大于阈值 Rrw,则页面为“读热”。所有阈值都是可配置的,并具有默认值。在一个机架中,所有 CN(本地 DRAM)维护本地机架页面的热度值(或热度元数据),而远程机架页面的热度元数据存储在 Daemon 中。由于每个页面维护三个变量,约为 32 字节,内存开销很小。更新页面的热度元数据的时间复杂度也很低,仅为 O(1)。
热页交换与缓存。Rcmp 提出了一种用户级别的交换机制,与基于页面的系统的交换机制(如 LegoOS、Infiniswap)不同,后者依赖于主机的内核交换守护程序(kswapd)[3, 21, 22, 44]。以 R1 机架中希望交换 R2 机架中热页的 CN 为例,交换过程如下。1 R1(Daemon)的交换请求发送到 MS,并添加到 FIFO 队列中,该队列用于避免重复请求同一页面导致系统被淹没。2 R1 选择空闲页面作为要交换的页面。如果没有空闲空间,则收集所有 CN 的热度元数据,并选择热度最低的页面作为要交换的页面。如果要交换的页面仍然是“热页”(例如,扫描工作负载),则停止交换过程,转向 6。3 R2 求和页面的热度(与 R1 交换的页面)在所有 CN 中的热度,并将结果与 R1 的热度进行比较。如果 R2 的热度更高,则拒绝交换过程,转向 6,但如果对于 R1,该页面是“读热”的,则该页面将被缓存在 R1 的 CXL 存储器中。页面缓存是只读的,在页面需要写入时将被删除(见第 5.4 节)。这种基于比较的方法避免了页面频繁迁移(页面乒乓效应)。此外,在读密集型工作负载下,通过缓存“读热”数据可以提高性能。4 R2 禁用有关页面的热度元数据,并更新所有 CN 的页面表。5 根据两个单向 RDMA 操作交换热页。6 更新页面表,R1 的请求出队。
5.4 CXL缓存和同步机制 为了减少大规模细粒度工作负载下频繁的远程访问,Rcmp提出了一种简单高效的缓存和同步机制,基于Lock/UnLock操作。其主要思想是通过缓存线粒度将锁与数据耦合在一起,即相同缓存线中的数据共享同一把锁[9]。Rcmp为每个CN在CXL内存中设计了写入缓冲区和页面缓存,并通过同步机制实现了机架间的一致性。机架内的一致性可以通过CXL来保证,无需额外的策略。
CXL写入缓冲区。通过WLock操作,请求节点(CN)成为所有者节点(其它节点无法修改)。在这种情况下,CN可以将远程机架的细粒度写入请求(默认情况下小于256B)缓存在CXL写入缓冲区中。当缓冲区达到一定大小或WLock被解锁时,Rcmp使用后台线程异步批处理写入对应的远程机架。我们目前的实现使用两个缓冲区结构,当一个缓冲区已满时,所有写入请求会转到新的缓冲区。缓冲区结构默认为高并发SkipList,类似于LSM-KV存储中的内存表结构[12]。
CXL页面缓存。类似地,当使用RLock操作时,CN变为共享节点。页面可以缓存在CXL页面缓存中,在页面交换过程中的第3步。当页面将要被写入或RLock被解锁时,CN将使页面缓存无效。
5.5 RRPC框架 与传统的RDMA和RPC框架相比,RRPC采用了一种混合方法,可以根据不同的数据模式自适应地选择RPC和单边RDMA通信。RRPC受图3中的测试结果启发,使用512B作为阈值动态选择通信模式。其主要思想是有效地利用RDMA的高带宽特性来分摊通信延迟。如图12所示,RRPC包括三种通信模式。
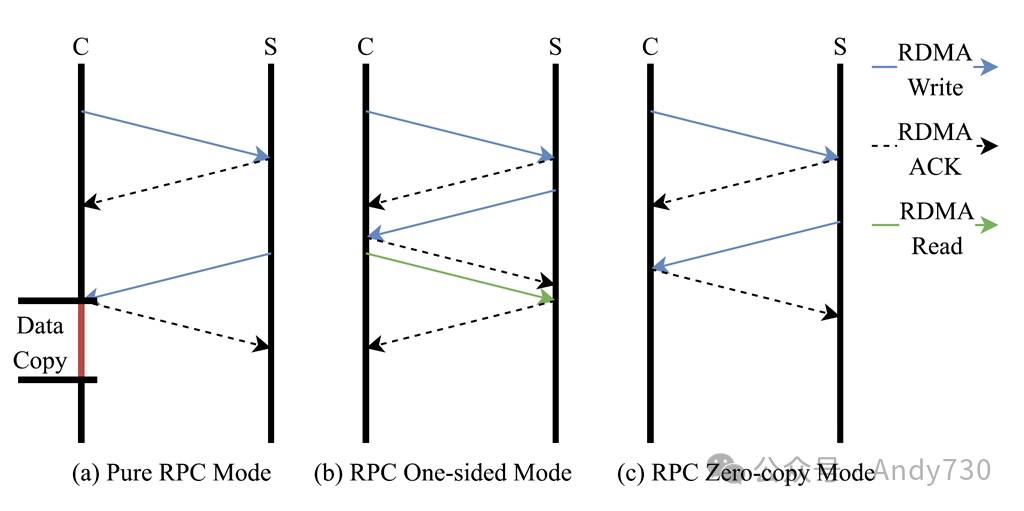
图12. RRPC中的不同通信模式 纯RPC模式用于传输数据量小于512B的通信,包括事务中的锁定、数据索引查询和内存分配等场景。 RPC和单边RDMA模式适用于非结构化大数据(超过512B)和未知数据大小的场景,如对象存储场景。在这种情况下,客户端在请求服务器之前很难知道要访问的对象的大小。因此,需要先通过RPC获取远程地址,然后在本地分配指定大小的空间,并最终通过RDMA单边读操作进行远程获取。 RPC零拷贝模式适用于结构化大数据(超过512B)且大小固定的场景,例如SQL场景。由于数据具有固定的大小,通信模式在发送RPC请求时可以携带本地空间的地址,并且数据可以直接通过RDMA单边写操作写入。 对于后两种模式,一旦通过RPC获取了页面地址,Rcmp将对其进行缓存,并且在后续访问中只使用单边RDMA读/写。此外,RRPC采用QP共享、门铃批处理等方法来优化RDMA通信,借鉴了其它工作的优点。
06. 评估
在本章中,我们使用不同的基准测试评估了Rcmp的性能。首先介绍了Rcmp的实现和实验设置(第6.1节和第6.2节)。接下来,我们使用微基准测试将Rcmp与其它三个远程内存系统进行比较(第6.3节)。然后,我们运行了一个使用YCSB基准测试的键值存储,以展示Rcmp的性能优势(第6.4节)。最后,我们评估了Rcmp中关键威廉希尔官方网站 的影响(第6.5节)。
6.1 实现 Rcmp是一个用户级系统,没有内核空间的修改,实现了6483行C++代码。在Rcmp中,页面默认为2 MB,因为它在元数据大小和延迟之间取得了良好的平衡;每个写缓冲区为64 MB,页面缓存为LRU缓存,包含50页;阈值Tl默认为100秒,Hp为4,λ为0.04,Rrw为0.9。这些阈值根据应用场景进行调整。RRPC框架是基于eRPC实现的。 虽然现在可以购买支持CXL的FPGA原型,但我们仍然选择基于NUMA的仿真来实现CXL内存,原因有两个。首先,在英特尔的测量中,基于FPGA的原型具有更高的延迟,超过250 ns。正如CXL总裁Siamak Tavallaei所介绍的那样,“这些早期的CXL概念验证和产品尚未针对延迟进行优化。随着时间的推移,CXL内存的访问延迟将得到显著改善。”其次,除了类似的访问延迟外,NUMA架构是高速缓存一致性的,使用Load/Store语义作为CXL。
6.2 实验设置 所有实验均在五台服务器上进行,每台服务器配备两个套装的Intel Xeon Gold 5218R CPU @ 2.10 GHz,128 GB DRAM,以及一个100-Gbps Mellanox ConnectX-5 RNIC。操作系统为Ubuntu 20.04,内核版本为Linux 5.4.0-144-generic。NUMA节点0和节点1之间的互连延迟为138.5 ns和141.1 ns,节点内访问延迟分别为93 ns和89.7 ns。 Rcmp与其它四种最先进的远程内存系统进行了比较:(1)Fastswap[3],一个基于页面的系统;(2)FaRM[17],一个基于对象的系统;(3)GAM[9],一个通过RDMA提供缓存一致性协议的分布式内存系统;以及(4)CXL-over-Ethernet,一个基于CXL的内存解耦合系统,使用以太网(详情见第7章)。我们使用开源代码运行Fastswap和GAM。由于FaRM不是公开的,我们使用Cai等人的工作中的代码[9]。请注意,FaRM和GAM实际上不是真正的“分离式”架构;它们的CN具有与远程内存相同大小的本地内存。我们修改了一些配置(减少本地内存)以将它们移植到分离的架构中。由于缺乏FPGA设备和CXL-over-Ethernet的未发布源代码,我们基于Rcmp的代码实现了CXL-over-Ethernet原型。为了公平起见,RDMA网络也用于CXL-over-Ethernet。
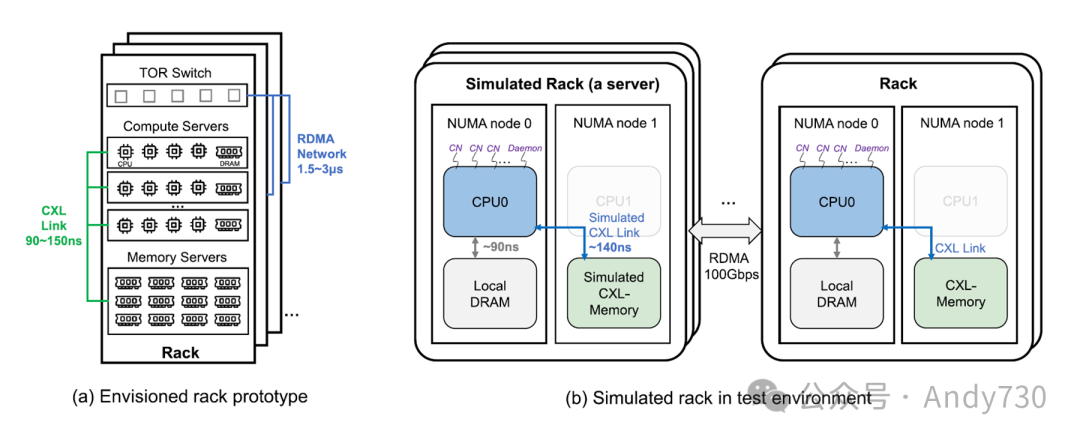
图13. 设想的原型和模拟环境
系统部署和模拟环境。图13(a)显示了Rcmp的构想架构。在一个机架中,低延迟的CXL用于连接CN和MN以形成一个小内存池;RDMA用于连接机架(与支持RDMA的ToR交换机的互连)。CXL链接速度为90至150 ns;RDMA网络延迟为1.5至3微秒。我们的测试环境如图13(b)所示。由于设备有限,我们使用一台服务器模拟一个机架,包括一个小型计算池和内存池(或CXL内存)。对于Rcmp和CXL-over-Ethernet,计算池在一个CPU插槽上运行,一个无CPU的MN作为CXL内存。在Rcmp的计算池中,不同进程运行不同的CN客户端,一个进程运行Daemon。对于其它系统,内存池通过RDMA连接到计算池。此外,机架中的内存池或CXL内存具有约100 GB的DRAM,计算池的本地DRAM为1 GB。我们使用微基准测试评估不同系统的基本读/写性能,并使用YCSB基准测试[15]评估它们在不同工作负载下的性能,如表5所示。
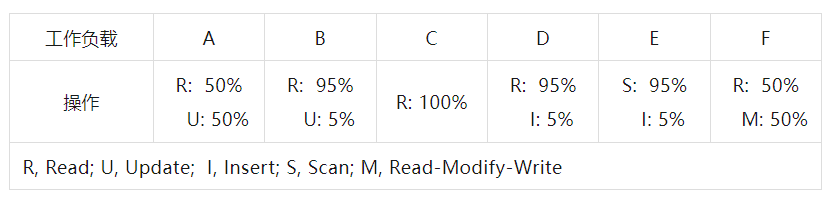
表5. YCSB工作负载
6.3 微基准测试结果 我们首先通过运行带有随机读写操作的微基准测试来评估这些系统的整体性能和可扩展性。数据大小默认为64B,并且每次读写操作使用100M数据项。
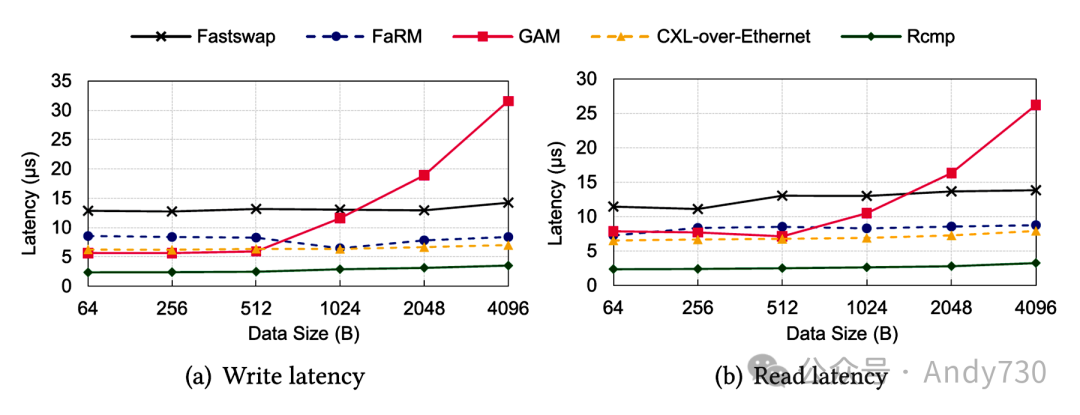
图14. 访问延迟
整体性能。如图14所示,在两个机架的环境下,我们运行微基准测试10次,使用不同的数据大小,并比较平均延迟。每个机架都预先分配了相同数量的内存页面。 结果显示,Rcmp具有更低且更稳定的写入/读取延迟(<3.5μs和<3μs)。具体来说,与其它系统相比,写入延迟降低了2.3到8.9倍,读取延迟降低了2.7到8.1倍。这是通过Rcmp对CXL的有效利用实现的,其中包括了有效的通信和热页面交换等设计,以最小化系统延迟。Fastswap的访问延迟超过了12μs,比Rcmp高出约5.2倍。当所访问的数据不在本地DRAM缓存中时,Fastswap会基于高成本的页面故障从远程内存池获取页面,导致了更高的开销。
FaRM具有较低的读/写延迟,约为8μs,这是由于其基于对象的数据管理和高效的消息原语来改善RDMA通信。GAM也是一种基于对象的系统,当数据大小小于512B时性能表现良好(约5μs),但当数据较大时,延迟会急剧增加。这是因为GAM使用512B作为默认的缓存行大小,当数据跨越多个缓存行时,GAM需要同步地在所有缓存行上维护一致性状态,导致性能下降。此外,写操作在GAM中是异步的且流水线化的,具有较低的写延迟(见图14(a))。CXL-over-Ethernet通过CXL也实现了低的读写延迟(6-8μs)。然而,CXL-over-Ethernet在计算池中部署CXL,并为内存池采用缓存策略,没有充分利用CXL低延迟的优势。此外,CXL-over-Ethernet并未针对网络进行优化,这是混合架构的主要性能瓶颈。
可扩展性。我们通过改变不同的客户端和机架来测试不同系统的可扩展性。每个客户端都运行一个微基准测试。我们有五台服务器,最多可以建立五个机架。
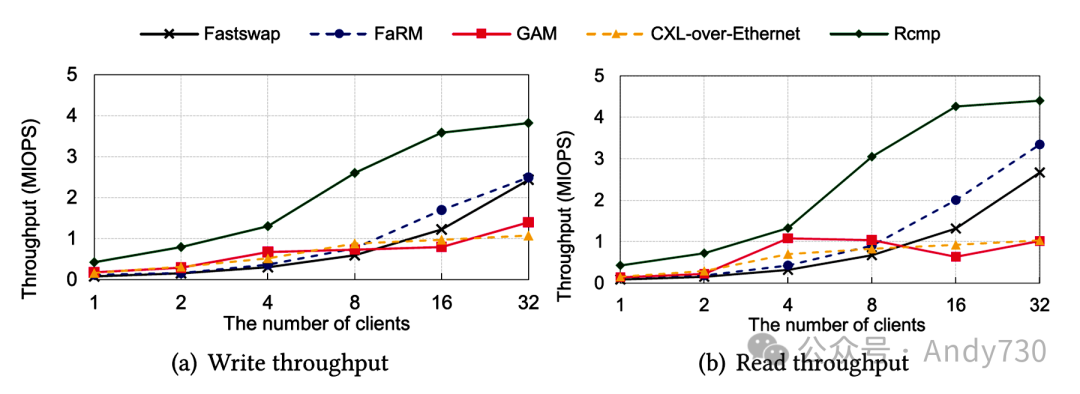
图15. 不同客户端下的总吞吐量 首先,我们在双机架环境中比较了多个客户端同时读/写的吞吐量。如图15所示,当客户端少于16个时,Rcmp的吞吐量与客户端数量大致呈线性关系。然而,当客户端数量增多时,由于只有一个守护进程,可扩展性受到限制。因此,对于规模更大的节点,Rcmp将采用多个守护进程服务器(参见第4.2节)。由于高效的页面错误驱动远程内存访问,Fastswap随着客户端的增加几乎呈线性增长。FaRM在读操作方面尤其具有良好的可扩展性,这要归功于高效的通信原语。相比之下,GAM仅在四个线程内表现出线性可扩展性。当涉及更多客户端时,GAM的性能改善幅度较小,甚至可能是负的,这是由于其用户级库的软件开销。为了确保一致性,GAM必须获取锁来检查每个内存访问的访问权限,在密集访问场景中这会带来很高的开销。在CXL-over-Ethernet中,除了8个线程之外,其它线程在通过CXL代理访问内存池之前都需要进行通信,这成为性能瓶颈。
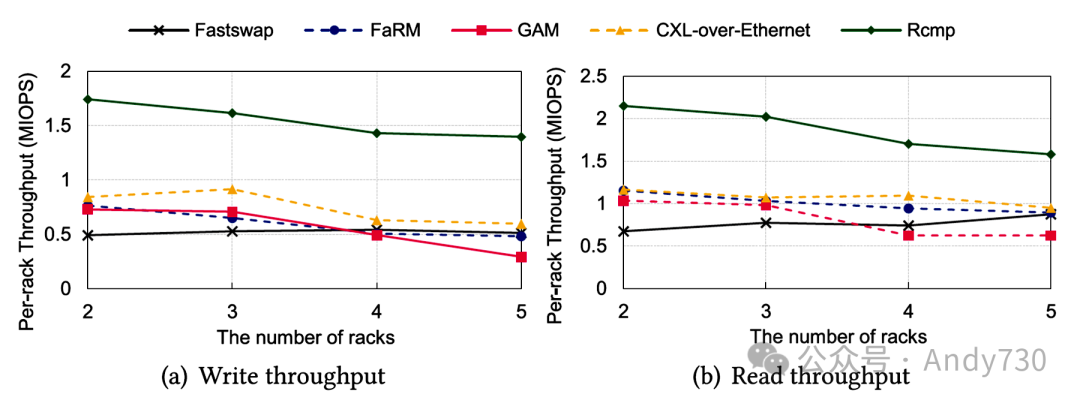
图16. 不同机架下的每机架吞吐量 其次,我们增加了机架数量,并在每个机架上运行了八个客户端。每个机架的访问数据均匀分布在整个内存池中。如图16所示,Fastswap的吞吐量不受机架数量的影响,并具有出色的可扩展性。Rcmp和FaRM由于不同机架之间的竞争而略有性能损失。在Rcmp中,还存在热页交换的竞争,但通过热页识别机制得到缓解。GAM的缓存一致性开销在多机架环境中变得更加明显,导致性能严重下降。对于CXL-over-Ethernet,计算池中的代理限制了可扩展性。 总之,Rcmp通过几项创新设计有效地利用了CXL来减少访问延迟并提高可扩展性,而其它系统则面临着较高的延迟或可扩展性较差的问题。
6.4 键值存储和YCSB工作负载 我们在这些系统上运行了一个通用的键值存储接口,该接口在内部实现为哈希表。接着,我们运行了广泛使用的YCSB基准测试[15](如表5所示的六种工作负载)来评估性能。由于哈希表不支持范围查询,因此不执行YCSB E工作负载。所有实验均在双机架环境中运行。我们预先加载了100M个键值对,每个大小为64B,然后在均匀分布和Zipfian分布(默认偏斜度为0.99)下执行不同的工作负载。图17显示了不同系统的吞吐量,所有数据均标准化为Fastswap。基于这一结果,可以得出以下结论。
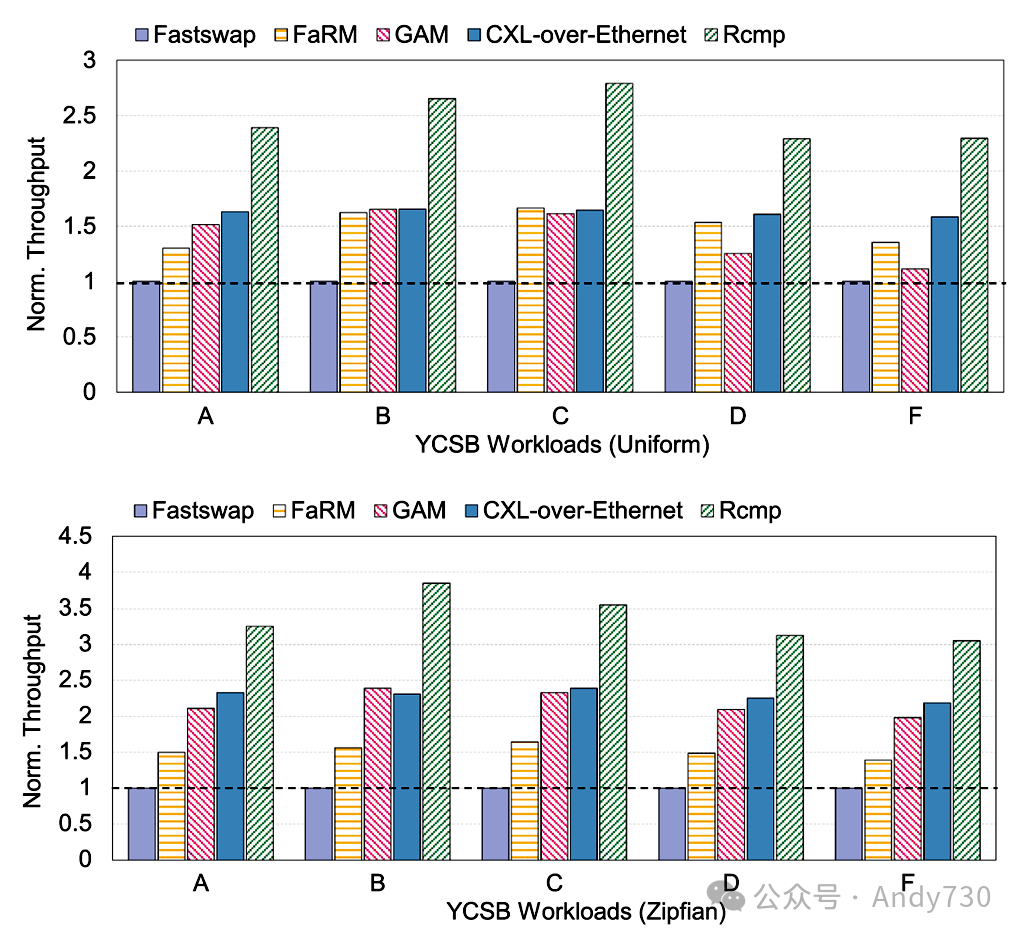
图17. YCSB工作负载的归一化吞吐量 首先,通过有效地利用CXL,Rcmp在所有工作负载上的性能均比基于RDMA的系统提高2到4倍。具体而言,对于读密集型工作负载(YCSB B、C、D),Rcmp的性能比Fastswap提高了约3倍,避免了页面错误开销,并通过热页交换减少了机架间的数据移动。此外,Rcmp设计了高效的通信机制和RRPC框架以实现最佳性能。
FaRM、GAM和CXL-over-Ethernet的性能也更好,比Fastswap提高了约1.5倍。这是因为FaRM只需一个单边无锁读操作即可进行远程访问。GAM或CXL-over-Ethernet在本地内存或CXL内存中提供统一的缓存策略。在内存解耦合架构下,缓存的好处受到本地DRAM的限制。对于写密集型工作负载(YCSB A和F),Rcmp的吞吐量提高了1.5倍。 其次,Rcmp在Zipfian工作负载中的性能提升更加显著,吞吐量提高了最多3.8倍。
由于热页在Zipfian工作负载下经常被访问,Rcmp通过将热页迁移到本地机架,大大减少了慢速远程机架访问。在Zipfian工作负载下,GAM和CXL-over-Ethernet也有显著的性能改进,这是由于高缓存命中率。 总之,通过有效地利用CXL和其它优化措施,Rcmp在性能上优于其它系统。在内存解耦合架构中,其它系统存在明显的限制,大多数数据是通过访问远程内存池获取的。 例如,基于内核的、以页面为粒度的Fastswap具有高成本的中断开销。GAM的缓存策略在稀缺的本地内存中性能提升有限。此外,FaRM的一些操作依赖于双边协作,这与由于内存池的近零计算能力而与这种分离式架构不兼容。
6.5 关键威廉希尔官方网站 的影响 本节重点讨论四种策略对Rcmp性能的影响,包括通信机制、交换和缓存策略以及RRPC。这些策略旨在减轻性能不匹配问题(介于RDMA和CXL之间)并最大化CXL的性能优势。
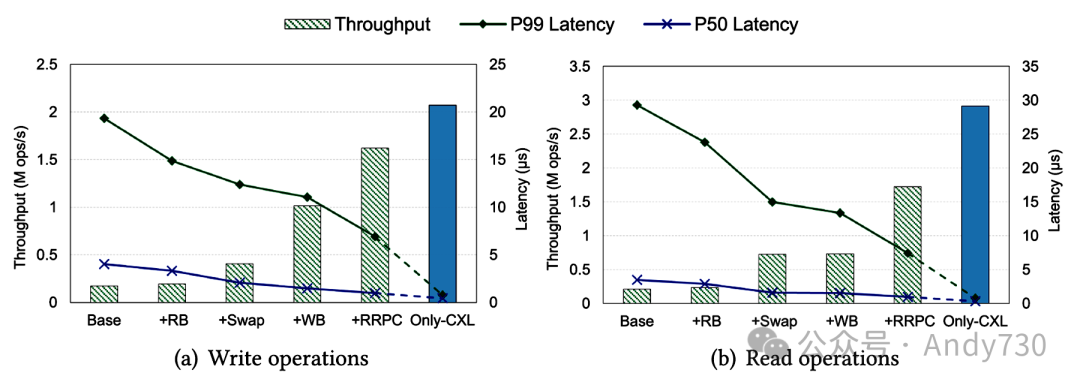
图18. 威廉希尔官方网站 对性能的贡献 我们首先逐个应用Rcmp的关键威廉希尔官方网站 ,在双机架环境下的微基准测试结果如图18所示。基准表示Rcmp的基本版本,包括单层环形缓冲区、eRPC等。+RB表示采用双层环形缓冲区;+Swap和+WB表示进一步应用热页交换和CXL写缓冲区;+RRPC表示采用RRPC框架,并展示了Rcmp的最终性能。Rcmp-only-CXL表示所有读/写操作在机架内执行,不涉及RDMA网络。从理论上讲,纯CXL解决方案是Rcmp性能的上限,但只能在机架内部署。结果显示,这些威廉希尔官方网站 降低了Rcmp与Rcmp-only-CXL之间的性能差距,但Rcmp在尾部延迟和读吞吐量方面仍有改进空间。其中,双层环形缓冲区减少了延迟,尤其是尾部延迟。交换策略极大地降低了延迟,提高了吞吐量,这在读操作中更为明显。写缓冲区和RRPC显著提高了吞吐量,写缓冲区主要影响写操作。 然后,我们详细分析了每种威廉希尔官方网站 的好处。默认情况下,所有实验均在双机架环境中运行。
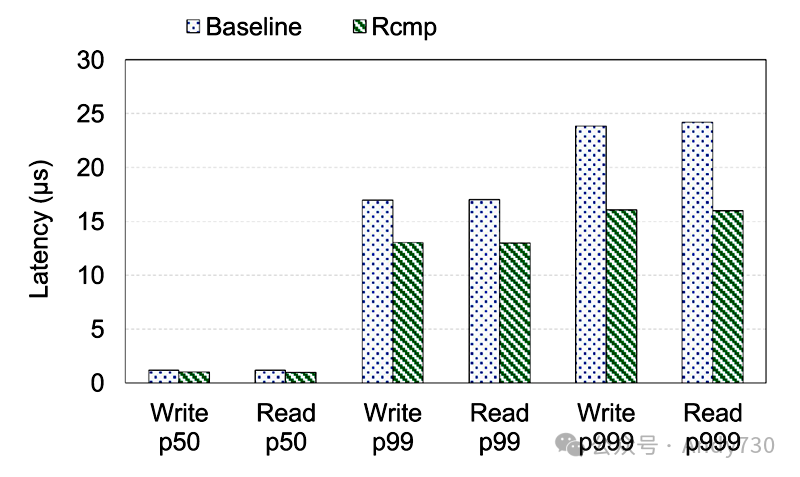
图19. 环形缓冲区
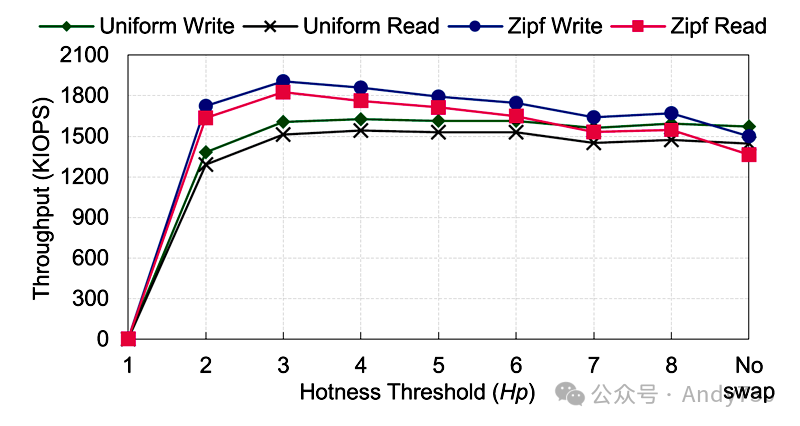
图20. 热页交换
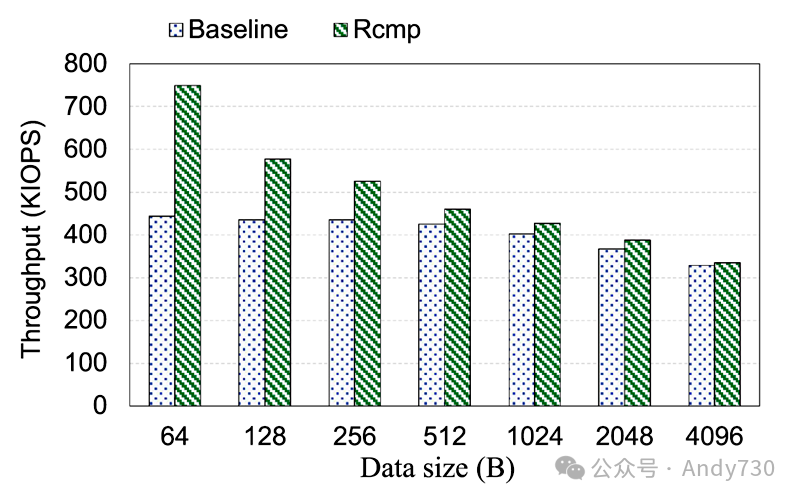
图21. 写入缓冲区
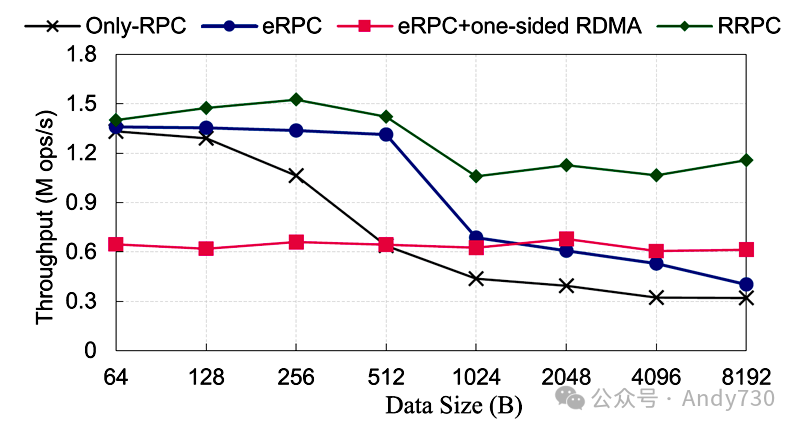
图22. RRPC框架
机架内通信。如图19所示,我们比较了两种策略在微基准测试下的延迟(p50、p99、p999):(1)使用单个环形缓冲区(基准线)和(2)使用两个环形缓冲区进行不同访问模式(Rcmp)。结果显示,Rcmp将第50、99和999百分位延迟分别降低了最多21.7%、30.9%和51.5%。由于本地和远程机架访问之间的延迟差距,单一通信缓冲区可能导致阻塞问题,触发更长的尾部延迟。Rcmp通过高效的通信机制解决了这个问题。
热页交换。我们在不同分布(均匀、Zipfian)下运行微基准测试,以评估热页交换的效果。结果如图20所示,可以得出以下结论。首先,热页交换策略可以显著提高性能,特别是对于倾斜的工作负载。例如,交换策略(Hp=3)可以使均匀工作负载的吞吐量提高5%,在Zipfian工作负载下提高35%。其次,频繁的页面交换会导致性能下降。当热度阈值设置得很低时(例如Hp=1),吞吐量会暴跌,因为当阈值很低时,每次远程访问可能会触发一次页面交换(类似于基于页面的系统),导致高额外开销。
写缓冲区。假设使用WLock操作的场景,我们通过在不同数据大小下运行微基准测试来评估使用写缓冲区(Rcmp)和不使用缓冲区(基准线)的吞吐量。如图21所示,Rcmp在所有数据大小下的吞吐量均比基准线高出最多1.6倍。数据被缓存在写缓冲区中,并通过后台线程异步批处理到远程机架。因此,Rcmp将写操作从关键执行路径中移除,并减少了对远程机架的访问,增强了写性能。然而,当数据大于256B时,性能提升不明显,并且后台线程会导致更多的CPU开销。因此,当数据大于256B时,Rcmp不使用写缓冲区。
RRPC框架。我们将RRPC与FaRM的RPC [17]、eRPC [24]框架和混合模式(eRPC + 单边RDMA动词)在不同传输数据大小下进行比较。如图22所示,当传输数据较大时,RRPC的吞吐量比eRPC + 单边RDMA动词高出1.33到1.89倍,比eRPC高出1.5到2倍。eRPC在数据小于968B时表现良好,但当数据较大时,eRPC性能下降。这是因为eRPC基于UD(不可靠数据报)模式,每个消息有一个MTU(最大传输单元)大小,默认为1KB,当数据大于MTU大小时,它将被分成多个数据包,导致性能下降。RRPC只会在数据小于512B时选择eRPC方法,并在数据较大时选择混合模式。此外,RRPC采用了几种策略来提高RDMA通信性能。
6.6讨论 支持去中心化。中心化设计使得MS容易成为性能瓶颈,Rcmp通过利用CN本地DRAM来减轻这一问题。Rcmp试图实现一种具有一致性哈希的去中心化架构,并使用Zookeeper可靠地维护集群成员关系,类似于FaRM。 支持缓存I/O。Rcmp采用无缓存访问模式,避免了跨机架维护一致性的开销。通过去中心化架构,Rcmp可以在CXL内存中为远程机架设计缓存结构,并使用Zookeeper在机架之间维护缓存一致性。
透明性。尽管Rcmp提供了非常简单的API和标准数据结构的内置实现(例如哈希表),但仍然有许多场景希望将传统应用迁移到Rcmp而无需修改其源代码。参考Gengar [18],我们将Rcmp与FUSE [1]集成,实现了一个简单的分布式文件系统,可以用于大多数应用而无需修改源代码。使用说明可以在Rcmp的源代码中找到,网址为https://github.com/PDS-Lab/Rcmp。
07. 相关工作
7.1 基于 RDMA 的远程内存 基于页面的系统。
Infiniswap [22] 是一种基于页面的远程内存系统,使用 RDMA 网络,执行分散式页面分配和回收,利用单边 RDMA 操作。Infiniswap 使用内核空间的块设备作为交换空间,在用户空间中使用守护进程管理可访问的远程内存。类似的基于页面的系统包括 LegoOS [44],这是一个新型资源分离式操作系统,提供全局虚拟内存空间;Clover [51],一个基于 RDMA 的分离式持久性内存(pDPM)系统,将元数据/控制平面与数据平面分离;Fastswap [3],一种通过远程感知的远程内存快速交换系统,通过远程感知的集群调度程序等。然而,这些基于页面的系统存在 I/O 放大问题,因为操作粒度较粗,需要处理页面错误和上下文切换等额外开销。
基于对象的系统。基于对象的内存解耦合系统设计自己的对象接口(如键值存储),直接参与 RDMA 数据传输。FaRM [17] 是一种基于 RDMA 的基于对象的远程内存系统,将集群中所有服务器的内存公开为共享地址空间,并提供高效的 API 简化远程内存的使用。AIFM [41] 是一种应用集成的远程内存系统,提供便捷的 API,采用高性能的运行时设计以最小化对象访问的开销。Xstore [57] 采用学习索引构建 RDMA 基础的键值存储中的远程内存缓存。然而,这些系统并非完全“解耦合”,因为每个 CN 包含与远程内存相同大小的本地内存。FUSEE 是一个完全内存解耦合的键值存储,基于 RACE 哈希索引 [67] 实现了对元数据管理的内存解耦合,这是一种单边 RDMA 感知的可扩展哈希。Gengar [18] 是一个基于对象的混合内存池系统,提供全局内存空间(包括远程 NVM 和 DRAM)通过 RDMA。
通信优化。大多数基于 RDMA 的系统提出了优化策略,提高 RDMA 通信效率。FaRM 提出了基于无锁环形缓冲区的消息传递原语,最小化远程内存的通信开销。此外,FaRM 通过共享 QP 减少了 RNIC 的缓存未命中。Clover 通过使用巨大内存页(HugePage)注册内存区域提高 RDMA 的可扩展性。Xstore 使用门铃批处理减少多个 RDMA 读/写操作的网络延迟。FaSST [26] 提出了一种快速的 RPC 框架,使用双边不可靠的 RDMA 而不是单边动词,特别适用于小消息。然而,双边动词不适用于分离式架构,并且 FaSST 对大消息不高效。许多远程系统采用 eRPC [24],这是一个通用的 RPC 库,提供可比较的性能,没有 RDMA 原语。但我们观察到,仅 RPC 对于内存解耦合系统并不是最优的。
7.2 支持缓存一致性 GAM [9] 是一个利用 RDMA 提供缓存一致性内存的分布式内存系统。GAM 通过基于目录的缓存一致性协议在本地和远程内存之间维护一致性。然而,这种方法具有很高的维护开销。新的互连协议,如 CXL [45] 或 CCIX [6],原生支持缓存一致性,并且与 RDMA 相比具有更低的延迟。一些研究人员尝试使用这些协议重新设计基于 RDMA 的内存解耦合。Kona [10] 使用缓存一致性而不是虚拟内存来透明跟踪应用程序的内存访问,从而减少基于页面的系统中的读/写放大。Rambda [61] 是一个使用缓存一致性加速器连接到类似 CXL 的缓存一致性内存的 RDMA 驱动加速框架,并采用 cpoll 机制来减少轮询开销。
7.3 基于 CXL 的内存解耦合 DirectCXL [21] 是一种基于 CXL 的内存解耦合,实现了通过 CXL 协议直接访问远程内存。DirectCXL 的延迟比基于 RDMA 的内存解耦合低 6.2 倍。Pond [30] 是云平台的内存池系统,基于 CXL 显着降低了 DRAM 成本。然而,这些系统没有考虑 CXL 的距离限制。CXL-over-Ethernet [56] 是一种新型基于 FPGA 的内存解耦合,通过 Ethernet 忽略了 CXL 的限制,但没有充分利用 CXL 的性能优势。
08. 结论与未来工作
在这项研究中,我们开发了 Rcmp,一个低延迟、高可扩展的内存池系统,首次将 RDMA 和 CXL 结合起来实现内存解耦合。Rcmp 在机架内构建了一个基于 CXL 的内存池,并使用 RDMA 连接机架,形成一个全局内存池。Rcmp 采用了多种威廉希尔官方网站 来解决 RDMA 和 CXL 之间不匹配的挑战。Rcmp 提出了一种全局内存和地址管理方式,以支持以缓存行粒度访问。此外,Rcmp 使用不同的缓冲结构来处理机架内和机架间的通信,避免了阻塞问题。为了减少对远程机架的访问,Rcmp 提出了一种热页面识别和迁移策略,并使用基于锁的同步机制来处理细粒度访问缓冲。为了改善对远程机架的访问,Rcmp 设计了一个优化的 RRPC 框架。评估结果表明,Rcmp 在所有工作负载中表现出色,明显优于其它基于 RDMA 的解决方案,而且没有额外的开销。 未来,我们将使用真实的 CXL 设备进行 Rcmp 实验,并优化去中心化和 CXL 缓存策略的设计(见第 6.6 节)。此外,我们将支持 Rcmp 中的其它存储设备(例如 PM、SSD 和 HDD)。
[1] GitHub. 2023. FUSE (Filesystem in Userspace). Retrieved December 8, 2023 from http://libfuse.github.io/
[2] Marcos K. Aguilera, Emmanuel Amaro, Nadav Amit, Erika Hunhoff, Anil Yelam, and Gerd Zellweger. 2023. Memory disaggregation: Why now and what are the challenges. ACM SIGOPS Operating Systems Review 57, 1 (2023), 38–46.
[3] Emmanuel Amaro, Christopher Branner-Augmon, Zhihong Luo, Amy Ousterhout, Marcos K. Aguilera, Aurojit Panda, Sylvia Ratnasamy, and Scott Shenker. 2020. Can far memory improve job throughput? In Proceedings of the 15th European Conference on Computer Systems. 1–16.
[4] Jonghyun Bae, Jongsung Lee, Yunho Jin, Sam Son, Shine Kim, Hakbeom Jang, Tae Jun Ham, and Jae W. Lee. 2021. FlashNeuron: SSD-enabled large-batch training of very deep neural networks. In Proceedings of the 19th USENIX Conference on File and Storage Technologies (FAST'21). 387–401.
[5] Luiz André Barroso, Jimmy Clidaras, and Urs Hölzle. 2013. The Datacenter as a Computer: An Introduction to the Design of Warehouse-Scale Machines (2nd ed.). Synthesis Lectures on Computer Architecture. Morgan & Claypool.
[6] Brad Benton. 2017. CCIX, GEN-Z, OpenCAPI: Overview & comparison. In Proceedings of the OpenFabrics Workshop.
[7] Som S. Biswas. 2023. Role of Chat GPT in public health. Annals of Biomedical Engineering 51, 5 (2023), 868–869.
[8] Jeff Bonwick. 1994. The slab allocator: An object-caching kernel memory allocator. In Proceedings of the USENIX Summer 1994 Technical Conference, Vol. 16. 1–12.
[9] Qingchao Cai, Wentian Guo, Hao Zhang, Divyakant Agrawal, Gang Chen, Beng Chin Ooi, Kian-Lee Tan, Yong Meng Teo, and Sheng Wang. 2018. Efficient distributed memory management with RDMA and caching. Proceedings of the VLDB Endowment 11, 11 (2018), 1604–1617.
[10] Irina Calciu, M. Talha Imran, Ivan Puddu, Sanidhya Kashyap, and Zviad Metreveli. 2021. Rethinking software runtimes for disaggregated memory. In Proceedings of the 18th ACM SIGPLAN/SIGOPS International Conference on Virtual Execution Environments. 2–16.
[11] Wei Cao, Yingqiang Zhang, Xinjun Yang, Feifei Li, Sheng Wang, Qingda Hu, Xuntao Cheng, Zongzhi Chen, Zhenjun Liu, Jing Fang, et al. 2021. PolarDB Serverless: A cloud native database for disaggregated data centers. In Proceedings of the 2021 International Conference on Management of Data. 2477–2489.
[12] Zhichao Cao and Siying Dong. 2020. Characterizing, modeling, and benchmarking RocksDB key-value workloads at Facebook. In Proceedings of the 18th USENIX Conference on File and Storage Technologies (FAST'20).
[13] Yue Cheng, Ali Anwar, and Xuejing Duan. 2018. Analyzing Alibaba's co-located datacenter workloads. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data'18). IEEE, Los Alamitos, CA, 292–297.
[14] Adrian Cockcroft. 2023. Supercomputing Predictions: Custom CPUs, CXL3.0, and Petalith Architectures. Retrieved December 8, 2023 from https://adrianco.medium.com/supercomputing-predictions-custom-cpus-cxl3-0-and-petalitharchitectures-b67cc324588f/
[15] Brian F. Cooper, Adam Silberstein, Erwin Tam, Raghu Ramakrishnan, and Russell Sears. 2010. Benchmarking cloud serving systems with YCSB. In Proceedings of the 1st ACM Symposium on Cloud Computing. 143–154.
[16] Anritsu Corporation and KYOCERA Corporation. 2023. PCI Express5.0 Optical Signal Transmission Test. Retrieved December 8, 2023 from https://global.kyocera.com/newsroom/news/2023/000694.html
[17] Aleksandar Dragojević, Dushyanth Narayanan, Miguel Castro, and Orion Hodson. 2014. FaRM: Fast remote memory. In Proceedings of the 11th USENIX Symposium on Networked Systems Design and Implementation (NSDI'14). 401–414.
[18] Zhuohui Duan, Haikun Liu, Haodi Lu, Xiaofei Liao, Hai Jin, Yu Zhang, and Bingsheng He. 2021. Gengar: An RDMAbased distributed hybrid memory pool. In Proceedings of the 2021 IEEE 41st International Conference on Distributed Computing Systems (ICDCS'21). IEEE, Los Alamitos, CA, 92–103.
[19] Luciano Floridi and Massimo Chiriatti. 2020. GPT-3: Its nature, scope, limits, and consequences. Minds and Machines 30 (2020), 681–694.
[20] Peter Xiang Gao, Akshay Narayan, Sagar Karandikar, João Carreira, Sangjin Han, Rachit Agarwal, Sylvia Ratnasamy, and Scott Shenker. 2016. Network requirements for resource disaggregation. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI'16). 249–264. https://www.usenix.org/conference/ osdi16/technical-sessions/presentation/gao
[21] Donghyun Gouk, Sangwon Lee, Miryeong Kwon, and Myoungsoo Jung. 2022. Direct access, high-performance memory disaggregation with DirectCXL. In Proceedings of the 2022 USENIX Annual Technical Conference (USENIX ATC'22). 287–294.
[22] Juncheng Gu, Youngmoon Lee, Yiwen Zhang, Mosharaf Chowdhury, and Kang G. Shin. 2017. Efficient memory disaggregation with INFINISWAP. In Proceedings of the 14th USENIX Conference on Networked Systems Design and Implementation (NSDI'17). 649–667.
[23] Patrick Hunt, Mahadev Konar, Flavio Paiva Junqueira, and Benjamin Reed. 2010. ZooKeeper: Wait-free coordination for internet-scale systems. In Proceedings of the USENIX Annual Technical Conference, Vol. 8.
[24] Anuj Kalia, Michael Kaminsky, and David Andersen. 2019. Datacenter RPCs can be general and fast. In Proceedings of the 16th USENIX Symposium on Networked Systems Design and Implementation (NSDI'19). 1–16.
[25] Anuj Kalia, Michael Kaminsky, and David G. Andersen. 2014. Using RDMA efficiently for key-value services. In Proceedings of the 2014 ACM Conference on SIGCOMM. 295–306.
[26] Anuj Kalia, Michael Kaminsky, and David G. Andersen. 2016. FaSST: Fast, scalable and simple distributed transactions with two-sided (RDMA) datagram RPCs. In Proceedings of the 12th USENIX Conference on Operating Systems Design and Implementation (OSDI'16). 185–201.
[27] Kostas Katrinis, Dimitris Syrivelis, Dionisios Pnevmatikatos, Georgios Zervas, Dimitris Theodoropoulos, Iordanis Koutsopoulos, Kobi Hasharoni, Daniel Raho, Christian Pinto, F. Espina, et al. 2016. Rack-scale disaggregated cloud data centers: The dReDBox project vision. In Proceedings of the 2016 Design, Automation, and Test in Europe Conference and Exhibition (DATE'16). IEEE, Los Alamitos, CA, 690–695.
[28] Youngeun Kwon and Minsoo Rhu. 2018. Beyond the memory wall: A case for memory-centric HPC system for deep learning. In Proceedings of the 2018 51st Annual IEEE/ACM International Symposium on Microarchitecture (MICRO'18). IEEE, Los Alamitos, CA, 148–161.
[29] Seung-Seob Lee, Yanpeng Yu, Yupeng Tang, Anurag Khandelwal, Lin Zhong, and Abhishek Bhattacharjee. 2021. Mind: In-network memory management for disaggregated data centers. In Proceedings of the ACM SIGOPS 28th Symposium on Operating Systems Principles. 488–504.
[30] Huaicheng Li, Daniel S Berger, Lisa Hsu, Daniel Ernst, Pantea Zardoshti, Stanko Novakovic, Monish Shah, Samir Rajadnya, Scott Lee, Ishwar Agarwal, et al. 2023. Pond: CXL-based memory pooling systems for cloud platforms. In Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Vol. 2. 574–587.
[31] Hosein Mohammadi Makrani, Setareh Rafatirad, Amir Houmansadr, and Houman Homayoun. 2018. Main-memory requirements of big data applications on commodity server platform. In Proceedings of the 2018 18th IEEE/ACM International Symposium on Cluster, Cloud, and Grid Computing (CCGRID'18). IEEE, Los Alamitos, CA, 653–660.
[32] Hasan Al Maruf, Hao Wang, Abhishek Dhanotia, Johannes Weiner, Niket Agarwal, Pallab Bhattacharya, Chris Petersen, Mosharaf Chowdhury, Shobhit Kanaujia, and Prakash Chauhan. 2023. TPP: Transparent page placement for CXL-enabled tiered-memory. In Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Vol. 3. 742–755.
[33] Hasan Al Maruf, Yuhong Zhong, Hongyi Wang, Mosharaf Chowdhury, Asaf Cidon, and Carl Waldspurger. 2021. Memtrade: A disaggregated-memory marketplace for public clouds. arXiv preprint arXiv:2108.06893 (2021).
[34] Satoshi Matsuoka, Jens Domke, Mohamed Wahib, Aleksandr Drozd, and Torsten Hoefler. 2023. Myths and legends in high-performance computing. International Journal of High Performance Computing Applications 37, 3-4 (2023), 245–259.
[35] George Michelogiannakis, Benjamin Klenk, Brandon Cook, Min Yee Teh, Madeleine Glick, Larry Dennison, Keren Bergman, and John Shalf. 2022. A case for intra-rack resource disaggregation in HPC. ACM Transactions on Architecture and Code Optimization 19, 2 (2022), 1–26.
[36] Sumit Kumar Monga, Sanidhya Kashyap, and Changwoo Min. 2021. Birds of a feather flock together: Scaling RDMA RPCs with Flock. In Proceedings of the ACM SIGOPS 28th Symposium on Operating Systems Principles. 212–227.
[37] Ivy Peng, Roger Pearce, and Maya Gokhale. 2020. On the memory underutilization: Exploring disaggregated memory on HPC systems. In Proceedings of the 2020 IEEE 32nd International Symposium on Computer Architecture and High Performance Computing (SBAC-PAD'20). IEEE, Los Alamitos, CA, 183–190.
[38] The Next Platform. 2022. Just How Bad Is CXL Memory Latency? Retrieved December 8, 2023 from https://www. nextplatform.com/2022/12/05/just-how-bad-is-cxl-memory-latency/
[39] Amanda Raybuck, Tim Stamler, Wei Zhang, Mattan Erez, and Simon Peter. 2021. HeMem: Scalable tiered memory management for big data applications and real NVM. In Proceedings of the ACM SIGOPS 28th Symposium on Operating Systems Principles. 392–407.
[40] Charles Reiss, Alexey Tumanov, Gregory R. Ganger, Randy H. Katz, and Michael A. Kozuch. 2012. Heterogeneity and dynamicity of clouds at scale: Google trace analysis. In Proceedings of the 3rd ACM Symposium on Cloud Computing. 1–13.
[41] Zhenyuan Ruan, Malte Schwarzkopf, Marcos K. Aguilera, and Adam Belay. 2020. AIFM: High-performance, application-integrated far memory. In Proceedings of the 14th USENIX Conference on Operating Systems Design and Implementation. 315–332.
[42] Rick Salmonson, Troy Oxby, Larry Briski, Robert Normand, Russell Stacy, and Jeffrey Glanzman. 2019. PCIe Riser Extension Assembly. Technical Disclosure Commons (January 11, 2019). https://www.tdcommons.org/dpubs_series/1878
[43] Alex Shamis, Matthew Renzelmann, Stanko Novakovic, Georgios Chatzopoulos, Aleksandar Dragojević, Dushyanth Narayanan, and Miguel Castro. 2019. Fast general distributed transactions with opacity. In Proceedings of the 2019 International Conference on Management of Data. 433–448.
[44] Yizhou Shan, Yutong Huang, Yilun Chen, and Yiying Zhang. 2018. LegoOS: A disseminated, distributed OS for hardware resource disaggregation. In Proceedings of the 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI'18). 69–87.
[45] Debendra Das Sharma and Ishwar Agarwal. 2022. Compute Express Link. Retrieved December 8, 2023 from https: //www.computeexpresslink.org/_files/ugd/0c1418_a8713008916044ae9604405d10a7773b.pdf/
[46] Navin Shenoy. 2023. A Milestone in Moving Data. Retrieved December 8, 2023 from https://www.intel.com/content/ www/us/en/newsroom/home.html
[47] Vishal Shrivastav, Asaf Valadarsky, Hitesh Ballani, Paolo Costa, Ki Suh Lee, Han Wang, Rachit Agarwal, and Hakim Weatherspoon. 2019. Shoal: A network architecture for disaggregated racks. In Proceedings of the 16th USENIX Symposium on Networked Systems Design and Implementation (NSDI'19). 255–270. https://www.usenix.org/conference/ nsdi19/presentation/shrivastav
[48] Intel. 2019. Intel Rack Scale Design (Intel RSD) Storage Services. API Specification. Intel.
[49] Yan Sun, Yifan Yuan, Zeduo Yu, Reese Kuper, Ipoom Jeong, Ren Wang, and Nam Sung Kim. 2023. Demystifying CXL memory with genuine CXL-ready systems and devices. arXiv preprint arXiv:2303.15375 (2023).
[50] Torvalds. 2023. Linux Kernel Source Tree. Retrieved December 8, 2023 from https://github.com/torvalds/linux/blob/ master/lib/kfifo.c
[51] Shin-Yeh Tsai, Yizhou Shan, and Yiying Zhang. 2020. Disaggregating persistent memory and controlling them remotely: An exploration of passive disaggregated key-value stores. In Proceedings of the 2020 USENIX Annual Technical Conference. 33–48.
[52] Stephen Van Doren. 2019. HOTI 2019: Compute express link. In Proceedings of the 2019 IEEE Symposium on HighPerformance Interconnects (HOTI'19). IEEE, Los Alamitos, CA, 18–18.
[53] Alexandre Verbitski, Anurag Gupta, Debanjan Saha, Murali Brahmadesam, Kamal Gupta, Raman Mittal, Sailesh Krishnamurthy, Sandor Maurice, Tengiz Kharatishvili, and Xiaofeng Bao. 2017. Amazon Aurora: Design considerations for high throughput cloud-native relational databases. In Proceedings of the 2017 ACM International Conference on Management of Data. 1041–1052.
[54] Midhul Vuppalapati, Justin Miron, Rachit Agarwal, Dan Truong, Ashish Motivala, and Thierry Cruanes. 2020. Building an elastic query engine on disaggregated storage. In Proceedings of the 17th USENIX Symposium on Networked Systems Design and Implementation (NSDI'20). 449–462.
[55] Jacob Wahlgren, Maya Gokhale, and Ivy B. Peng. 2022. Evaluating emerging CXL-enabled memory pooling for HPC systems. arXiv preprint arXiv:2211.02682 (2022).
[56] Chenjiu Wang, Ke He, Ruiqi Fan, Xiaonan Wang, Wei Wang, and Qinfen Hao. 2023. CXL over Ethernet: A novel FPGA-based memory disaggregation design in data centers. In Proceedings of the 2023 IEEE 31st Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM'23). IEEE, Los Alamitos, CA, 75–82.
[57] Xingda Wei, Rong Chen, and Haibo Chen. 2020. Fast RDMA-based ordered key-value store using remote learned cache. In Proceedings of the 14th USENIX Conference on Operating Systems Design and Implementation. 117–135.
[58] Qin Xin, Ethan L. Miller, Thomas Schwarz, Darrell D. E. Long, Scott A. Brandt, and Witold Litwin. 2003. Reliability mechanisms for very large storage systems. In Proceedings of the 2003 20th IEEE/11th NASA Goddard Conference on Mass Storage Systems and Technologies (MSST'03). IEEE, Los Alamitos, CA, 146–156.
[59] Juncheng Yang, Yao Yue, and K. V. Rashmi. 2020. A large scale analysis of hundreds of in-memory cache clusters at Twitter. In Proceedings of the 14th USENIX Conference on Operating Systems Design and Implementation. 191–208.
[60] Qirui Yang, Runyu Jin, Bridget Davis, Devasena Inupakutika, and Ming Zhao. 2022. Performance evaluation on CXLenabled hybrid memory pool. In Proceedings of the 2022 IEEE International Conference on Networking, Architecture, and Storage (NAS'22). IEEE, Los Alamitos, CA, 1–5.
[61] Yifan Yuan, Jinghan Huang, Yan Sun, Tianchen Wang, Jacob Nelson, Dan R. K. Ports, Yipeng Wang, Ren Wang, Charlie Tai, and Nam Sung Kim. 2023. RAMBDA: RDMA-driven acceleration framework for memory-intensive μs-scale datacenter applications. In Proceedings of the 2023 IEEE International Symposium on High-Performance Computer Architecture (HPCA'23). IEEE, Los Alamitos, CA, 499–515.
[62] Erfan Zamanian, Carsten Binnig, Tim Kraska, and Tim Harris. 2016. The end of a myth: Distributed transactions can scale. CoRR abs/1607.00655 (2016). http://arxiv.org/abs/1607.00655
[63] Ming Zhang, Yu Hua, Pengfei Zuo, and Lurong Liu. 2022. FORD: Fast one-sided RDMA-based distributed transactions for disaggregated persistent memory. In Proceedings of the 20th USENIX Conference on File and Storage Technologies (FAST'22). 51–68.
[64] Yifan Zhang, Zhihao Liang, Jianguo Wang, and Stratos Idreos. 2021. Sherman: A write-optimized distributed B+Tree index on disaggregated memory. arXiv preprint arXiv:2112.07320 (2021).
[65] Yingqiang Zhang, Chaoyi Ruan, Cheng Li, Xinjun Yang, Wei Cao, Feifei Li, Bo Wang, Jing Fang, Yuhui Wang, Jingze Huo, et al. 2021. Towards cost-effective and elastic cloud database deployment via memory disaggregation. Proceedings of the VLDB Endowment 14, 10 (2021), 1900–1912.
[66] Tobias Ziegler, Carsten Binnig, and Viktor Leis. 2022. ScaleStore: A fast and cost-efficient storage engine using DRAM, NVMe, and RDMA. In Proceedings of the 2022 International Conference on Management of Data. 685–699.
[67] Pengfei Zuo, Jiazhao Sun, Liu Yang, Shuangwu Zhang, and Yu Hua. 2021. One-sided RDMA-conscious extendible hashing for disaggregated memory. In Proceedings of the USENIX Annual Technical Conference. 15–29. Received 9 July 2023; revised 12 October 2023; accepted 26 November 2023
审核编辑:黄飞












 工商网监
工商网监
评论