分布式机器学习平台的实现方法
本文选自纽约州里大学计算机系教授Murat和学生的论文,主要介绍了分布式机器学习平台的实现方法并提出了未来的研究方向。
论文地址:www.cse.buffalo.edu/~demirbas/publications/DistMLplat.pdf
机器学习特别是深度学习为语音识别、图像识别、自然语言处理、推荐系统和搜索引擎等领域带来的革命性的突破。这些威廉希尔官方网站 将会广泛用于自动驾驶、医疗健康系统、客户关系管理、广告、物联网等场景。在资本的驱动下机器学习的发展十分迅速,近年来我们看到了各个公司和研究机构纷纷推出了自己的机器学习平台。
由于需要训练的数据集合模型十分巨大,机器学习平台通常采用分布式的架构来实现,会采用成百上千的机器来训练模型。在不远的未来,涉及机器学习的计算将会成为数据中心的主要任务。
由于作者分布式系统的专业背景,本文从分布式系统的角度来研究这些机器学习平台,并分析他们在通信和控制方面的瓶颈。同时我们还研究并比较了这些平台的容错性以及编程实现的难易程度。
根据实现原理和架构的不同,我们将分布式机器学习平台分为三种不同的基本类型:
基础数据流模式
参数服务器模型
先进的数据流模式
对于三种主流的实现方式做了简短的介绍,分别利用Spark、PMLS和Tensorflow(MXNet)来对三种类型进行解读。我们对不同的平台进行了比较,详细的结果见论文。
在文章的最后我们总结了分布式机器学习平台并对未来给出了一些建议,如果你很熟悉机分布式器学习平台的话可以跳过这部分。
Spark
在Spark里计算通过有向无环图来建模,其中每一个顶点代表一个弹性分布式数据集(Resilient Distributed Dataset, RDD) ,而每条边表示一种对于RDD的操作。RDD是一组分配在不同逻辑分区里的对象,这些逻辑分区直接在内存里储存并处理,当内存空间不够的时候,部分分区会被存放在硬盘上,需要的时候再和内存里的分区替换位置。
在有向无环图中,从A定点指向B定点的E边表示RDD A 通过E操作得到了RDD B。其中包含两类操作:转换类和动作类。转换类操作意味着会产生新的RDD。
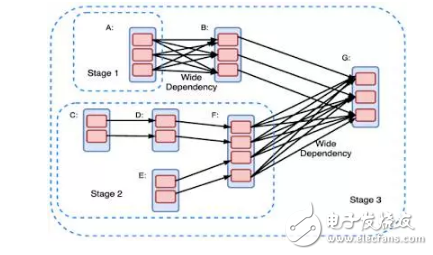
Spark的用户通过建立对有向无环图上RDD的转换或者运行操作来实现计算。有向无环图被编译为一个个不同的级别,每一个级别包含一系列可以并行计算的任务(每个分区中一个任务)。任务间较弱的依赖性有利于高效的执行,而较强的依赖性则会因为大量的通信造成性能的严重下降。
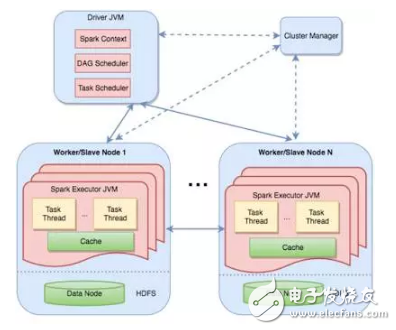
Spark通过将这些有向无环图分级分配到不同的机器上来实现分布式计算,上图显示了主节点的清晰的工作架构。驱动包含两个部分的调度器单元,DAG调度器和任务调度器,同时运行和协调不同机器间的工作。
Spark的设计初衷是用于通用的数据处理,并没有针对机器学习的特殊设计。但是在MKlib工具包的帮助下,也能在Spark上实现机器学习。通常来说,Spark将模型参数存储于驱动节点上,每一个机器在完成迭代之后都会与驱动节点通信更新参数。对于大规模的应用来说,模型参数可能会存在一个RDD上。由于每次迭代后都会引入新的RDD来存储和更新参数,这会引入很多额外的负载。更新模型将会在机器和磁盘上引入数据的洗牌操作,这限制了Spark的大规模应用。这是基础数据流模型的缺陷,Spark对于机器学习的迭代操作并没有很好的支持。
PMLS
PMLS是为机器学习量身打造的平台,通过引入了参数服务器抽象概念来处理机器学习训练过程中频繁的迭代。
非常好我支持^.^
(0) 0%
不好我反对
(0) 0%