 电子发烧友App
电子发烧友App


在我们日常的认识中,磁盘是非常可靠的。作者03年自己组装的电脑的磁盘现在还在用着,想想都快二十年了。很多人可能会想,消费级的磁盘都这么靠谱,那企业级的岂不是更加厉害。其实并非如此,其实磁盘是很容易出现故障的。
作者有幸参观过一个大型的数据中心,发现成堆的故障磁盘。据说,该数据中心每天有几十块磁盘出现故障。谷歌在设计其分布式文件系统GFS的时候,也是将磁盘作为非常不可靠部件进行考虑的,因此在其架构中通过多副本保证其可靠性。
想想其中的原因,大概是使用频度的差异造成的错觉吧。我们平时使用的磁盘平均下来每天应该不会超过一小时,而且大部分时间都没有数据读写。而数据中心磁盘则是7*24小时运行,且负载很重。试想,如果让你7*24小时不歇着,估计...
好了,废话少说。既然磁盘这么不靠谱,我们今天就给大家介绍一下存储领域保证磁盘可靠性的威廉希尔官方网站 。为了方便大家理解和日后学习,我们就以Linux内核为例进行介绍,其实威廉希尔官方网站 是相通的,大家可以迁移过去。在Linux操作系统下提升磁盘可靠性的威廉希尔官方网站 就是RAID威廉希尔官方网站 。具体实现有两种,一种是通过MD实现的多磁盘设备,另外一种是LVM。今天我们主要介绍一下通过MD实现的RAID威廉希尔官方网站 。
一、RAID的原理及基本操作
人类认识事物的客观规律是具体的比抽象的容易理解。因此,为了让大家更加容易理解本文介绍的内容,我们先从具体的内容开始。
1. RAID的基本原理
RAID的全称为廉价冗余磁盘阵列(Redundant Array of Inexpensive Disks),从字面可以看出其基本原理就是通过廉价的磁盘组成一组磁盘,从而提高磁盘的整体可靠性。在Linux操作系统层面,其实就是将物理磁盘通过软件抽象为逻辑磁盘。以RAID1(两块磁盘存储相同的数据,在出现一块磁盘故障的情况下,数据不丢失)为例,通过Linux内核中的软件创建一个虚拟的块设备,而该块设备中记录了底层对应的物理设备及相关参数。
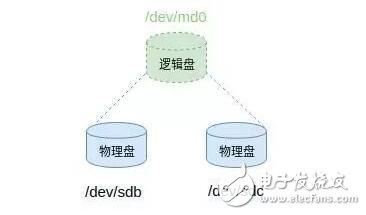
图1 RAID示意图
因此,从用户层面来看就是一块普通的磁盘设备,而在底层却是2个独立的物理硬盘。当用户向逻辑磁盘写数据的时候,其中的软件会通过参数进行计算,并将数据重新定向到底层的物理设备。通过这种方法可以保证即使出现某个物理磁盘损坏,用户的数据仍然完好无损。
2. Linux下RAID管理
在Linux操作系统下可以通过mdadm工具非常方便的创建RAID。我们以RAID1为例演示一下如何创建。可能很多同学没有多块物理磁盘,其实没有关系,我们可以通过虚拟机创建虚拟磁盘或者loop设备interwetten与威廉的赔率体系 的方式创建RAID。
为了方便大家练习,本文就通过loop设备模拟磁盘来创建RAID。首先需要创建2个loop设备。具体执行如下命令:
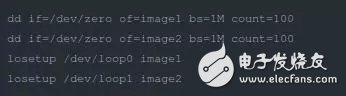
图2 创建loop设备
成功运行上述命令后,在/dev目录下就多出2个设备,分别是loop0和loop1。我们可以将这两个设备当做磁盘来使用。下面我们就可以创建RAID了,非常简单,通过一条命令就可以了。
mdadm --create /dev/md1 --level=1 --raid-devices=2 /de
在上面命令中/dev/md1表示创建的新设备的名称,level=1表示是RAID1,后面分别是物理设备的数量和具体的物理设备路径。
除了创建RAID之外,mdadm还支持很多功能,比如获取RAID的详细信息(mdadm --detail /dev/md1)。
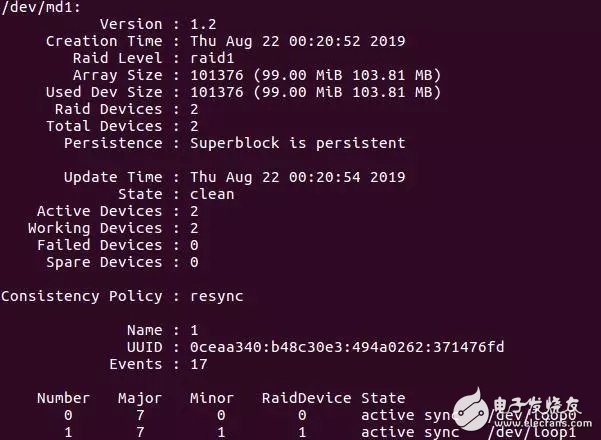
图3 RAID的详细信息
该命令的功能很多,我们就不一一介绍了。这里只是抛砖引玉,具体内容大家自行学习就行。后面我们重点从原理和实现层面介绍一下Linux的RAID威廉希尔官方网站 。
3. RAID软件架构
Linux的RAID实现在用户态和内核态都有涉及。其中用户态主要进行RAID的管理,而内核态一方面配合用户态进行RAID管理,另外一方面则实现对IO的处理,这部分才是RAID最为核心的内容。
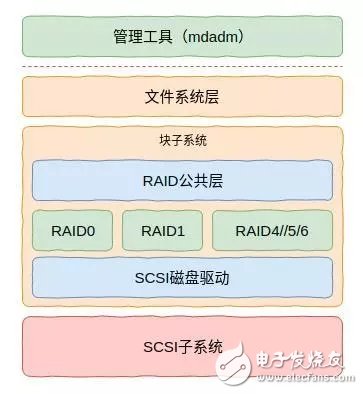
图4 软件架构
对于基于SCSI物理磁盘的RAID来说,Linux环境下整个软件架构如图4所示。其中虚线以上的为用户态的软件模块,虚线以下的为内核态的软件模块。这里比较核心的是RAID公共层,在这里主要创建md设备,该设备是一个逻辑设备,也是用户可以看到的RAID设备。其下则是具体的RAID模块,用于实现不同的RAID级别(算法)。
再往下就是通用SCSI驱动层了,也就是图中的SCSI磁盘驱动这一层的内容。该层其实是SCSI系统的上层驱动(SCSI子系统分为上中下三层)。RAID模块通过调用该层的数据访问接口就可以实现物理磁盘数据读写了。
这里需要说明的是,这里的物理磁盘并不一定是本地磁盘。由于基于SAN或者其它协议的磁盘可以通过光纤或者SAS线连接到主机,并呈现为物理硬盘。这种物理硬盘与本地物理硬盘没有任何差异。
二、RAID的代码浅析
针对Linux内核的具体实现,我们简单介绍一下其中的代码。关于代码部分我们以RAID1为例介绍两部分的内容,一部分是关于创建RAID的逻辑;另一部分是请求处理逻辑。理解了上述内容,也就理解了关于RAID代码逻辑的大部分内容。
1. 关于RAID的超级块
接触过Linux文件系统的同学应该对超级块不会陌生。在RAID中也有超级块(superblock),并且作用与文件系统类似。RAID超级块的作用类似,可以将超级块理解称为RAID的地图。RAID软件对底层物理磁盘的一切操作都以该超级块为依据。
Linux的RAID有多个版本,包括0.9、1.0、1.1和1.2四个版本,且版本之间并不能保证兼容性。对于1.2版本的RAID,其超级块位于开始4KB偏移的位置。我们可以通过dd或者其它工具将该数据导出到文件中,并通过二进制工具查看。
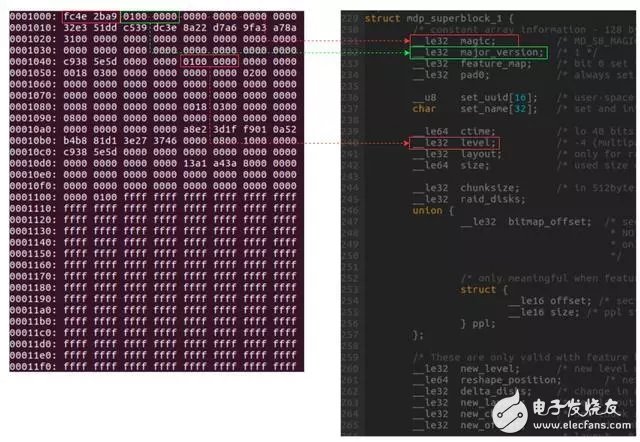
图5 RAID的超级块
如图5是作者导出的上面创建的RAID1的超级块信息及数据结构(mdp_superblock_1)对比图。如果看不清楚也没关系,大家可以自行获取上述进行,并对比。
RAID的超级块内容非常多,在本文不可能一一介绍。这里大家只要知道这里面包含创建时间、RAID级别、设备大小及同步信息等内容即可。后续我们可能会专门介绍超级块中每个成员的具体作用。
2. 创建RAID核心流程
创建RAID的流程是由用户态触发,内核态具体完成的。RAID的创建核心分为3个步骤,具体如下:
用户态工具mdadm根据参数构建超级块,并写入物理设备
用户态工具触发创建md设备(RAID设备)
用户态工具触发内核,是RAID处于运行状态
其中第一步我们不再解释,原理很简单,大家自行阅读代码即可。关于第二步,用户态工具(mdadm)通过向/sys/module/md_mod/parameters/new_array中写入一个名为md*的字符串来触发内核创建md设备。
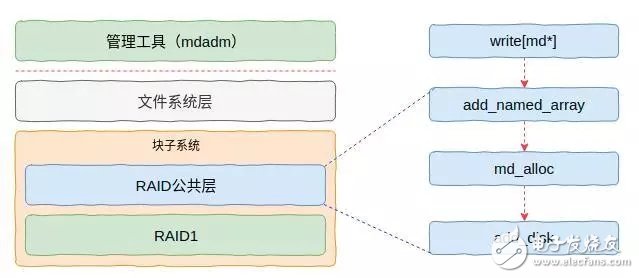
图6 RAID创建流程
这里的核心是分配一个关于md设备的数据结构(mddev),并且调用通用块层的接口创建一个通用块设备并添加(add_disk)到系统。成功之后,我们就可以在/dev目录下看到我们想创建的md设备了,设备名称就是mdadm传入的参数。这里面需要重点关注的是,在分配md设备的数据结构的时候会关联一个名为md_make_request的函数,该函数就是RAID的IO处理函数。
此时已经可以看到设备,但是还不能使用,因为RAID设备还没有与底层的物理设备关联起来。因此,后续mdadm工具会通过系统调用触发内核启动RAID,具体流程如图7所示。
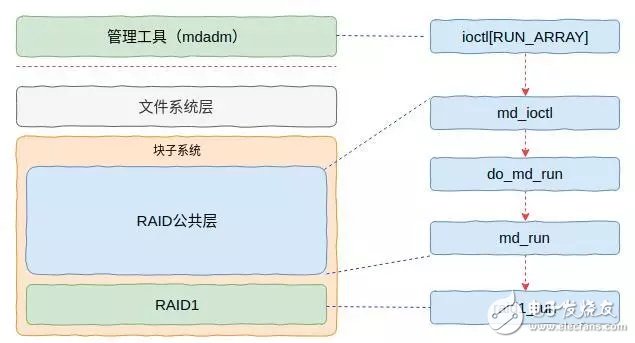
图7 RAID启动流程
此时,内核会根据超级块信息执行若干动作,并且更改其中某些状态标记。成功之后RAID设备就可以使用了。关于细节我们这里不做介绍,介绍了大家也记不住,有兴趣的同学可以自行阅读代码。
3. 读写请求核心流程
前文我们知道创建RAID其实是创建了一个通用块设备,并注册了请求处理函数(md_make_request)。当在用户态通过文件系统接口访问该块设备(RAID)时,虚拟文件系统会调用该函数(请参考本号之前关于SCSI磁盘的文章)。因此,关于RAID的读写流程,我们就从该函数开始介绍,下面先看一下整体流程。
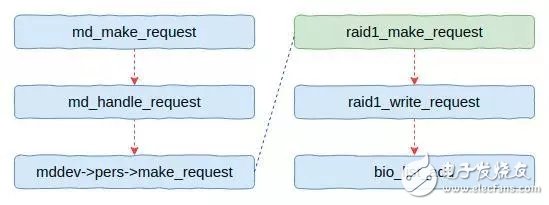
图8 读写流程
从图8可以看出整个流程还是比较简单的。在公共层会根据参数调用个性层的接口,对于RAID1来说就是调用raid1_make_request函数。该函数中会根据请求类型出现不同的分支,上图是写数据的流程。
RAID1本身比较简单(请求分别放入底层物理磁盘),IO经过简单处理后会放入一个队列中。然后唤醒守护线程刷写队列。

















 工商网监
工商网监
评论