 电子发烧友App
电子发烧友App


本文对最近被 TPAMI 接收的一篇综述文章 Human Action Recognition from Various Data Modalities: A Review(基于不同数据模态的人类动作识别综述)进行解读。

1 概述
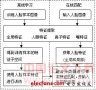
人类动作识别(Human Action Recognition, HAR)旨在理解人类的行为,并为每个行为分配一个标签。多种不同的数据形态都可以用来表示人类的动作和行为。这些模态可以分为 2 类:视觉模态和非视觉模态,视觉模态和非视觉模态的主要区别在于:视觉模态的数据对人类行为的表示相对直观,但是非视觉模态的数据则不是。视觉模态主要包括:如 RGB,骨架,深度,红外,点云,事件流(event stream)等数据模态,而非视觉模态则主要包括音频,加速度,雷达,wifi 信号等数据模态,如图 1 所示。这些数据模态是对不同的信息来源进行编码,根据应用场景的不同,不同模态的数据有着不同的独特优势。

图 1 HAR 任务中使用到的数据模态 该综述对基于不同数据模态的深度学习 HAR 方法的最新进展做了一个综合调研。介绍调研的主要内容分为三部分(1)当前主流的单模态深度学习方法。(2)当前主流的多模态深度学习方法,包括基于融合(fusion)和协同学习(co-learning)的学习框架。(3)当前 HAR 任务的主流数据集。
2 单模态学习方法
前文中已经提到,不同模态具有着独特的优势,在这些模态中,单独使用 RGB / 光流模态和骨架模态的 HAR 工作相对较多。而其他模态由于其大多存在一些固有的缺陷,所以单独使用的情况较少,大部分情况下都是与其他模态结合使用。
2.1 RGB 和光流模态
RGB 模态指的是由 RGB 相机捕获的图像或序列。而光流则是视频图像中同一对象(物体)像素点移动到下一帧的移动量,由于通常是由 RGB 模态数据所进一步生成,所以下文中把 RGB 和光流模态统称为 RGB 模态。RGB 模态的优点和缺点都非常明显,优点主要有:(1)RGB 数据容易收集,通常是最常用的数据模态。(2)RGB 模态包含所捕获的场景上下文的信息。(3)基于 RGB 的 HAR 方法也可以用来做 pretrained model。缺点主要有:(1)由于 RGB 数据中存在背景、视点、尺度和光照条件的变化,所以在 RGB 模态中进行识别通常具有挑战性。(2)RGB 视频数据量较大,计算成本较高。图 2 展示了基于 RGB 模态数据的 HAR 方法的主要分类,下面分别对这些方法进行介绍。
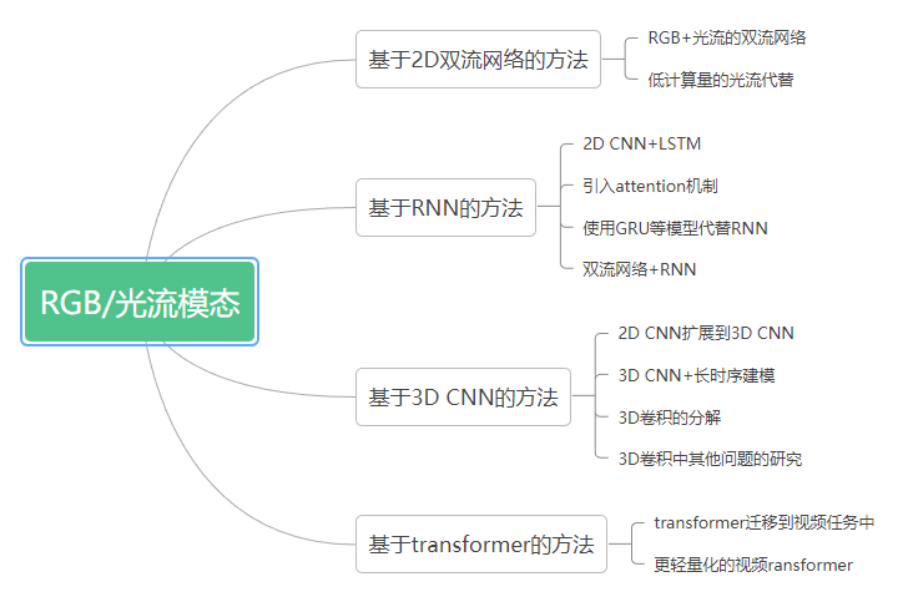
图 2 基于 RGB / 光流模态的 HAR 方法分类
基于 2D 双流网络的方法。
这类方法的核心思想是,通过两个或多个 backbone 学习不同的视频特征,[1]和 [2] 是这类方法中最具代表性的工作,[1]的两个 stream 分别输入 RGB 帧和多帧的光流,以分别学习外观特征和运动特征, RGB + 光流的模态组合也被很多后续的工作所效仿。[2]则对低分辨率 RGB 帧和高分辨率 RGB 帧的中心裁剪输入两个 stream 中,以降低计算量。 精确的光流获取通常需要很高的计算成本,所以如何在较低的计算成本下获取光流的近似或代替也是此类方法一个研究重点。如 [3] 提出了一个基于知识蒸馏的框架实现从使用光流训练的 teacher network 到使用 motion vector 作为输入的 student 网络的知识迁移。motion vector 可以直接从 compressed videos 中获得,而不再需要额外的计算。
基于 RNN 的方法
2D 双流网络的一个缺点是对时序上的长期依赖关系的建模不足,那么使用时序建模的网络如 LSTM,则可以弥补这一点。这类基于 RNN 的方法依据其核心贡献又可以分为 4 小类:(1)2D CNN 与 RNN 的组合:如 [4] 使用 2D CNN 提取每个 frame 的特征,然后再使用 LSTM 生成动作标签。(2)attention 机制的引入,attention 机制主要包括空间的 attention 和时序的 attention,或两者的组合。比如 [5] 设计了一个多层的 LSTM 模型,可以递归地输出对下一帧的输入 feature map 的 attention map。(3)使用 GRU 等模型来代替 RNN,相比于 RNN,GRU 的参数更少,但在 HAR 任务上通常可以提供与 LSTM 相近的性能。(4)2D 双流网络和 RNN 的结合,比如 [6] 中利用 2D 双流网络分别提取 spatial 和短期的运动特征,然后再分别输入 2 个 LSTM 来提取长时的运动信息。
基于 3D CNN 的方法。
基于 RNN 的方法通常是对 CNN 已经提取出的 feature 进行操作,而不是对原始的图像序列进行操作。基于 3D CNN 的方法则可以做到这一点。基于 3D CNN 的方法依据其核心贡献同样分为 4 小类:(1)2D CNN 到 3D CNN 的扩展,[7]使用 3D conv 从原始的视频中直接学习时空特征。(2)对长时序依赖关系的建模,3D CNN 有着 CNN 共同的特点,侧重于对 local 信息的提取,而对 global 信息的提取能力不足。[8]中提出了一个长时时间卷积框架,以降低空间分辨率为代价,增加了 3D 卷积在 temporal 维度上的感受野。(3)3D conv 的分解:3D 卷积通常包含大量的参数,也需要大量的训练数据,因此其计算量较大。[9]提出将 3D conv 分解成了空间上的 2d conv 和时间维度上的 1d conv。(4) 对 3D conv 中其他问题的讨论,比如 [10] 从概率的角度分析了 3d conv 中的时空融合,[11]提出了一个随机均值缩放的正则化方法来解决过拟合问题。
基于 transformer 的方法。
transformer 是一种以 attention 机制为核心的模型,其在长时序建模、多模态融合和多任务处理等方面具有良好的性能,由于 transformer 在 NLP 领域的成功应用,目前也有很多将 transformer 应用到 HAR 任务中的方法,如 [12] 通过把 video 分解成 frame-level 的 patches,将 VIT 应用到了视频中,并且在模型的每个 block 中分别应用了 spatial 和 temporal 的 attention。 但是,transformer 的通病是其所需的显存和计算开销一般较大,所以也有很多工作,研究了如何降低基于 transformer 的视频理解模型的复杂度,比如 [13] 将 3d 的视频帧转换成 2d 的 super image 作为 transformer 的输入。[14]使用了在 spatial 维度进行特征处理的 backbone(例如 2D CNN)和基于 temporal attention 的 encoder 来达到精度和速度之间的权衡。
2.2 骨架数据模态
骨架序列表人体关节的轨迹,这些轨迹可以用来表征人体的运动,因此骨架数据是比较适配于 HAR 任务的一种数据模态,骨架数据提供的是身体结构与姿态信息,其具有两个明显的优点:(1)具有比例不变性。(2)对服装纹理和背景是鲁棒的。但同时也有两个缺点:(1)骨架信息的表示比较稀疏,存在噪声。(2)骨架数据缺少人 - 物交互时可能存在的形状信息。图 3 展示了基于骨架模态数据的 HAR 方法的主要分类,下面分别对这些方法进行介绍。
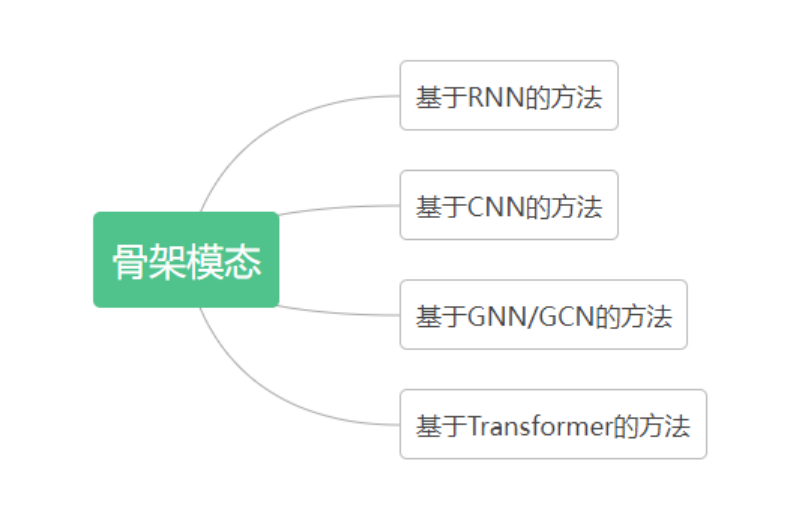
图 3 基于骨架数据模态的 HAR 方法分类
基于 RNN 的方法。
使用 RNN 的核心原因是希望能够学习时序数据中的动态依赖性。这类基于 RNN 和骨架数据的 HAR 方法,大多聚焦于 RNN 或 LSTM 等模型在 HAR 任务上的改进和应用。如 [15] 将人体骨骼分为 5 个部分,这 5 部分分别输入到多个双向 RNN 中,然后再将其输出进行分层融合,以生成动作的高级表示。[16]提出了一个部分感知 LSTM,并interwetten与威廉的赔率体系 了 LSTM 单元中不同身体部分之间的关系。
基于 CNN 的方法。
CNN 以其在空间维度上卓越的特征提取和学习能力,在 2D 图像识别任务中取得了巨大的成功。把 CNN 应用到基于骨架数据的 HAR 任务中时,一个研究重点是对时空信息的建模。如 [17] 和[18]的思路是将骨架序列数据编码成图像,然后送入 CNN 中进行动作识别,它们分别给出了骨骼光谱图和关节轨迹图。此外也有一些工作专注于解决某些特定的问题,比如视点变化问题和计算成本过高的问题。
基于 GNN/GCN 的方法。
将人体的骨架数据表示为一个序列或 2d/3d 的 image,并不能对身体关节作出完全准确的模拟。而人体的骨架天然地就可以表示为一个 graph,因此基于 GNN 或 GCN 的 HAR 方法成为了近两年一个热门的研究方向。[19]将人体的骨架表示为了一个有向无环图以有效地合并骨骼和关节信息。[20]设计了一个时空 GCN(Spatial-temporal GCN)以从骨架数据中分别学习 spatial 和 temporal 的 feature。
基于 transformer 的方法。
将 transformer 应用于骨骼序列的 HAR 任务时,研究的重点仍然是时空维度的建模。比如 [21] 中提出 Spatial-Temporal Specialized Transformer (STST),其由一个 spatial transformer 模块和一个 temporal transformer 模块组成。spatial transformer 模块用于捕捉 frame-level 的姿态信息,temporal transformer 用于在 temporal 维度上捕捉长动作。
2.3 深度模态
深度图中的像素值表示的是从给定视点到场景中的点的距离,所以构建深度图的本质是将 3D 数据转换为 2D 的 image。该模态通常对颜色和纹理的变化比较鲁棒,随着威廉希尔官方网站 的发展,现在已经有多种设备可以捕获场景中的深度图。现有的对深度数据学习的方法大多数还是利用 CNN 提取深度图中的 feature。深度数据可以提供几何形状信息,但是对外观数据的提供是缺失的,所以深度数据通常不单独使用,而是与其他模态的数据融合使用。
2.4 红外模态
红外数据的获取主要有两种方式:(1)主动式,发射红外线,利用目标反射的红外线感知场景中的物体。(2)被动式,通过感知物体发出的红外线来感知物体。在目前基于深度学习的方法中,比较多的做法是把红外图像作为其中一个 stream 输入双流或多流网络中。红外数据以其不需要依赖外部环境的可见光的特点,特别适合于夜间的 HAR,但是,红外图像也有着对比度低和信噪比低的固有缺点。
2.5 点云模态
点云数据由大量的点组成,这些点可以用来表示物体的空间分布和表面特征。作为一种三维数据形态,点云具有很强的表达物体轮廓和三维几何形状的能力,且对视点的变化不敏感。但是点云中通常存在噪声和高度不均匀的点分布。[22]将原始的点云序列转换为规则的体素集合,并应用 temporal rank pooling 将 3D 动作信息编码到一个单独的 voxel set 中。最后通过 PonitNet++[23]将体素表示应用于 3D HAR 任务中。但是将点云转换为体素不仅效率较低,而且会带来量化误差。[24]提出直接堆叠多帧点云,并通过聚合 temporal 和 spatial 维度上的相邻点的信息计算局部特征。
2.6 事件流模态
事件照相机(event camera)可以捕捉照明条件的变化并为每个像素独立产生异步事件。传统的摄像机通常会捕捉整个图像阵列,而事件摄像机仅响应视觉场景的变化。事件照相机能够有效地滤除背景信息,而只保留前景运动信息,这样可以避免视觉信息中的大量冗余,但是其捕捉到的信息通常在时间和空间维度上是稀疏的,而且是异步的。因此一些现有的方法主要聚焦于设计事件聚合策略,将事件摄像机的异步输出转换为同步的视觉帧。
2.7 音频模态
音频信号通常与视频信号一起提供,由于音频和视频是同步的,所以音频数据可以用定位动作。因为音频信号中的信息量是不足的,所以单独使用音频数据执行 HAR 任务相对比较少见。更常见的情况是音频信号作为 HAR 的补充信息,与其他模态(如 rgb 图像)一起使用。
2.8 加速度模态
加速度信号通常是从加速度计中获得,它具有以下的优点:(1)对遮挡、视点、照明、背景等因素的变化具有鲁棒性。(2)对某个特定的动作,人们一般都使用相似的方式完成,所以加速度信号对同一个动作的类内方差较小。(3)加速模态可以用于细粒度的 HAR。但同时,该模态也存在一些固有的局限性:(1)志愿者需要随身佩戴传感器,而且这些传感器通常比较笨重。(2)传感器在人体上的具体位置对性能会有比较明显的影响。
2.9 雷达模态
雷达的工作原理是发射电磁波并接收来自目标的回波,其优势是对照明和天气条件变化鲁棒,并且具有穿墙感知的能力,但昂贵的传感器成本是制约其实际应用的重要因素。现有的方法将多普勒频谱图视作时间序列或图像,并分别送入 RNN 和 CNN 中以预测行为类别,目前也有一些方法,将雷达模态的数据纳入到了双流网络结构中。
2.10 wifi 模态
wifi 是现在最常见的室内无线信号类型之一,由于人体是无线信号的良好反射体,所以 wifi 信号可以用于 HAR 任务,现有的基于 wifi 的 HAR 方法大多使用信道状态信息(CSI)来执行 HAR 任务。如何更有效地利用 CSI 的相位和幅度信息,以及如何在处理动态环境时提高鲁棒性,是目前基于 wifi 的 HAR 任务所面临的主要挑战。
3 多模态学习方法
多模态机器学习是一种建模方法,旨在处理和关联来自多模态的视觉信息,通过聚合各种数据模态的优势,多模态学习可以在 HAR 任务上得到更鲁棒和准确的结果。多模态学习方法主要有两种,融合(fusion)和协同学习(co-learning)。其中融合指的是对来自两个或更多模态的信息进行集成,并将其用于训练或推理,而协同学习指的则是对不同模态之间的知识进行迁移。图 4 展示了多模态学习方法的分类,对于每种类型的多模态学习方法,本篇解读会介绍原综述文章中提及的一些具有代表性的方法,更多的方法介绍请直接阅读原综述文章。
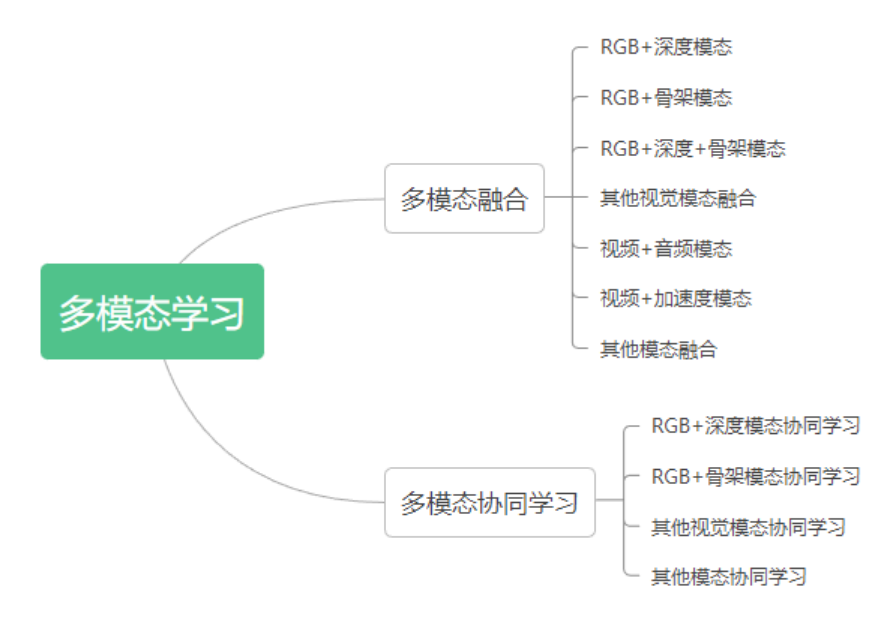
图 4 多模态 HAR 方法分类
3.1 HAR 任务中的多模态融合
模态融合的目的是利用不同数据模态的互补优势,以达到更好的识别性能。现有的多模态融合方案主要有两种:(1)评分融合(score fusion),即对不同模态输出的 score 做融合,例如使用加权平均或学习一个分数融合模型。(2)特征融合,即对来自不同模态的特征进行组合。数据融合(在特征提取之前就融合不同模态的输入数据)可以看成是特征融合,因为某一模态的数据可以被视为该模态的原始特征。依据输入模态的不同,现有的多模态融合方法大概可以分为视觉模态之间的融合,与视觉 + 非视觉模态之间的融合两种,下面对这两类方法分别做一个较为详细的介绍。
视觉模态之间的融合
(1)RGB + 深度模态:RGB 和深度模态分别能够捕捉外观信息和 3D 形状信息,因此它们具有比较强的互补性。[25]提出了一个 four-stream CNN,其中一个 stream 输入 RGB 数据,剩下三个 stream 分别输入三个不同视点下捕捉的深度运动图,融合策略选择评分融合。[26]将 RGB 和深度数据看做两对 RGB 和深度的动态图像,通过一个协同训练的 CNN 提取特征,并联合优化排序损失和 softmax 损失来进行训练。[27]同样提出了一个多流混合网络,该网络分别使用 CNN 和 3D convLSTM 来提取来自 RGB 和深度图的特征,然后通过典型关联分析(Canonical Correlation Analysis)进行模态间的信息融合。
(2)RGB + 骨架模态:骨架模态可以提供身体位置和关节运动信息,同样和 RGB 模态是互补的。[28]提出了一个双流深度网络,两个 stream 分别是 CNN 和 RNN,用以分别处理 RGB 和骨架数据,融合方式同时尝试了特征融合和分数融合,并发现应用特征融合策略可以取得更好的效果。[29]设计了一个 three-stream 的 3D CNN 来分别处理人体姿态、运动和 RGB 图像,通过马尔科夫链来融合三个 stream,并用于动作分类。[30]提出了一种时空 LSTM 网络,它能够在 LSTM 单元内有效地融合 RGB 和骨架特征。
(3)深度图 + 骨架模态:[31]将身体的每个部分与其他部分之间的相对几何关系作为骨架特征,将不同身体部分周围的深度图像块作为外观特征,以编码身体 - 对象和身体部分 - 身体部分之间的关系,进而实现可靠的 HAR。[32]提出了一种 three-stream 的 2D CNN,对深度和骨架序列提取的三种不同的手工特征进行分类,然后采用评分融合模块得到最终的分类结果。
(4)RGB + 深度图 + 骨架模态:这类方法大多是前文提到的三类多模态融合方法的扩展。如 [33] 研究了模态之间的相关性,将它们分解成相关和独立的成分,然后使用一个结构化的基于稀疏性的分类器输出分类结果。[34]从每个模态提取 temporal feature map,然后再在模态维度对这些 feature map 执行 concat 操作,以获得跨 RGB、骨架和深度模态的时变信息。[35]提出了一个 five-stream network,历史运动图像、深度运动图、以及三个分别从 RGB, 深度和骨架序列生成的骨架图像分别是这 5 个 stream 的输入。
(5)其他视觉模态间的融合:这些方法的思路与前文中所述的基本类似,比如 [36] 中提出了一个基于 TSN[37]的多模态融合模型,RGB、深度图、红外和光流序列分别使用 TSN 执行初始分类,然后使用一个融合网络,以获取最终的分类分数。
视觉模态 + 非视觉模态的融合
同样地,视觉与非视觉模态的融合,其目的也是希望能够利用不同模态之间的互补性,得到更精确的 HAR 模型。
(1)视频与音频的融合:前文中已经提到,音频可以为视频的外观和运动信息提供补充信息。所以目前已经有一些基于深度学习的方法来融合这种模态的数据,比如 [38] 引入了一个 three-stream 的 CNN,从音频信号,RGB 帧和光流中分别提取特征,然后再进行融合(在该文中,特征融合的效果好于评分融合)。[39]是 [37] 的一个改进,其在每个时间绑定窗口内融合多模态输入序列(也就是说,融合来自不同模态的信息可能是异步的)。[40]利用音频信号减少了视频中的时间冗余,其思想是把使用 video clips 训练的 teacher network 中的知识提取到使用图像 - 音频对训练的 student network 中。
(2)视频与加速度模态的融合:现有的基于深度学习的视频与加速度模态融合的方法大多是采用双流或多流网络的架构,比如 [41] 将惯性信号表示为图像,然后使用两个 CNN 分别处理视频和惯性信号,最后使用评分融合的方法融合两个模态的信号。[42]则是将 3D 视频帧序列和 2D 的惯性图像分别送入 3D CNN 和 2D CNN 中,然后执行模态间的融合。
(3)其他类型的模态融合:这类方法中,相对比较有代表性的是 [43] 和[44],其中 [43] 的核心思想是将非 RGB 模态的数据,包括骨架、加速度和 wifi 数据都转换成彩色图像,然后送入 CNN 中。[44]则提出了一种 video-audio-text transformer(VATT),将视频,音频和文本数据的线性投影作为 transformer 的输入,并提取多模态的特征表示,VATT 还量化了不同模态的粒度,并且采用视频 - 音频对和视频 - 文本对的 NCE Loss 进行训练。
3.2 HAR 任务中的多模态协同学习
多模态协同学习旨在探索如何利用辅助模态学习到的知识帮助另一个模态的学习,希望通过跨模态的知识传递和迁移可以克服单一模态的缺点,提高性能。多模态协同学习与多模态融合的一个关键区别在于,在多模态协同学习中,辅助模态的数据仅仅在训练阶段需要,测试阶段并不需要。所以多模态协同学习尤其适用于模态缺失的场景。此外对于模态样本数较小的场景,多模态协同学习也可以起到一定的帮助作用。
视觉模态的协同学习
(1)RGB 和深度模态的协同学习。如 [45] 使用知识蒸馏的方法实现模态间的协同学习,其中 teacher network 输入深度图,而 student network 输入的则是 RGB 图像。[46]提出了一种基于对抗学习的知识提取策略用来训练 student network。[47]则提出了一种合作学习策略,即在不同的输入模态中,使用分类损失最小的模态所生成的预测标签,作为其他模态训练的附加监督信息。 (2)RGB 和骨架模态的协同学习。如 [48] 利用 CNN+LSTM 执行基于 RGB 视频的分类,并利用在骨架数据上训练的 LSTM 模型充当调节器,强制两个模型的输出特征相似。 (3)其他视觉模态的协同学习。除了 RGB、骨架、深度模态的协同学习之外,目前也有一些其他的视觉模态的协同学习的工作,比如 [49] 提出了一种可迁移的生成模型,该模型使用红外视频作为输入,并生成与其对应的 RGB 视频的虚假特征表达。该方法的生成器由两个子网络组成,第一个子网络用以区分生成的虚假特征和真实的 RGB 特征,第二个子网络将红外视频的特征表达和生成的特征作为输入,执行动作的分类。
视觉和非视觉模态的协同学习
这类工作可以大致分为两种类型,第一种类型是在不同模态之间进行知识的迁移,如 [50] 中的 teacher network 使用非视觉模态训练,而 student network 使用 RGB 模态作为输入,通过强制 teacher 和 student 的 attention map 相似以弥补模态间的形态差距,并实现知识的提炼。第二种类型是利用不同模态之间的相关性进行自监督学习,比如 [51] 分别利用音频 / 视频模态中的无监督聚类结果作为视频 / 音频模态的监督信号。[52]使用视频和音频的时间同步信息作为自监督信号。
4 现有的数据集
原论文中的 table 6 展示了目前 HAR 任务的各个数据模态的数据集,展示如下:
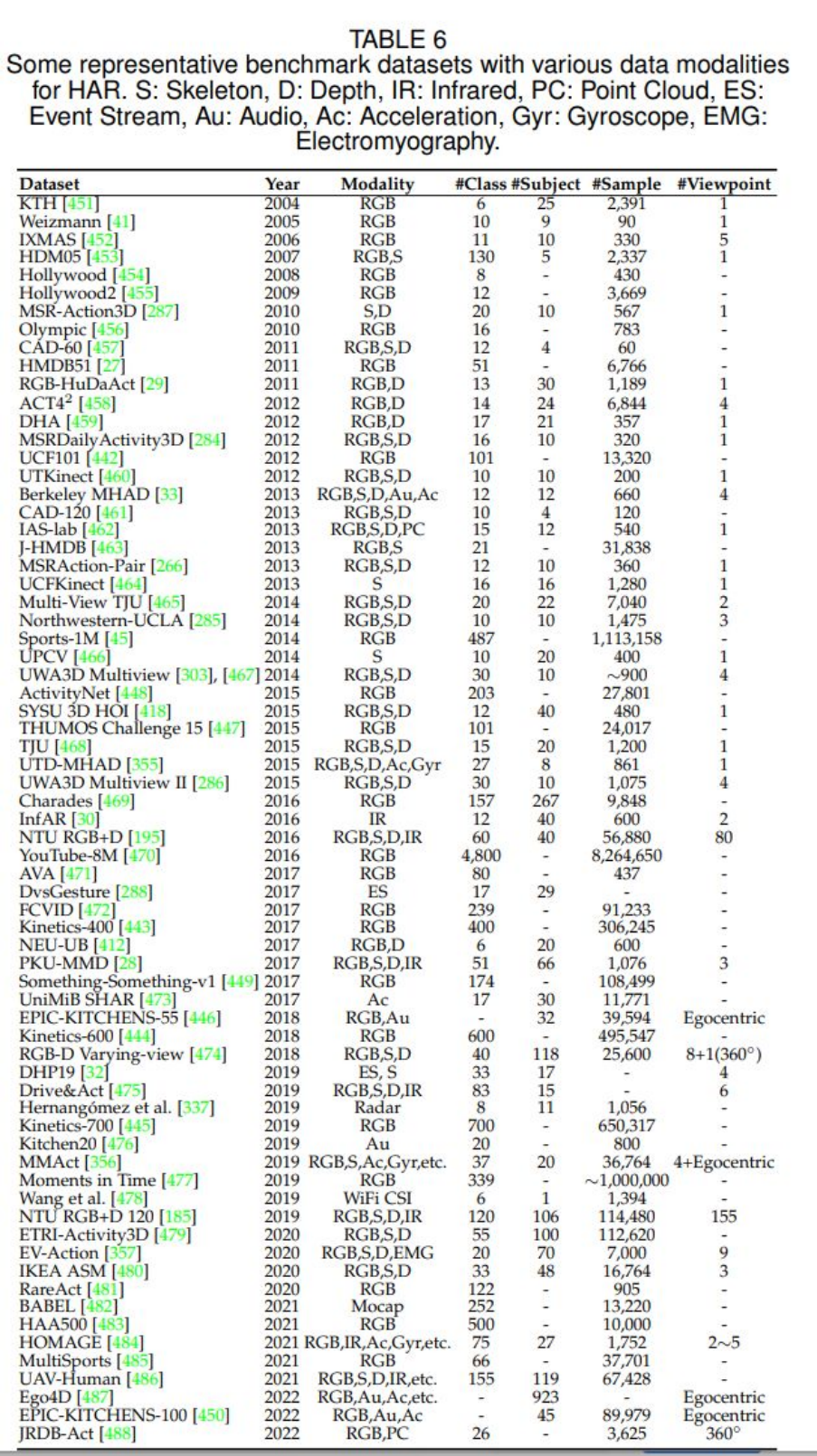
可以看到,对于绝大部分数据模态,目前都存在对应的数据集,这些数据集也在很大程度上方便了我们对 HAR 任务的研究和探索。 5 总结 作者在原综述文章的最后一部分展望了 HAR 领域未来的发展方向,作者认为有 6 个方向可能是未来研究和探索的重点,分别是:(1)新的数据集(比如不受控环境下的多模态数据集);(2)多模态学习;(3)高效的行为分析;(4)早期行为识别(即只有一部分动作被执行);(5)大规模训练;(6)无监督和半监督学习。作者还提到,他们会定期地收集 HAR 领域的最新进展并更新到本综述文章中。
6 个人思考
该综述调研了约 500 篇文章,涵盖了 HAR 任务中可能使用的各个模态,是对这一领域非常全面的总结。从综述中可以看到,无论是单模态还是多模态的模型,其 backbone 通常都是以下几种网络之一(或它们的组合):
(1)2D CNN(空间信息的提取);
(2)RNN/LSTM/GRU(时序信息的提取);
(3)3D CNN(时间 + 空间维度的信息提取);
(4)GNN/GCN(节点之间的关系抽取);
(5)transformer(长时序建模)。
对于 HAR 任务中的多模态融合来说,目前最常见的做法是使用一个双流或多流网络,每个 stream 分别提取一个模态的特征,然后再后接一个多模态融合模块。对于 HAR 任务中的多模态协同学习来说,目前常见的做法则是使用跨模态知识蒸馏或对抗学习的框架完成。这些 backbone 和融合 / 协同学习策略的组合,可以概括目前 HAR 领域的大部分文章。 对不同模态的数据,往往需要不同的模型来提取其特征,这对于 HAR 的模型设计来说是非常不方便的。有时为了适配现有的模型,需要对某些模态的数据做一些特定的预处理(比如目前提取音频模态特征的一种常用方法是,将一维的音频信号转换成二维的频谱图,再送入 CNN 中进行特征提取),这些特定的预处理可能存在一定的信息丢失。所以是否可以有一种通用的模型,能够比较好地处理各种形态不同的多模态数据呢?这是目前整个 AI 界都比较关注的一个问题,而其在 HAR 任务上体现的尤为明显。transformer 目前在图像、文本等模态中都取得了非常好的效果,它能否成为我们期待的通用模型呢?以现在 AI 领域日新月异的发展速度,我相信我们很快就可以看到答案。 另外,该综述的多模态学习部分,按照使用的模态对现有的工作进行了分类总结,而多模态学习的研究核心,很大的一部分在于模态间的融合或协同学习的策略,如果能够按照具体的融合或协同学习的策略对现有的工作进行分类总结,可能会更好一些。
参考文献
[1] K. Simonyan and A. Zisserman, "Two-stream convolutional networks for action recognition in videos," in Advances in Neural Information Processing Systems, vol. 27, 2014.
[2] A. Karpathy, G. Toderici, S. Shetty, T. Leung, R. Sukthankar, and L. Fei-Fei, "Large-scale video classification with convolutional neural networks," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2014, pp. 1725-1732.
[3] B. Zhang, L. Wang, Z. Wang, Y. Qiao, and H. Wang, "Real-time action recognition with enhanced motion vector cnns," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 2718-2726.
[4] J. Donahue, L. Anne Hendricks, S. Guadarrama, M. Rohrbach, S. Venugopalan, K. Saenko, and T. Darrell, "Long-term recurrent convolutional networks for visual recognition and description," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, pp. 2625-2624.
[5] S. Sharma, R. Kiros, and R. Salakhutdinov, "Action recognition using visual attention," arXiv preprint arXiv:1511.04119, 2015.
[6] Z. Wu, X. Wang, Y.-G. Jiang, H. Ye, and X. Xue, “Modeling spatial-temporal clues in a hybrid deep learning framework for video classification,” in Proceedings of the 23rd ACM international conference on Multimedia, 2015, pp. 461-470.
[7] D. Tran, L. Bourdev, R. Fergus, L. Torresani, and M. Paluri, "Learning spatiotemporal features with 3d convolutional networks," in Proceedings of the IEEE International Conference on Computer Vision, 2015, pp. 4489-4497.
[8] G. Varol, I. Laptev, and C. Schmid, "Long-term temporal convolutions for action recognition," IEEE transactions on pattern analysis and machine intelligence, vol. 40, no. 6, pp. 1510-1517, 2017.
[9] Z. Qiu, T. Yao, and T. Mei, "Learning spatio-temporal representation with pseudo-3d residual networks," in Proceedings of the IEEE International Conference on Computer Vision, 2017, pp. 4489-4497.
[10] Y. Zhou, X. Sun, C. Luo, Z.-J. Zha, and W. Zeng, "Spatiotemporal fusion in 3d cnns: A probabilistic view," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2020, pp. 1725-1732.
[11] J. Kim, S. Cha, D. Wee, S. Bae, and J. Kim, "Regularization on spatio-temporally smoothed feature for action recognition," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2020, pp. 12103-12112.
[12] ] G. Bertasius, H. Wang, and L. Torresani, "Is space-time attention all you need for video understanding?," in ICML, vol. 2, no. 3, 2021.
[13] Q. Fan, C.-F. Chen, and R. Panda, "Can an image classifier suffice for action recognition?," in International Conference on Learning Representations, 2022.
[14] D. Neimark, O. Bar, M. Zohar, and D. Asselmann, "Video transformer network," in Proceedings of the IEEE International Conference on Computer Vision, 2021, pp. 3163-3172.
[15] Y. Du, W. Wang, and L. Wang, "Hierarchical recurrent neural network for skeleton based action recognition," in Proceedings of the IEEE International Conference on Computer Vision, 2015, pp. 1110-1118.
[16] A. Shahroudy, J. Liu, T.-T. Ng, and G. Wang, "Ntu rgb+d: A large scale dataset for 3d human activity analysis," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 1010-1019.
[17] Y. Hou, Z. Li, P. Wang, and W. Li, "Skeleton optical spectra-based action recognition using convolutional neural networks," IEEE Transactions on Circuits and Systems for Video Technology, vol. 28, no. 3, 2016.
[18] P. Wang, Z. Li, Y. Hou, and W. Li, "Action recognition based on joint trajectory maps using convolutional neural networks," in Proceedings of the 24th ACM international conference on Multimedia, 2016, pp. 102-106.
[19] L. Shi, Y. Zhang, J. Cheng, and H. Lu, "Skeleton-based action recognition with directed graph neural networks," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 7912-7921.
[20] S. Yan, Y. Xiong, and D. Lin, "Spatial temporal graph convolutional networks for skeleton-based action recognition," in Thirty-second AAAI conference on artificial intelligence, 2018.
[21] Y. Zhang, B. Wu, W. Li, L. Duan, and C. Gan, "Stst: Spatial-temporal specialized transformer for skeleton-based action recognition," in Proceedings of the 29th ACM international conference on Multimedia, 2021, pp. 3229-3237.
[22] Y. Wang, Y. Xiao, F. Xiong, W. Jiang, Z. Cao, J. T. Zhou, and J. Yuan, "3dv: 3d dynamic voxel for action recognition in depth video," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2020, pp. 511-520.
[23] C. R. Qi, L. Yi, H. Su, and L. J. Guibas, "Pointnet++: Deep hierarchical feature learning on point sets in a metric space," in Advances in Neural Information Processing Systems, vol. 30, 2017.
[24] X. Liu, M. Yan, and J. Bohg, "Meteornet: Deep learning on dynamic 3d point cloud sequences," in Proceedings of the IEEE International Conference on Computer Vision, 2019, pp. 9246-9255.
[25] J. Imran and P. Kumar, "Human action recognition using rgb-d sensor and deep convolutional neural networks," in 2016 international conference on advances in computing, communications and informatics (ICACCI), 2016, pp. 144-148.
[26] P. Wang, W. Li, J. Wan, P. Ogunbona, and X. Liu, "Cooperative training of deep aggregation networks for rgb-d action recognition," in Thirty-second AAAI conference on artificial intelligence, 2018.
[27] H. Wang, Z. Song, W. Li, and P. Wang, "A hybrid network for large-scale action recognition from rgb and depth modalities," Sensors, vol. 20, no. 11, 2020.
[28] R. Zhao, H. Ali, and P. Van der Smagt, "Two-stream rnn/cnn for action recognition in 3d videos," in 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2017, pp. 4260-4267.
[29] M. Zolfaghari, G. L. Oliveira, N. Sedaghat, and T. Brox, "Chained multi-stream networks exploiting pose, motion, and appearance for action classification and detection," in Proceedings of the IEEE International Conference on Computer Vision, 2019, pp. 2904-2913.
[30] J. Liu, A. Shahroudy, D. Xu, A. C. Kot, and G. Wang, "Skeleton-based action recognition using spatio-temporal lstm network with trust gates," IEEE transactions on pattern analysis and machine intelligence, vol. 40, no. 12, pp. 3007-3021, 2017.
[31] H. Rahmani and M. Bennamoun, "Learning action recognition model from depth and skeleton videos," in Proceedings of the IEEE International Conference on Computer Vision, 2017, pp. 5832-5841.
[32] S. S. Rani, G. A. Naidu, and V. U. Shree, "Kinematic joint descriptor and depth motion descriptor with convolutional neural networks for human action recognition," Materials Today, vol. 37, 3164-3173, 2021.
[33] A. Shahroudy, T.-T. Ng, Y. Gong, and G. Wang, "Deep multimodal feature analysis for action recognition in rgb+d videos," IEEE transactions on pattern analysis and machine intelligence, vol. 40, no. 5, pp. 1045-1058, 2017.
[34] J.-F. Hu, W.-S. Zheng, J. Pan, J. Lai, and J. Zhang, "Deep bilinear learning for rgb-d action recognition," in Proceedings of the European Conference on Computer Vision, 2018, pp. 5832-5841.
[35] P. Khaire, P. Kumar, and J. Imran, "Combining cnn streams of rgb-d and skeletal data for human activity recognition," Pattern Recognition Letters, vol. 115, pp. 107-116, 2018.
[36] S. Ardianto and H.-M. Hang, "Multi-view and multi-modal action recognition with learned fusion," in 2018 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), pp. 1601-1604, 2018.
[37] L. Wang, Y. Xiong, Z. Wang, Y. Qiao, D. Lin, X. Tang, and L. Van Gool, "Temporal segment networks: Towards good practices for deep action recognition," in Proceedings of the European Conference on Computer Vision, 2016, pp. 20-36.
[38] C. Wang, H. Yang, and C. Meinel, "Exploring multimodal video representation for action recognition,"in 2016 International Joint Conference on Neural Networks (IJCNN), pp. 1924-1931, 2016.
[39] E. Kazakos, A. Nagrani, A. Zisserman, and D. Damen, "Epic-fusion: Audiovisual temporal binding for egocentric action recognition," in Proceedings of the IEEE International Conference on Computer Vision, 2019, pp. 5492-5501.
[40] R. Gao, T.-H. Oh, K. Grauman, and L. Torresani, "Listen to look: Action recognition by previewing audio," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2020, pp. 10457-10467.
[41] N. Dawar and N. Kehtarnavaz, "A convolutional neural network-based sensor fusion system for monitoring transition movements in healthcare applications," in 2018 IEEE 14th International Conference on Control and Automation (ICCA), pp. 482-485, 2018.
[42] H. Wei, R. Jafari, and N. Kehtarnavaz, "Fusion of video and inertial sensing for deep learning–based human action recognition," Sensors, vol. 19, no. 17, 2019.
[43] A. Gorban, H. Idrees, Y.-G. Jiang, A. Roshan Zamir, I. Laptev, M. Shah, and R. Sukthankar, "THUMOS challenge: Action recognition with a large number of classes." http://www.thumos.info/, 2015.
[44] H. Akbari, L. Yuan, R. Qian, W.-H. Chuang, S.-F. Chang, Y. Cui, and B. Gong, "Vatt: Transformers for multimodal self-supervised learning from raw video, audio and text,"in Advances in Neural Information Processing Systems, vol. 27, 2014.
[45] N. C. Garcia, P. Morerio, and V. Murino, "Modality distillation with multiple stream networks for action recognition," in Proceedings of the European Conference on Computer Vision, 2018, pp. 5832-5841.
[46] N. C. Garcia, P. Morerio, and V. Murino, "Learning with privileged information via adversarial discriminative modality distillation," IEEE transactions on pattern analysis and machine intelligence, vol. 42, no. 10, pp. 2581-2593, 2019.
[47] N. C. Garcia, S. A. Bargal, V. Ablavsky, P. Morerio, V. Murino, and S. Sclaroff, "Dmcl: Distillation multiple choice learning for multimodal action recognition," arXiv preprint arXiv:1912.10982, 2019.
[48] B. Mahasseni and S. Todorovic, "Regularizing long short term memory with 3d human-skeleton sequences for action recognition," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 3054-3062.
[49] . Wang, C. Gao, L. Yang, Y. Zhao, W. Zuo, and D. Meng, "Pm-gans: Discriminative representation learning for action recognition using partial-modalities," in Proceedings of the European Conference on Computer Vision, 2018, pp. 384-401.
[50] Y. Liu, K. Wang, G. Li, and L. Lin, "Semantics-aware adaptive knowledge distillation for sensor-to-vision action recognition," IEEE Transactions on Image Processing, vol. 30, pp. 5573-5588, 2021.
[51] H. Alwassel, D. Mahajan, L. Torresani, B. Ghanem, and D. Tran, "Self supervised learning by cross-modal audio-video clustering," arXiv preprint arXiv:1911.12667, 2019.
[52] B. Korbar, D. Tran, and L. Torresani, "Cooperative learning of audio and video models from self-supervised synchronization," in Advances in Neural Information Processing Systems, vol. 31, 2018.
编辑:黄飞













 工商网监
工商网监
评论