cache基本知识培训教程[2]
cache基本知识培训教程[2]
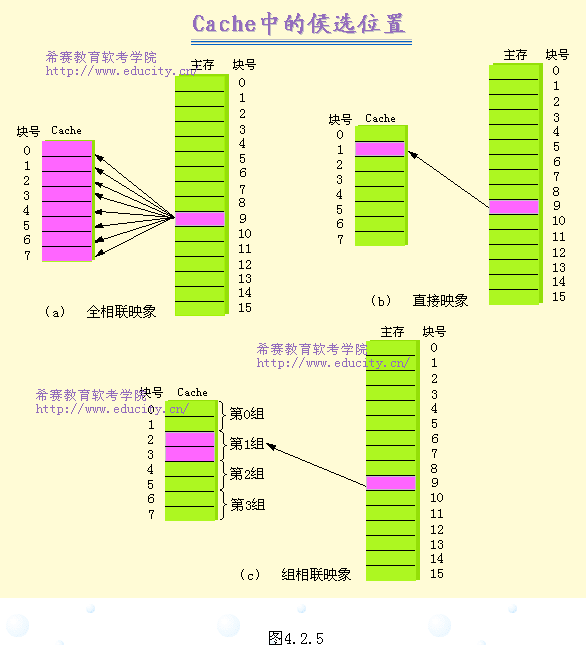
相联度越高(即 n 的值越大), Cache 空间的利用率就越高,块冲突概率就越低,因而 Cache 的失效率就越低。块冲突是指一个主存块要进入已被占用的 Cache 块位置。显然,全相联的失效率最低,直接映象的失效率最高。虽然从降低失效率的角度来看, n 的值越大越好,但在后面我们将看到,增大 n 值并不一定能使整个计算机系统的性能提高,而且还会使 Cache 的实现复杂度和代价增大。因此,绝大多数计算机都采用直接映象、两路组相联或四路组相联。特别是直接映像,采用得最多。
4.2.2查找方法
当CPU访问Cache时,如何确定Cache中是否有所要访问的块?若有的话,如何确定其位置?这是通过查找目录表来实现的。Cache中设有一个目录表,该表所包含的项数与Cache的块数相同,每一项对应于Cache中的一个块。当一个主存块被调入Cache中某一个块位置时,它的标识就被填入目录表中与该Cache块相对应的项中,并且该项的有效位被置“1”。
 根据映象规则不同,一个主存块可能映象到Cache中的一个或多个Cache块位置。为便于讨论,我们把它们称为候选位置。当CPU访问该主存块时,必须且只需查找它的候选位置所对应的目录表项(标识)。如果有与所访问的主存块相同的标识,且其有效位为“1”,则它所对应的Cache块即是所要找的块。为了保证速度,对各候选位置的标识的检查比较应并行进行。
根据映象规则不同,一个主存块可能映象到Cache中的一个或多个Cache块位置。为便于讨论,我们把它们称为候选位置。当CPU访问该主存块时,必须且只需查找它的候选位置所对应的目录表项(标识)。如果有与所访问的主存块相同的标识,且其有效位为“1”,则它所对应的Cache块即是所要找的块。为了保证速度,对各候选位置的标识的检查比较应并行进行。
 并行查找的实现方法有两种:
并行查找的实现方法有两种:
(1) 用相联存储器实现;
(2) 用单体多字存储器和比较器来实现。
图4.2.6中画出了用第二种方法来实现4路组相联的情况。
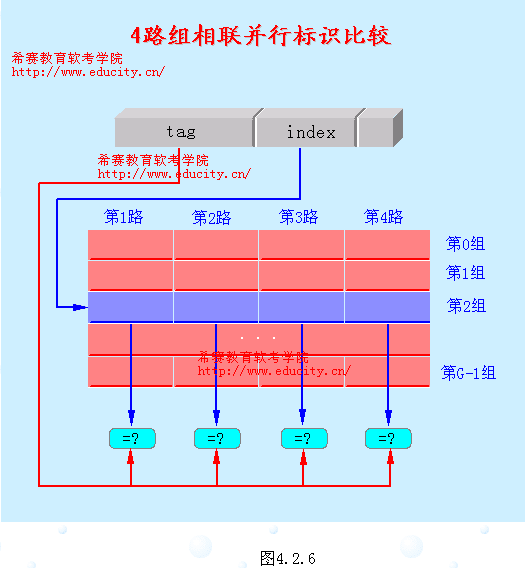
由图中可以看出,n 越大,实现查找的机制就越复杂,代价就越高。直接映象 Cache 的查找最简单:只需查找一个位置。所访问的块要么就在这个位置上,要么就不在 Cache 中。
4.2.3替换算法
由于主存中的块比 Cache 中的块多,所以当要从主存调入一个块到 Cache 中时,会出现该块所映象到的一组(或一个) Cache 块已全被占用的情况。这时,需强迫腾出其中的某一块,以接纳新调入的块。那么应该替换哪一块呢? 这就是替换算法所要解决的问题。直接映象 Cache 中的替换很简单,因为只有一个块,别无选择。而在组相联和全相联 Cache 中,则有多个块供选择,我们当然希望应尽可能避免替换掉马上就要用到的信息。主要的替换算法有以下三种。
1. 随机法
为了均匀使用一组中的各块,这种方法随机地选择被替换的块。有些系统采用伪随机数法产生块号,以使行为可再现。这对于调试硬件是很有用的。这种方法的优点是简单、易于用硬件实现,但这种方法没有考虑 Cache 块过去被使用的情况,反映不了程序的局部性,所以其失效率比 LRU 的高。
2. 先进先出法FIFO( First-In-First-Out)
这种方法选择最早调入的块作为被替换的块。其优点也是容易实现。它虽然利用了同一组中各块进入Cache的顺序这一“历史”信息,但还是不能正确地反映程序的局部性。因为最先进入的块,很可能是经常要用到的块。
3. 最近最少使用法LRU(Least Recently Used)
这种方法本来是指选择近期最少被访问的块作为被替换的块。但由于实现比较困难,现在实际上实现的 LRU 都只是选择最久没有被访问过的块作为被替换的块。这种方法所依据的是局部性原理的一个推论:如果最近刚用过的块很可能就是马上要再用到的块,则最久没用过的块就是最佳的被替换者。LRU 能较好地反映程序的局部性,因而其失效率在上述三种方法中是最低的。但是 LRU 比较复杂,硬件实现比较困难,特别是当组的大小增加时,LRU 的实现代价会越来越高,而且经常只是近似地实现。
LRU 和随机法分别因其失效率低和实现简单而被广泛采用。
4.2.4写策略
处理器对 Cache 的访问主要是读访问,因为所有对指令的访问都是“读”,而且大多数指令都不对存储器进行“写”。第二章中指出,DLX 程序的 Store 和 Load 指令所占的比例分别为9%和26%,由此可得“写”在所有访存操作中所占的比例为
9%/(100% + 26% + 9%) ≈ 7%,
而在访问数据 Cache 操作中所占的比例为
9%/(26% + 9%) ≈ 25%。
基于上述百分比,特别是考虑到处理器一般是对“读”要等待,而对“写”却不必等待,应该说设计 Cache 要针对最经常发生的“读”进行优化。然而,Amdahl定律告诉我们,高性能 Cache 的设计不能忽略“写”的速度。
幸运的是,最经常发生的“读”也是最容易提高速度的。访问 Cache 时,在读出标识进行比较的同时,可以把相应的 Cache 块也读出。如果命中,则把该块中所请求的数据立即送给 CPU;若为失效,则所读出的块没什么用处,但也没什么坏处,置之不理就是了。
然而,对于“写”却不是如此。只有在读出标识并进行比较,确认是命中后,才可对Cache块进行写入。由于检查标识不能与写入 Cache 块并行进行,“写”一般比“读”花费更多的时间。
按照存储层次的要求, Cache 内容应是主存部分内容的一个副本。但是“写”访问却有可能导致它们内容的不一致。例如,当处理机进行“写”访问,往 Cache 写入新的数据后,则 Cache 中相应单元的内容已发生变化,而主存中该单元的内容却仍然是原来的。这就产生了所谓的 Cache 与主存内容的一致性问题。显然,为了保证正确性,主存的内容也必须更新。至于何时更新,这正是写策略所要解决的问题。
写策略是区分不同 Cache 设计方案的一个重要标志。写策略主要有两种:
1. 写直达法
写直达法也称为存直达法。它是指在执行“写”操作时,不仅把信息写入 Cache 中相应的块,而且也写入下一级存储器中相应的块。
2. 写回法
写回法也称为拷回法。它只把信息写入 Cache 中相应的块。该块只有在被替换时,才被写回主存。
为了减少在替换时块的写回,常采用污染位标志。即为 Cache 中的每一块设置一个“污染位”(设在与该块相应的目录表项中),用于指出该块是“脏”的(被修改过)还是“干净”的(没被修改过)。替换时,若被替换的块是“干净”的,则不必写回下一级存储器,因为这时下一级存储器中相应块的内容与 Cache 中的一致。
写回法和写直达法各有特色。两者相比,写回法的优点是速度快,“写”操作能以 Cache 存储器的速度进行。而且对于同一单元的多个写最后只需一次写回下一级存储器,有些“写”只到达 Cache ,不到达主存,因而所使用的存储器频带较低。这使得写回法对于多处理机很有吸引力。写直达法的优点是易于实现,而且下一级存储器中的数据总是最新的。后一个优点对于 I/O 和多处理机来说是重要的。I/O 和多处理机经常难以在这两种方法之间选择:它们既想要用写回法来减少访存的次数,又想要用写直达法来保持 Cache 与下一级存储器的一致性。
采用写直达法时,若在进行“写”操作的过程中 CPU 必须等待,直到“写”操作结束,则称 CPU 写等待。减少写等待的一种常用的优化威廉希尔官方网站 是采用写缓冲器。 CPU 一旦把数据写入该缓冲器,就可以继续执行,从而使下一级存储器的更新和 CPU 的执行重叠起来。不过,在后面很快就会看到,即使有写缓冲器,也可能发生写等待。
由于“写”访问并不需要用到所访问单元中原有的数据。所以,当发生写失效时,是否调入相应的块,有两种选择:
(1) 按写分配法:写失效时,先把所写单元所在的块调入 Cache,然后再进行写入。这与读失效类似。这种方法也称为写时取方法。
(2) 不按写分配法:写失效时,直接写入下一级存储器而不将相应的块调入 Cache。这种方法也称为绕写法。
虽然上述两种方法都可应用于写直达法和写回法,写回法 Cache 一般采用按写分配法(这样,以后对那个块的“写”就能被 Cache 捕获)。而写直达法一般采用不按写分配法(因为以后对那个块的“写”仍然还要到达下一级存储器)。
非常好我支持^.^
(0) 0%
不好我反对
(42) 100%
相关阅读:
- [电子说] ARM9处理器从哪些方面保证了FIQ异常响应的快速性? 2023-10-19
- [电子说] Python 中怎么来实现类似 Cache 的功能 2023-10-17
- [电子说] Cache工作原理讲解 Cache写入方式原理简介 2023-10-17
- [电子说] 深入理解Armv9 DSU-110中的L3 cache 2023-10-11
- [电子说] 在组相联cache中,用于替换cache line的算法有哪些? 2023-10-08
- [电子说] Linux性能优化:Cache对性能的影响 2023-10-04
- [电子说] Linux内存泄漏该如何去检测呢? 2023-09-21
- [电子说] 如何在Rust中使用Memcached 2023-09-19
( 发表人:admin )