最先进的人工智能模型在不到五年的时间内经历了超过 5,000 倍的规模扩展。这些 AI 模型严重依赖复杂的计算和大量内存来实现高性能深度神经网络 (DNN)。只有使用 CPU、GPU 或专用芯片等大型计算节点集群才能训练具有大量数据的如此庞大的 DNN。
SmartNIC 已成为现代网络基础设施中的关键组件,专门设计用于增强网络性能、减少延迟并提高整体系统效率。SmartNIC是智能网络接口卡的缩写,可以从主机CPU卸载与网络相关的任务,从而为其他关键操作释放宝贵的处理能力。
在高性能计算 (HPC) 领域,智能网卡获得了巨大的吸引力。HPC 环境需要高处理能力、高效的数据移动和高速互连,以实现最高性能。SmartNIC 通过提供高级网络功能以及专门的硬件加速,在 HPC 应用中表现出色。
提高人工智能系统的效率
当前的机器学习趋势涉及分布式学习,它通常采用并行数据训练,其中每个节点在不同的数据子集上训练模型。从这些节点获得的权重梯度会定期组合并用于更新模型权重。
为了在分布式系统上有效地扩展 AI 训练,主要目标是在处理计算密集型张量操作时优化计算节点的使用。最近研究[1]的一个潜在解决方案涉及将全部减少的操作从计算节点转移到专门为AI设计的专用网络接口卡(NIC)。该 NIC 在现场可编程门阵列 (FPGA) 上实现,使 CPU 和 NPU 能够专注于深度学习和 AI 计算所必需的张量相关任务。因此,智能网卡通过处理网络操作来提高整个系统的效率。
随着SmartNIC威廉希尔官方网站
的不断发展,各种行业参与者积极提出先进的解决方案,以满足云和企业架构不断变化的需求。这些解决方案旨在将网络和安全加速功能融合到一个平台中,从而提高系统的性能和效率。其中一个例子是AMD的Alveo U25N,这是一个25GbE SmartNIC平台,专为构建现代数据中心的云和企业架构师而设计,具有超高吞吐量,小数据包性能和低延迟以及可编程网络结构。
除了减轻处理器的负担外,SmartNIC FPGA 还具有可定制性和易于编程的特点。这种灵活性使开发人员能够根据 AI 和深度学习工作负载的特定需求定制智能网卡的功能。
用于 AI 的基于 FPGA 的智能网卡的操作
深度神经网络的监督训练涉及几个步骤。在第一步(称为前向传递)中,DNN 预测小批量输入的输出,并计算与真实标签相比的误差。接下来,在向后传递中,误差通过各层传播以计算权重梯度(计算信息)。最后,使用梯度和优化器规则更新权重,以最小化预测误差。对多个小批量(一个纪元)重复此过程,直到精度收敛。
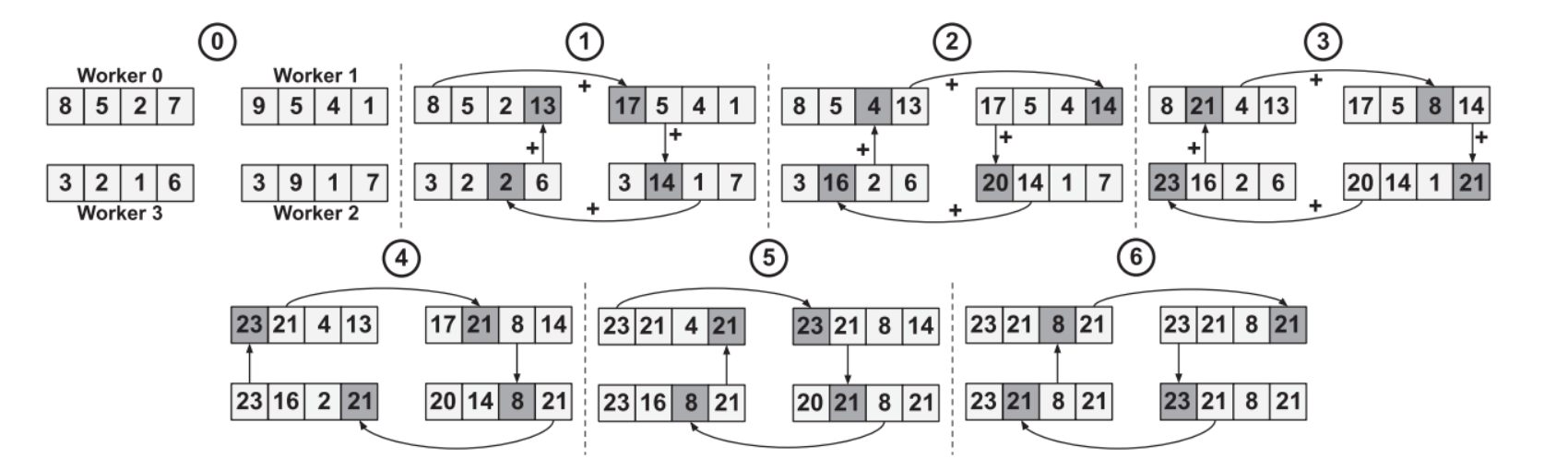
图 1:带有四个工人的流水线环全归化。(来源:“用于可扩展分布式AI培训系统的基于FPGA的AI智能NIC”,载于IEEE Computer Architecture Letters)
为了有效地训练大型 DNN,使用了分布式训练系统。这些系统雇用多个工作器,可以是 CPU、GPU 或专用加速器。这项工作中选择的方法是数据并行。每个工作线程使用不同的小批量训练模型。他们定期交换他们学到的信息,即通过全归约操作的重量梯度。
约简运算可以是关联的和可交换的,例如总和、最小值或最大值。all-reduce 操作是许多并行算法(如分布式排序、矩阵乘法和机器学习)的基本构建块。
All-Reduce算法广泛用于并行计算,将来自多个进程或工作器的数据合并到一个统一和整合的阵列中。worker 表示负责在 SmartNIC 架构中执行特定任务或操作的计算组件或实体。这些工作线程包括 CPU 内核、GPU 或其他专门分配用于处理网络、卸载和加速功能的处理单元。
Understanding the system and architecture of AI SmartNICs
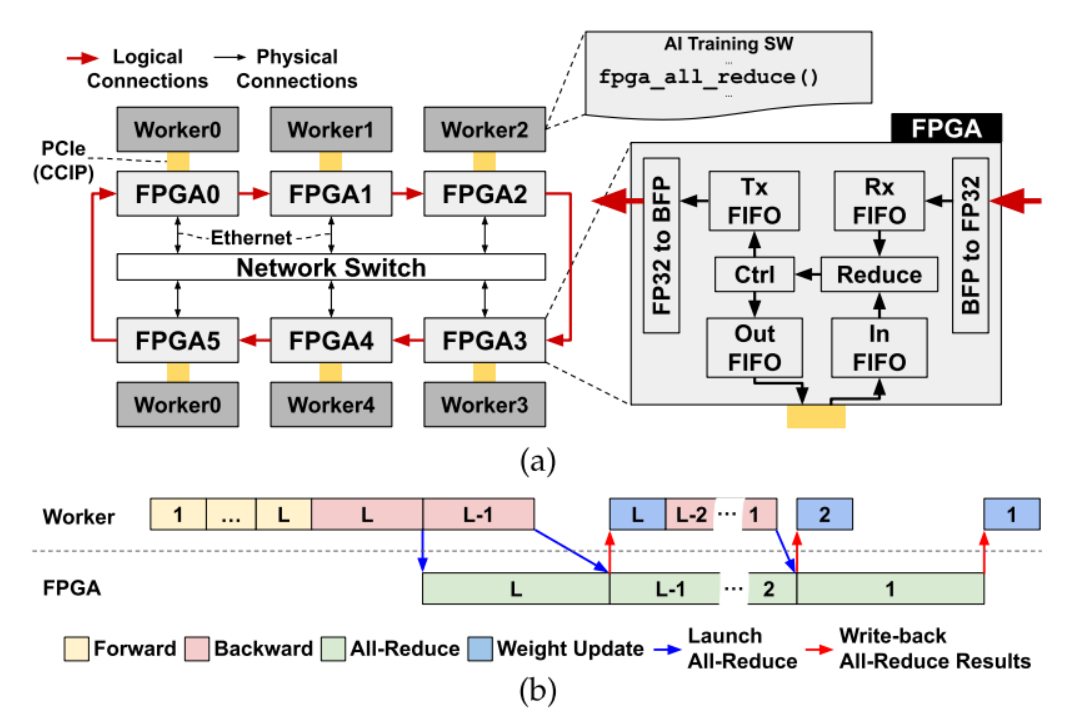
图 2:(a) 系统概述和 AI 智能 NIC 架构,以及 (b) L 层 MLP 训练的示例执行跟踪。(来源,“用于可扩展分布式AI培训系统的基于FPGA的AI智能NIC”,载于IEEE Computer Architecture Letters)
图 2 显示了一个配备 AI SmartNIC 的系统,其中每个工作器都通过 PCIe 连接到 FPGA,所有 FPGA 都通过网络交换机互连。FPGA 以以太网层顶部的环形拓扑结构排列。
FPGA 从本地工作器读取权重梯度,并将其存储在输入 FIFO 中。同时,来自前一个节点的归约操作数通过以太网接收,并在接收 (Rx) FIFO 中缓冲。一旦两个FIFO都准备就绪,它们的内容就会被取消排队并使用FP32加法器减少。然后,结果通过传输 (Tx) FIFO 发送到环中的下一个节点,或通过输出 FIFO 作为最终的全归约结果写回本地工作线程内存。
基于 FPGA 的以 GPU 为中心的智能网卡
基于 FPGA 的网络接口卡 (FpgaNIC) [2] 旨在将 GPU 的角色从工作组件转变为网络数据处理的主要组件。在传统的网络架构中,GPU 通常充当工作线程,而 CPU 承担主要组件角色,考虑到 GPU 消耗的网络流量最多,这是不合理的。FpgaNIC重新引入了GPU作为主要组件,同时为围绕SmartNIC的设计空间探索带来了灵活性。此 SmartNIC 的主要功能之一是它能够利用 GPU 虚拟地址,从而实现与本地 GPU 的高效直接通信。通过利用 GPU 虚拟地址,SmartNIC 可以绕过不必要的数据传输,实现与 GPU 更快、更简化的通信。智能网卡和本地 GPU 之间的这种直接通信可提高整体系统性能并减少延迟。
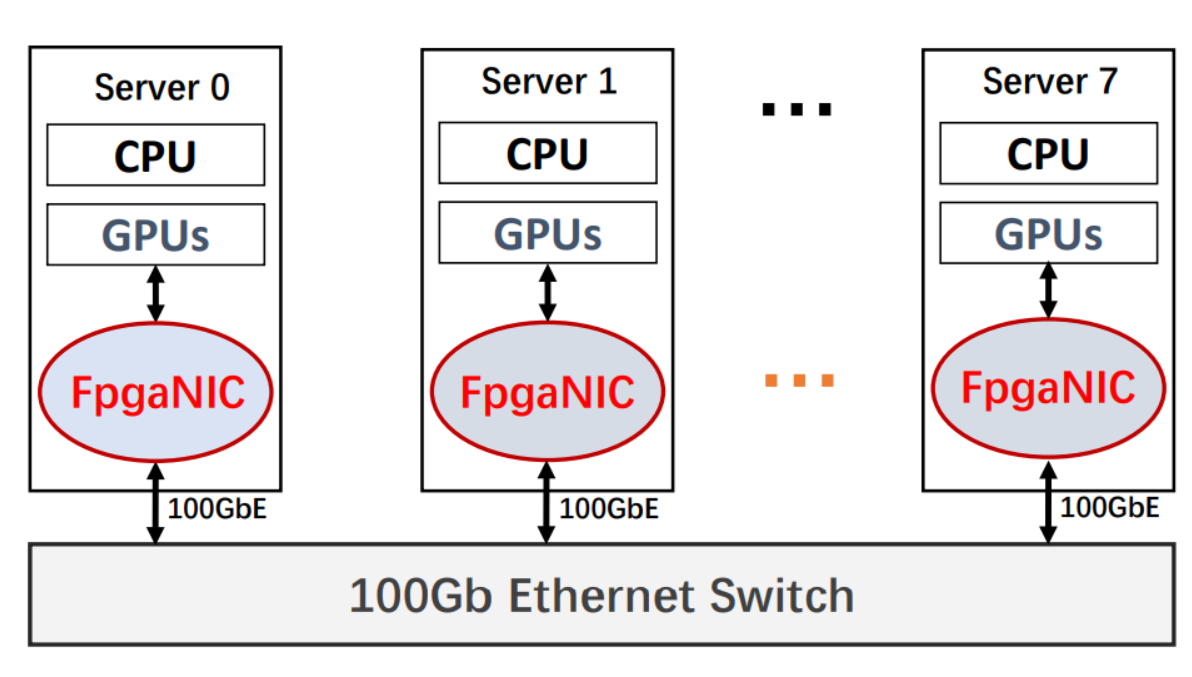
图 3:实验设置。(资料来源:“FpgaNIC:一款基于 FPGA 的多功能 100Gb SmartNIC for GPU”,2022 年 USENIX 年度威廉希尔官方网站
会议。
该智能网卡利用现场可编程门阵列,通过 PCIe 实现智能网卡和本地 GPU 之间的直接点对点 (P2P) 通信。FpgaNIC的另一个特点是它提供100Gb硬件网络传输能力。这意味着它可以与远程GPU建立高速网络通信,从而实现分布式系统的高效数据传输和协作。智能网卡充当本地 GPU 和远程 GPU 之间的桥梁,促进它们之间的无缝快速通信。
近年来,基于当前围绕SmartNIC的行业研究和开发,已经有许多实施。其中之一是Orthogone和Napatech的合作,旨在开发一个基于FPGA的SmartNIC平台,专门设计用于高频交易应用。
这种战略合作伙伴关系将Orthogone的超低延迟(ULL)FPGAIP内核和FPGA开发环境与Napatech的可编程SmartNIC相结合,以提供高效的性能和超低延迟的交易数据处理。此次合作旨在通过实现灵活的集成、交钥匙部署选项和未来的硬件适应性,满足贸易公司和投资银行等金融科技企业的苛刻要求。
Achronix Semiconductor最近宣布,其Achronix网络基础设施代码(ANIC)现在包括400千兆以太网(GbE)连接,以及PCIe Gen 5.0网络性能。凭借 400 GbE 支持,ANIC IP 可实现超快的数据传输速率,使组织能够实时处理大量数据。这种加速的网络吞吐量可最大限度地提高应用程序性能并显著减少延迟。模块化架构使客户能够选择其应用所需的 SmartNIC 组件,每个优化的 IP 模块都经过闭合时序预验证,以加快设计速度。结合部分重新配置(在IP设计中动态更改模块功能的能力),可以在现场无缝修改解决方案。
随着对高速数据处理的需求继续呈指数级增长,SmartNIC 威廉希尔官方网站
为人工智能训练和云计算的网络和数据处理的重大进步铺平了道路。事实证明,这些专用网络接口卡有助于克服现代计算的挑战,实现高效的数据卸载、关键任务的加速以及与现有基础设施的无缝集成。随着研究和开发的不断深入,我们可以期待SmartNIC威廉希尔官方网站
的进一步创新,释放新的可能性,并推动网络和数据驱动应用的下一波进步。
引用
[1] R. Ma, E. Georganas, A. Heinecke, S. Gribok, A. Boutros 和 E. Nurvitadhi, “用于可扩展分布式 AI 训练系统的基于 FPGA 的 AI 智能 NIC”,载于 IEEE Computer Architecture Letters,第 21 卷,第 2 期,第 49-52 页,1 月至 2022 月。10, doi: 1109.2022/LCA.3189207.<>
[2] 王泽科1, 黄洪静1, 张杰1, 吴飞1,2 1 浙江大学人工智能协同创新中心 2 浙江大学上海高等研究院 古斯塔沃·阿隆索系统集团,瑞士苏黎世联邦理工学院计算机科学系。
 /6
/6 



 工商网监
湘ICP备2023018690号
工商网监
湘ICP备2023018690号






 976
976


 淘帖
淘帖



