计算机中内存、cache和寄存器之间的关系
寄存器(Cache)是CPU内部集成的,内存是挂在CPU外面的数据总线上的,访问内存时要在CPU的寄存器(Cache)填上地址,再执行相应的汇编指令,这时CPU会在数据总线上生成读取或写入内存数据的时钟信号,最终内存的内容会被CPU寄存器(Cache)的内容更新(写入)或者被读入CPU的寄存器(Cache)(读取)。如图:
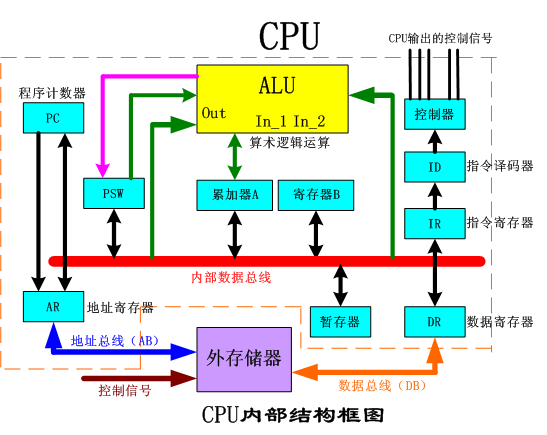
CPU、内存、寄存器之间的关系cpu 取址 -》地址输入地址寄存器 -》 缓存命中即,则数据进入数据寄存器 -》 缓存未命中则进入内存 -》 内存TLB快表命中则数据块进入缓存,数据进入寄存器 -》 内存TLB快表未命中则局部数据块进入缓存和快表 -》 内存未命中则进入硬盘虚拟存储区
CPU里的寄存器
其实就是我们常说的:Cache,有1级 和 2级,(L1,L2)L1容量比较小,L2(集成在主板上,说使用的为静态RAM)会多一些,L1是集成在CPU内部的寄存器(L1与CPU 同步),访问它速度自然很快,但容量比较小,L1 64K L2现在最高的就2MB,这显然是不够的,所以我们都需要扩展它,内存(DDR RAM)就是扩展的“寄存器”,它的访问速度就比 Cache 速度慢!CPU 在运行某计算时,它会把使用频率高的数据放到L1,L2,把不常用的数据保存在RAM中,需要访问的时候再读入Cache,当然相比之下硬盘的速度就更低。
计算机中内存、cache和寄存器之间的关系
寄存器是中央处理器内的组成部份。寄存器是有限存贮容量的高速存贮部件,它们可用来暂存指令、数据和位址。在中央处理器的控制部件中,包含的寄存器有指令寄存器(IR)和程序计数器(PC)。在中央处理器的算术及逻辑部件中,包含的寄存器有累加器(ACC)。
内存包含的范围非常广,一般分为只读存储器(ROM)、随机存储器(RAM)和高速缓存存储器(cache)。
寄存器是CPU内部的元件,寄存器拥有非常高的读写速度,所以在寄存器之间的数据传送非常快。
Cache :即高速缓冲存储器,是位于CPU与主内存间的一种容量较小但速度很高的存储器。由于CPU的速度远高于主内存,CPU直接从内存中存取数据要等待一定时间周期,Cache中保存着CPU刚用过或循环使用的一部分数据,当CPU再次使用该部分数据时可从Cache中直接调用,这样就减少了CPU的等待时间,提高了系统的效率。Cache又分为一级Cache(L1
Cache)和二级Cache(L2 Cache),L1 Cache集成在CPU内部,L2 Cache早期一般是焊在主板上,现在也都集成在CPU内部,常见的容量有256KB或512KB L2 Cache。
总结:大致来说数据是通过内存-Cache-寄存器,Cache缓存则是为了弥补CPU与内存之间运算速度的差异而设置的的部件。
首先看一下计算机的存储体系(Memory hierarchy)金字塔:
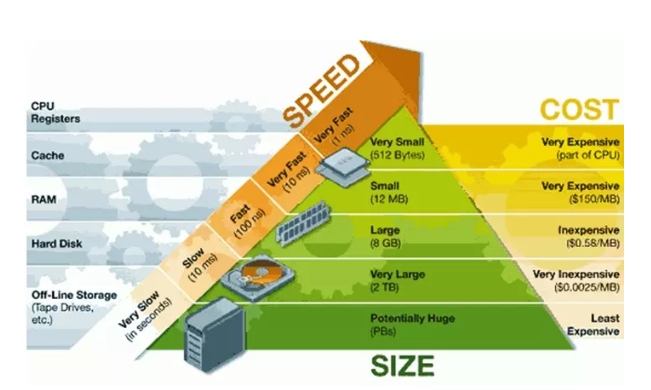
其次我们看看一个计算机的存储体系
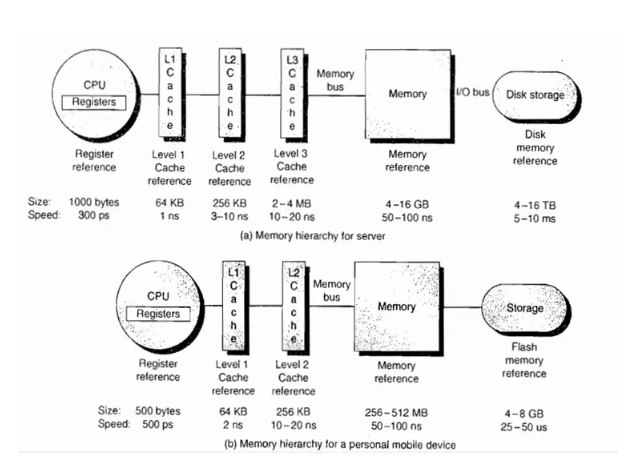
Register
寄存器是CPU的内部组成单元,是CPU运算时取指令和数据的地方,速度很快,寄存器可以用来暂存指令、数据和地址。在CPU中,通常有通用寄存器,如指令寄存器IR;特殊功能寄存器,如程序计数器PC、sp等。
Cache
缓存即就是用于暂时存放内存中的数据,若果寄存器要取内存中的一部分数据时,可直接从缓存中取到,这样可以调高速度。高速缓存是内存的部分拷贝。
CPU 《--- 》 寄存器《--- 》 缓存《--- 》内存
寄存器的工作方式很简单,只有两步:(1)找到相关的位,(2)读取这些位。
内存的工作方式就要复杂得多:
(1)找到数据的指针。(指针可能存放在寄存器内,所以这一步就已经包括寄存器的全部工作了。)
(2)将指针送往内存管理单元(MMU),由MMU将虚拟的内存地址翻译成实际的物理地址。
(3)将物理地址送往内存控制器(memory controller),由内存控制器找出该地址在哪一根内存插槽(bank)上。
(4)确定数据在哪一个内存块(chunk)上,从该块读取数据。
(5)数据先送回内存控制器,再送回CPU,然后开始使用。
内存的工作流程比寄存器多出许多步。每一步都会产生延迟,累积起来就使得内存比寄存器慢得多。
为了缓解寄存器与内存之间的巨大速度差异,硬件设计师做出了许多努力,包括在CPU内部设置缓存、优化CPU工作方式,尽量一次性从内存读取指令所要用到的全部数据等等。
RAM-memory
即内存,是用于存放数据的单元。其作用是用于暂时存放CPU中的运算数据,以及与硬盘等外部存储器交换的数据。
HardDisk
硬盘
一条汇编指令大概执行过程是(不是绝对的,不同平台有差异):
取指(取指令)、译码(把指令转换成微指令)、取数(读内存里的操作数)、计算(各种计算的过程,ALU负责)、写回(将计算结果写回内存),有些平台里,前两步会合并成一步,某些指令也不会有取数或者回写的过程。
再提一下CPU主频的概念:首先,主频绝对不等于一秒钟可以执行的指令个数,每个指令的执行成本是不同的,比如x86平台里汇编指令INC就比ADD要快,具体每个指令的时钟周期可以参考intel的手册。
为什么要提主频?因为上面的执行过程中,每个操作都需要占用一个时钟周期,对于一个操作内存的加法,就需要5个时钟周期,换句话说,500Mhz主频的CPU,最多执行100MHz条指令。
仔细观察,上面的步骤里不包括寄存器操作,对于CPU来说读/写寄存器是不需要时间的,或者说如果只是操作寄存器(比如类似mov BX,AX之类的操作),那么一秒钟执行的指令个数理论上说就等于主频,因为寄存器是CPU的一部分。
然后寄存器往下就是各级的cache,有L1 cache,L2,甚至有L3的,以及TLB这些(TLB也可以认为是cache),之后就是内存,前面说寄存器快,现在说为什么这些慢:
对于各级的cache,访问速度是不同的,理论上说L1cache(一级缓存)有着跟CPU寄存器相同的速度,但L1cache有一个问题,当需要同步cache和内存之间的内容时,需要锁住cache的某一块(术语是cache line),然后再进行cache或者内存内容的更新,这段期间这个cache块是不能被访问的,所以L1cache的速度就没寄存器快,因为它会频繁的有一段时间不可用。
L1 cache下面是L2 cache,甚至L3 cache,这些都有跟L1 cache一样的问题,要加锁,同步,并且L2比L1慢,L3比L2慢,这样速度也就更低了。
最后说说内存,内存的主频现在主流是1333左右吧?或者1600,单位是MHz,这比CPU的速度要低的多,所以内存的速度起点就更低,然后内存跟CPU之间通信也不是想要什么就要什么的。
内存不仅仅要跟CPU通信,还要通过DMA控制器与其它硬件通信,CPU要发起一次内存请求,先要给一个信号说“我要访问数据了,你忙不忙?”如果此时内存忙,则通信需要等待,不忙的时候,通信才能正常。并且,这个请求信号的时间代价,就是够执行几个汇编指令了,所以,这是内存慢的一个原因。
另一个原因是:内存跟CPU之间通信的通道也是有限的,就是所谓的“总线带宽”,但,要记住这个带宽不仅仅是留给内存的,还包括显存之类的各种通信都要走这条路,并且由于路是共享的,所以任何请求发起之间都要先抢占,抢占带宽需要时间,带宽不够等待的话也需要时间。
以上两条加起来导致了CPU访问内存更慢,比cache还慢。
举个更容易懂的例子:
CPU要取寄存器AX的值,只需要一步:把AX给我拿来,AX就拿来了。
CPU要取L1 cache的某个值,需要1-3步(或者更多):把某某cache行锁住,把某个数据拿来,解锁,如果没锁住就慢了。
CPU要取L2 cache的某个值,先要到L1 cache里取,L1说,我没有,在L2里,L2开始加锁,加锁以后,把L2里的数据复制到L1,再执行读L1的过程,上面的3步,再解锁。
CPU取L3 cache的也是一样,只不过先由L3复制到L2,从L2复制到L1,从L1到CPU。
CPU取内存则最复杂:通知内存控制器占用总线带宽,通知内存加锁,发起内存读请求,等待回应,回应数据保存到L3(如果没有就到L2),再从L3/2到L1,再从L1到CPU,之后解除总线锁定。
非常好我支持^.^
(6) 100%
不好我反对
(0) 0%
相关阅读:
- [电子说] 学习STM32F103的ADC功能 2023-10-24
- [编程语言及工具] 常用于缓存处理的机制总结 如何避免缓存雪崩问题? 2023-10-24
- [电子说] 学习STM32F103的DAC功能 2023-10-24
- [电子说] 学习STM32F103的定时器功能 2023-10-24
- [电子说] STM32基础知识:定时器的PWM输出功能 2023-10-24
- [电子说] 既然ODR能控制管脚高低电平,为什么还需要BSRR寄存器呢? 2023-10-24
- [电子说] ARM系列-P Channel简析 2023-10-24
- [控制/MCU] 基于STM32F429芯片的单片机芯片内存映射图 2023-10-23
( 发表人:李倩 )